【NLP_Stanford课堂】语言模型1
一、语言模型
旨在:给一个句子或一组词计算一个联合概率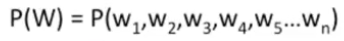
作用:
- 机器翻译:用以区分翻译结果的好坏
- 拼写校正:某一个拼错的单词是这个单词的概率更大,所以校正
- 语音识别:语音识别出来是这个句子的概率更大
- 总结或问答系统
相关任务:在原句子的基础上,计算一个新词的条件概率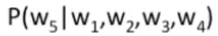 ,该概率与P(w1w2w3w4w5)息息相关。
,该概率与P(w1w2w3w4w5)息息相关。
任何一个模型计算以上两个概率的,我们都称之为语言模型LM。
二、如何计算概率
方法:依赖概率的链式规则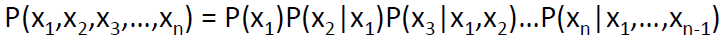
从而有:

问题:如何预估这些概率
方法一:计数和细分

但是不可能做到!
原因:句子数量过于庞大;永远不可能有足够的数据来预估这些(语料库永远不可能是完备的)
方法二:马尔可夫假设
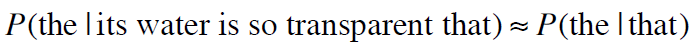
或者:
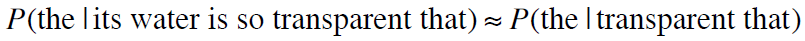
即:
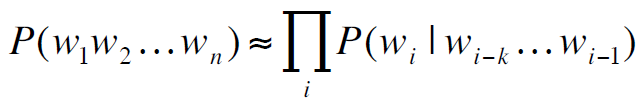
所以:
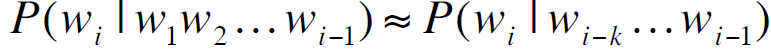
三、马尔可夫模型
1. Unigram model
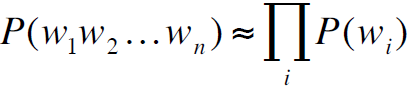
其假设词是相互独立的
2. Bigram model
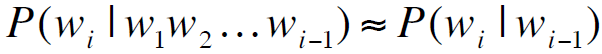
3. N-gram models
但是并不有效,因为语言本身存在长距离依存关系
比如"The computer which ......crashed" 单词crash本身其实是依赖于主语computer的,但是中间隔了一个很长的从句,在马尔可夫模型中就很难找到这样的依存关系
但是在实际应用中,发现N-gram可以一定程度上解决这个问题
四、预估N-gram概率
以bigram为例。
最大似然估计:
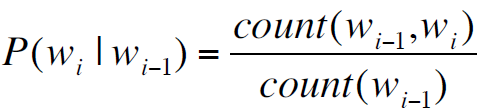 ,即,
,即,
分子表示wi紧跟着wi-1出现的计数,分母表示wi-1出现的计数
举例如下:
语料库: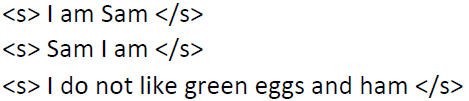
计算bigram概率:
结果: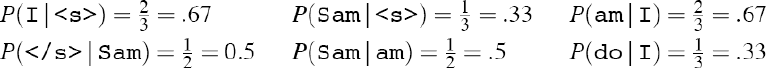
更复杂的举例如下:
一语料库中有9222个句子,这里我们只计数其中8个我们想要关注的单词
其中每个单词后面紧跟着的单词计数如下:
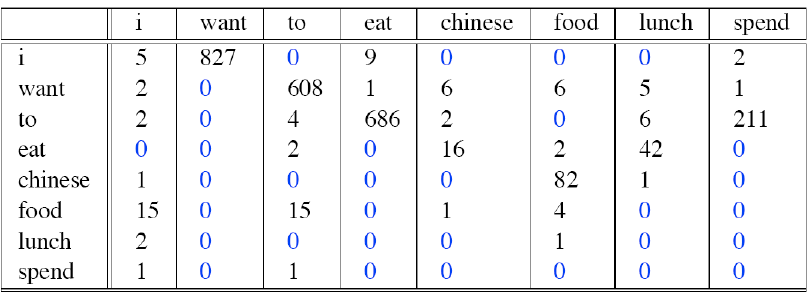
接下来我们需要做的是归一化:
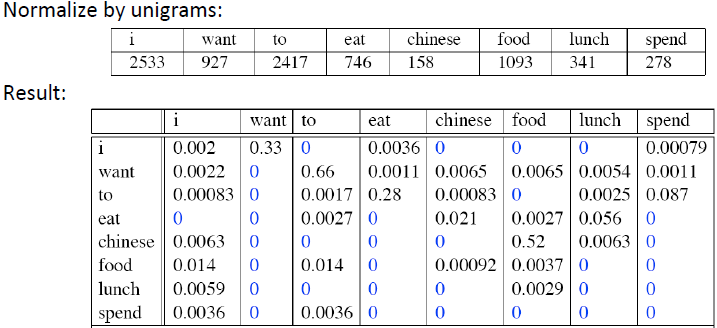
其中有些为0,是因为偶然性或者结构语法上的原因
在获得每个bigram之后,就可以预估一个句子的概率了
举例如下:

其中<s>是一个句子开始的标记,</s>是一个句子结束的标记
实际中,在计算概率时使用log,如下:
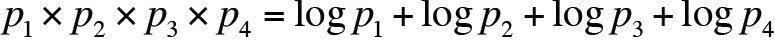
原因:
1. 避免计数下溢,多个小于0的数相乘之后可能得到的数会非常非常小,甚至接近于0
2. 使用log之后可以将乘法转换成加法,计算更快
其他语言模型:
- SRILM
- Google N-Grams
- Google Book N-Grams
【NLP_Stanford课堂】语言模型1的更多相关文章
- 【NLP_Stanford课堂】语言模型3
一.产生句子 方法:Shannon Visualization Method 过程:根据概率,每次随机选择一个bigram,从而来产生一个句子 比如: 从句子开始标志的bigram开始,我们先有一个( ...
- 【NLP_Stanford课堂】语言模型2
一.如何评价语言模型的好坏 标准:比起语法不通的.不太可能出现的句子,是否为“真实”或"比较可能出现的”句子分配更高的概率 过程:先在训练数据集上训练模型的参数,然后在测试数据集上测试模型的 ...
- 【NLP_Stanford课堂】语言模型4
平滑方法: 1. Add-1 smoothing 2. Add-k smoothing 设m=1/V,则有 从而每一项可以跟词汇表的大小相关 3. Unigram prior smoothing 将上 ...
- 【NLP_Stanford课堂】文本分类1
文本分类实例:分辨垃圾邮件.文章作者识别.作者性别识别.电影评论情感识别(积极或消极).文章主题识别及任何可分类的任务. 一.文本分类问题定义: 输入: 一个文本d 一个固定的类别集合C={c1,c2 ...
- 【NLP_Stanford课堂】拼写校正
在多种应用比如word中都有拼写检查和校正功能,具体步骤分为: 拼写错误检测 拼写错误校正: 自动校正:hte -> the 建议一个校正 建议多个校正 拼写错误类型: Non-word Err ...
- 【NLP_Stanford课堂】情感分析
一.简介 实例: 电影评论.产品评论是positive还是negative 公众.消费者的信心是否在增加 公众对于候选人.社会事件等的倾向 预测股票市场的涨跌 Affective States又分为: ...
- 【NLP_Stanford课堂】文本分类2
一.实验评估参数 实验数据本身可以分为是否属于某一个类(即correct和not correct),表示本身是否属于某一类别上,这是客观事实:又可以按照我们系统的输出是否属于某一个类(即selecte ...
- 【NLP_Stanford课堂】最小编辑距离
一.什么是最小编辑距离 最小编辑距离:是用以衡量两个字符串之间的相似度,是两个字符串之间的最小操作数,即从一个字符转换成另一个字符所需要的操作数,包括插入.删除和置换. 每个操作数的cost: 每个操 ...
- 【NLP_Stanford课堂】句子切分
依照什么切分句子——标点符号 无歧义的:!?等 存在歧义的:. 英文中的.不止表示句号,也可能出现在句子中间,比如缩写Dr. 或者数字里的小数点4.3 解决方法:建立一个二元分类器: 检查“.” 判断 ...
随机推荐
- Odd number problem
描述 你一定玩过八数码游戏,它实际上是在一个3*3的网格中进行的,1个空格和1~8这8个数字恰好不重不漏地分布在这3*3的网格中.例如:5 2 81 3 _4 6 7在游戏过程中,可以把空格与其上.下 ...
- [水题AC乐] - 贪心
HDU - 1009 https://paste.ubuntu.com/p/rgSYpSKkwW/ POJ - 1017 麻烦的模拟 贪心 题意就是用尽量少的66h箱子装nnh的物品,贪心策略很明显, ...
- ZOJ - 3632 DP 单调优化
题意:买瓜,每天的瓜有不同的价格和xu命时间,要求能苟到第n天的最小代价 定义DP方程\(dp[i]\),指苟到第\(i\)天的最小代价,所求即为\(dp[n]\) 那么怎么转移就是问题,这里的状态表 ...
- web 页面 验证码 实现
1. 前台页面代码: 页面刷新时会自动请求 ${pageContext.request.contextPath}/yanzheng?yz=&time=-1111 这个action <f ...
- Phyton自定义包导入。
说明:同一个项目下的自定义包. 项目层次: 1:先建好项目Pybasestudty 2:建Python package,包名:pytestpk,__init__.py是建包时自动产生的文件. 3:在该 ...
- PIXI 精灵及文本加载(4)
预习下官网的知识. 及字母消除接上文 Pixi 精灵 Pixi拥有一个精灵类来创建游戏精灵.有三种主要的方法来创建它: 用一个单图像文件创建. 用一个 雪碧图 来创建.雪碧图是一个放入了你游戏所需的所 ...
- Json 序列化为Dictionary
如下所示的json字符串中包含中文属性转换成英文属性 ["sid":"dd1312","success":true,"data&q ...
- 智能手表ticwatch穿戴体验
前言 可穿戴设备近几年越来越火,最开始是谷歌眼睛.手环,再到手表.VR眼镜,相信未来几年这片领域依旧火热~ 自从谷歌发布Android Wear.苹果发布Apple Watch之后,智能手表的战役就正 ...
- (转)Linux磁盘空间监控告警 && Linux磁盘管理
Linux磁盘空间监控告警 http://blog.csdn.net/github_39069288/article/details/73478784-----------Linux磁盘管理 原文:h ...
- 详解http之post
详解http之post 首先,我们先看看jquery中的post方法的使用: $.ajax({ url:'api/bbg/goods/get_goods_list_wechat', data:{ , ...