【NLP_Stanford课堂】语言模型1
一、语言模型
旨在:给一个句子或一组词计算一个联合概率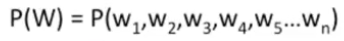
作用:
- 机器翻译:用以区分翻译结果的好坏
- 拼写校正:某一个拼错的单词是这个单词的概率更大,所以校正
- 语音识别:语音识别出来是这个句子的概率更大
- 总结或问答系统
相关任务:在原句子的基础上,计算一个新词的条件概率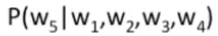 ,该概率与P(w1w2w3w4w5)息息相关。
,该概率与P(w1w2w3w4w5)息息相关。
任何一个模型计算以上两个概率的,我们都称之为语言模型LM。
二、如何计算概率
方法:依赖概率的链式规则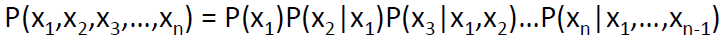
从而有:

问题:如何预估这些概率
方法一:计数和细分

但是不可能做到!
原因:句子数量过于庞大;永远不可能有足够的数据来预估这些(语料库永远不可能是完备的)
方法二:马尔可夫假设
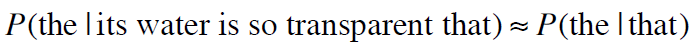
或者:
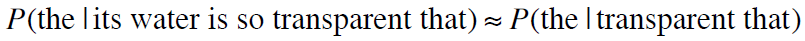
即:
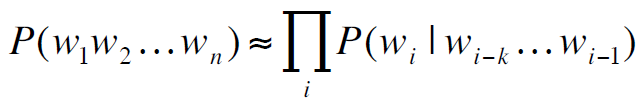
所以:
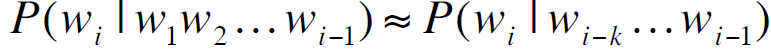
三、马尔可夫模型
1. Unigram model
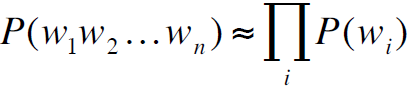
其假设词是相互独立的
2. Bigram model
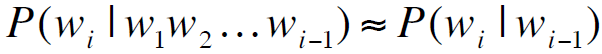
3. N-gram models
但是并不有效,因为语言本身存在长距离依存关系
比如"The computer which ......crashed" 单词crash本身其实是依赖于主语computer的,但是中间隔了一个很长的从句,在马尔可夫模型中就很难找到这样的依存关系
但是在实际应用中,发现N-gram可以一定程度上解决这个问题
四、预估N-gram概率
以bigram为例。
最大似然估计:
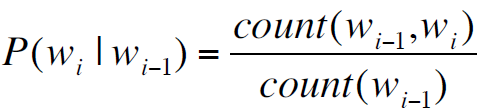 ,即,
,即,
分子表示wi紧跟着wi-1出现的计数,分母表示wi-1出现的计数
举例如下:
语料库: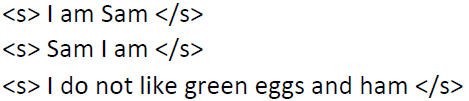
计算bigram概率:
结果: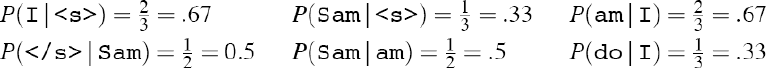
更复杂的举例如下:
一语料库中有9222个句子,这里我们只计数其中8个我们想要关注的单词
其中每个单词后面紧跟着的单词计数如下:
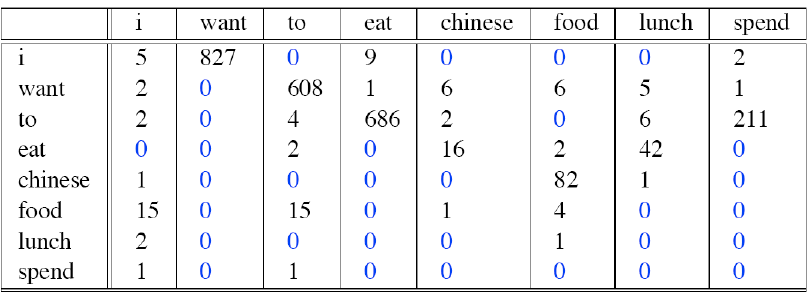
接下来我们需要做的是归一化:
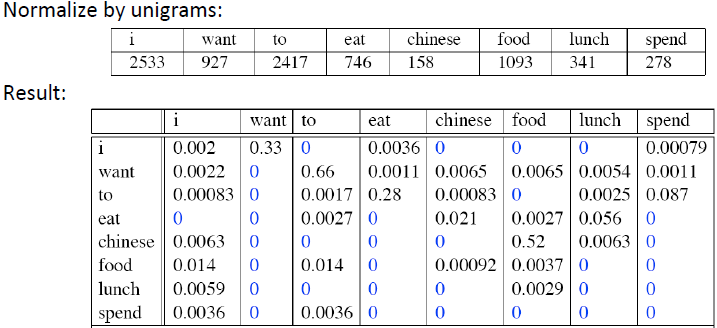
其中有些为0,是因为偶然性或者结构语法上的原因
在获得每个bigram之后,就可以预估一个句子的概率了
举例如下:

其中<s>是一个句子开始的标记,</s>是一个句子结束的标记
实际中,在计算概率时使用log,如下:
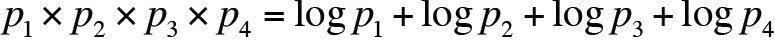
原因:
1. 避免计数下溢,多个小于0的数相乘之后可能得到的数会非常非常小,甚至接近于0
2. 使用log之后可以将乘法转换成加法,计算更快
其他语言模型:
- SRILM
- Google N-Grams
- Google Book N-Grams
【NLP_Stanford课堂】语言模型1的更多相关文章
- 【NLP_Stanford课堂】语言模型3
一.产生句子 方法:Shannon Visualization Method 过程:根据概率,每次随机选择一个bigram,从而来产生一个句子 比如: 从句子开始标志的bigram开始,我们先有一个( ...
- 【NLP_Stanford课堂】语言模型2
一.如何评价语言模型的好坏 标准:比起语法不通的.不太可能出现的句子,是否为“真实”或"比较可能出现的”句子分配更高的概率 过程:先在训练数据集上训练模型的参数,然后在测试数据集上测试模型的 ...
- 【NLP_Stanford课堂】语言模型4
平滑方法: 1. Add-1 smoothing 2. Add-k smoothing 设m=1/V,则有 从而每一项可以跟词汇表的大小相关 3. Unigram prior smoothing 将上 ...
- 【NLP_Stanford课堂】文本分类1
文本分类实例:分辨垃圾邮件.文章作者识别.作者性别识别.电影评论情感识别(积极或消极).文章主题识别及任何可分类的任务. 一.文本分类问题定义: 输入: 一个文本d 一个固定的类别集合C={c1,c2 ...
- 【NLP_Stanford课堂】拼写校正
在多种应用比如word中都有拼写检查和校正功能,具体步骤分为: 拼写错误检测 拼写错误校正: 自动校正:hte -> the 建议一个校正 建议多个校正 拼写错误类型: Non-word Err ...
- 【NLP_Stanford课堂】情感分析
一.简介 实例: 电影评论.产品评论是positive还是negative 公众.消费者的信心是否在增加 公众对于候选人.社会事件等的倾向 预测股票市场的涨跌 Affective States又分为: ...
- 【NLP_Stanford课堂】文本分类2
一.实验评估参数 实验数据本身可以分为是否属于某一个类(即correct和not correct),表示本身是否属于某一类别上,这是客观事实:又可以按照我们系统的输出是否属于某一个类(即selecte ...
- 【NLP_Stanford课堂】最小编辑距离
一.什么是最小编辑距离 最小编辑距离:是用以衡量两个字符串之间的相似度,是两个字符串之间的最小操作数,即从一个字符转换成另一个字符所需要的操作数,包括插入.删除和置换. 每个操作数的cost: 每个操 ...
- 【NLP_Stanford课堂】句子切分
依照什么切分句子——标点符号 无歧义的:!?等 存在歧义的:. 英文中的.不止表示句号,也可能出现在句子中间,比如缩写Dr. 或者数字里的小数点4.3 解决方法:建立一个二元分类器: 检查“.” 判断 ...
随机推荐
- rest-assured的默认值与Specification重用
一.默认值 rest-assured发起请求时,默认使用的host为localhost,端口为8080,如果你想使用不同的端口,你可以这样做: given().port(80)...... 或者是简单 ...
- docker load error: open /var/lib/docker/tmp/docker-import-347673752/bin/json: no such file or directory
docker save 对应 docker load docker export 对应 docker import 在导出的包的环境中的docker版本跟需要导入的环境中的docker版本不一致也可能 ...
- C# .Net正则表达式去除HTML标记和空格
C# .Net正则表达式去除HTML标记和空格 http://www.cnblogs.com/deerchao/archive/2006/08/24/zhengzhe30fengzhongjiaoch ...
- codeforces 1072D Minimum path bfs+剪枝 好题
题目传送门 题目大意: 给出一幅n*n的字符,从1,1位置走到n,n,会得到一个字符串,你有k次机会改变某一个字符(变成a),求字典序最小的路径. 题解: (先吐槽一句,cf 标签是dfs题????) ...
- centos7安装SourceCodePro字体
1. 下载SourceCodePro字体,后缀应为.ttf. 2. 将字体文件复制到fonts(/usr/share/fonts)文件夹下: [root@centos fonts]# mv /home ...
- redis 网络架构
https://blog.csdn.net/simplemurrina/article/details/53890542 GDB redis https://gitbook.cn/gitchat/c ...
- 个人笔记——Android网络技术
一.WebView 的用法 Android 提供WebView 的用法,可以在自己的应用程序里嵌入一个浏览器 webView.getSettings().setJavaScriptEnabled(tr ...
- org.hibernate.QueryException: duplicate alias: r hibernate别名重复问题解决
今天做项目的过程中发现,多表查询的时候如果使用hibernate的DetachedCriteria离线查询方式的时候, 在多表关联的时候我们需要使用别名的方式去实现. 但是代码运行的过程中抛出了下面的 ...
- 温故而知新,再探ConcurrentHashMap
这里说的还是1.7的ConcurrentHashMap,在1.8中,ConcurrentHashMap已经不是基于segments实现了. 之前也知道ConcurrentHashMap是通过把锁加载各 ...
- 资料收集:学习 Linux/*BSD/Unix 的 30 个最佳在线文档
文章转自:https://linux.cn/article-10311-1.html 手册页(man)是由系统管理员和 IT 技术开发人员写的,更多的是为了作为参考而不是教你如何使用.手册页对于已经熟 ...