14-SQLServer索引碎片
一、总结
1、数据库的存储本身是无序的,建立聚集索引之后,就会按照聚集索引的物理顺序存入硬盘;
2、建立索引完全是为了提升读取的速度,相对写入的速度就会降低,没有索引的表写入时最快的,但是大多数系统读的频率要高于写的频率;
3、索引碎片分为内部碎片和外部碎片。
内部碎片:是指索引页没有100%存储满,有剩余空间,这就是内部碎片;产生原因是在insert或者update数据时,该页不足以放下新增或更新的数据,造成分页,导致索引页的平均密度变小,就产生了内部碎片;
外部碎片:是指做插入或更新操作时,原来页无法容纳新的行,导致分页(分页会将原来页大约一半的数据放到新页上,达到一个平衡状态),而新的页和原来的页在物理上又不连续了(分页之前,他们之间有好多页面),而聚集索引要求行之前是连续的,所以分页后,新叶和原来页物理上的不连续是造成外部碎片的原因。
4、修改填充因子,也有可能解决索引碎片的问题,一千万的数据量修改填充因子用了1分钟(只是测试,表没有做删除的操作);
5、索引碎片查出的记录数(record_count)与直接select count(*)查出的数据量可能不一样,具体解释参考下面对字段意思的解释处;
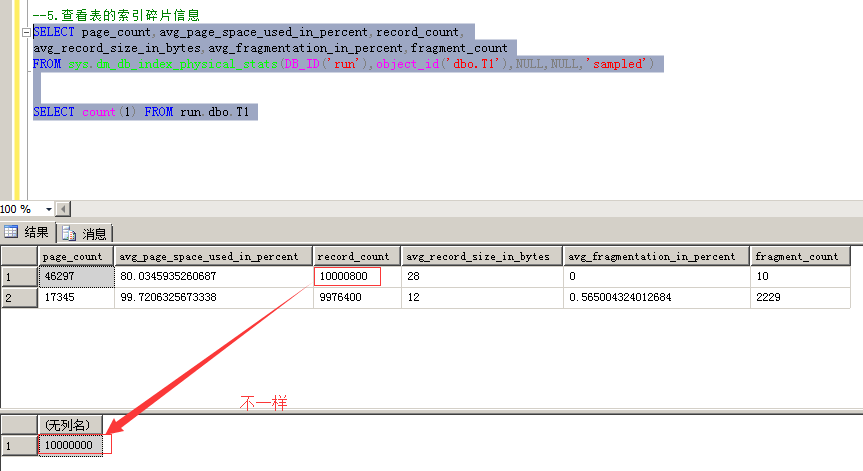
7.如果数据库里有批量数据的删除,导致avg_page_space_used_in_percent页的百分比变小,产生了碎片,这个时候可以通过收缩数据文件来增大页百分比,释放更多的空间(已测试过,但是做数据文件的收缩要慎重)
二、具体SQL操作
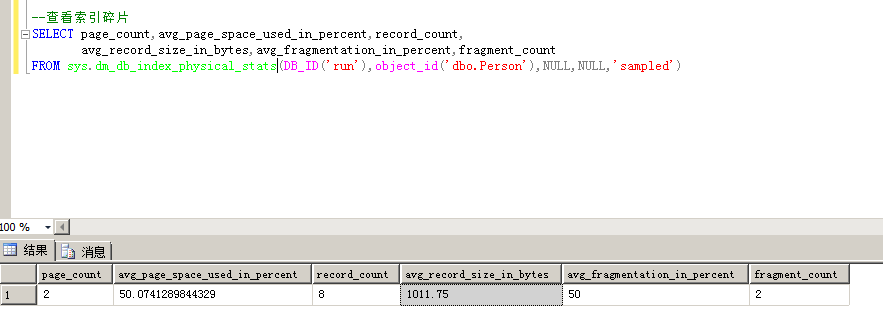
1.查看索引碎片
命令:SELECT page_count,avg_page_space_used_in_percent,record_count,
avg_record_size_in_bytes,avg_fragmentation_in_percent,fragment_count
FROM sys.dm_db_index_physical_stats(DB_ID('run'),object_id('dbo.Person'),NULL,NULL,'sampled')
page_count:索引或数据页的总数
avg_page_space_used_in_percent:平均数据页面使用空间的百分比
record_count:记录数,该数可能与对表查询select count(*)查出的结果值不一样,这是因为一行可能包含多个记录,比如LOB字段或可变长度的数据等等,详情参考官方解释
avg_record_size_in_bytes:平均每条记录数的大小(字节)
avg_fragmentation_in_percent:索引的逻辑碎片,按百分比计算,值越小表示碎片越少,平均每个区的剩余空间(也就是碎片的百分比)
fragment_count:叶级别中的碎片数(外部碎片的数量),也有可能是小的表保存在混合区上
官方参考地址:https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008-r2/ms188917%28v%3dsql.105%29
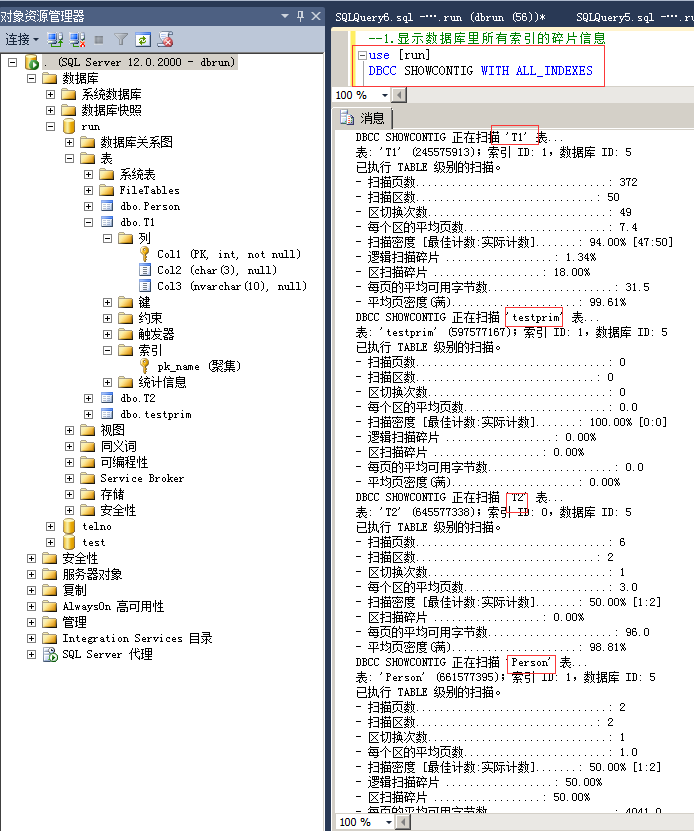
2.显示数据库里所有索引的碎片信息
命令:
use [run]
DBCC SHOWCONTIG WITH ALL_INDEXES
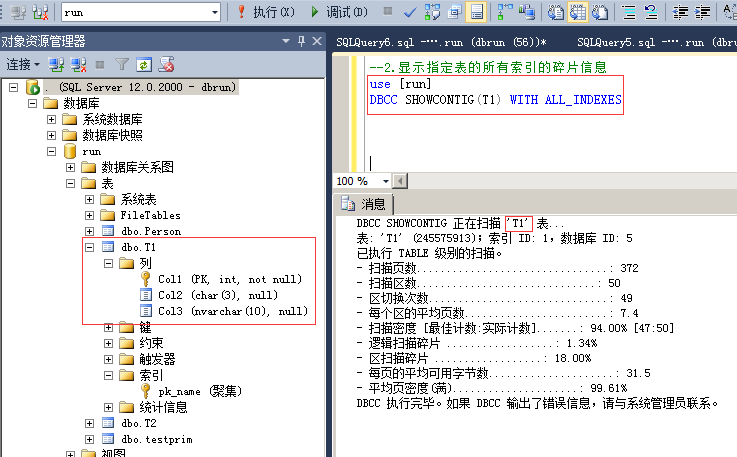
3.显示指定表的所有索引的碎片信息
命令:
use [run]
DBCC SHOWCONTIG(T1) WITH ALL_INDEXES
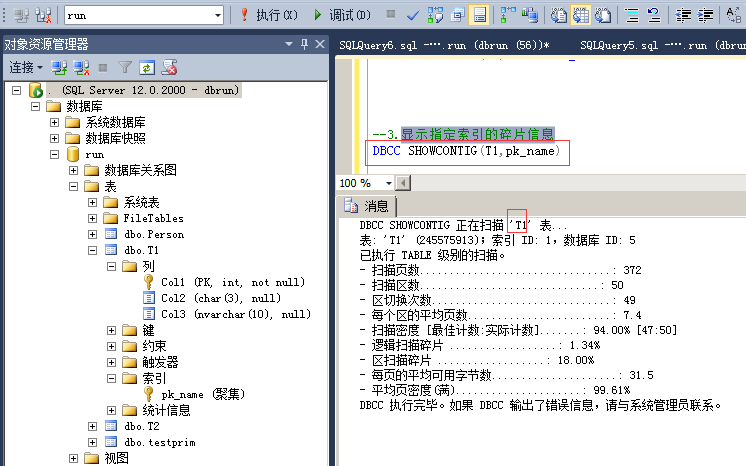
4.显示指定索引的碎片信息
命令:
DBCC SHOWCONTIG(T1,pk_name)
查出结果的解释:
扫描页数:该表的数据存储的页数;
扫描区数:一个区有8页,用扫描页数除以8可以得出估计的区数,如果扫描出的区数比你算出的要多,说明存在外部碎片,比算出的值高的多,说明外部碎片越多(如果数据量少的话不能作为参考值,比如扫面页数少于8页,就可能是存储在混合区里,不是单独给该表分配的区);
扫描密度:最佳值:实际值,该比值应该尽可能接近100%,低了说明有外部碎片;
逻辑扫描碎片:无序页的百分比,该比值应该在0%到10%之间,高了则说明有外部碎片;
区扫描碎片:无序扩展盘区在扫面索引叶级页中所占的百分比。该百分比高,说明有外部碎片;
每页的平均可用字节数:每页还剩余的空间,剩的越多说明有内部碎片,这个值要参考是否有设置填充因子,默认填充因子是0,就是页100%填充数据,如果填充因子是80%,就表示只填充80%的数据,剩下的20%留着给insert和update使用,以防做插入和更新时出现分页的情况。
平均密度:每页上数据量的密度,该值越高,表示每页填充的越满,值越低,表示每页上剩余空间越多,内部碎片越多。这个是相对的,要看系统读写比例,密度越低,页上剩余的空间大,插入更新数据时的性能就会越好(不会造成分页);相反密度越高,页上剩余空间小,插入更新数据时可能会造成分页,性能就会低,相反查询的性能就会好,因为扫描的页少,跨区扫描页少,所以查询性能会好;
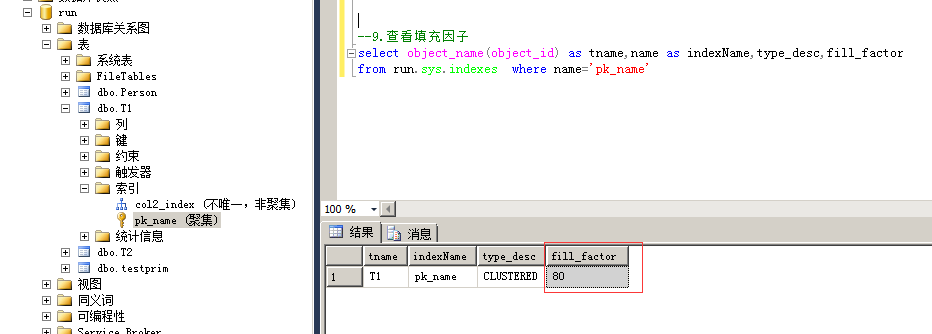
5、查看索引的填充因子
命令:
select object_name(object_id) as tname,name as indexName,type_desc,fill_factor
from run.sys.indexes where name='pk_name'
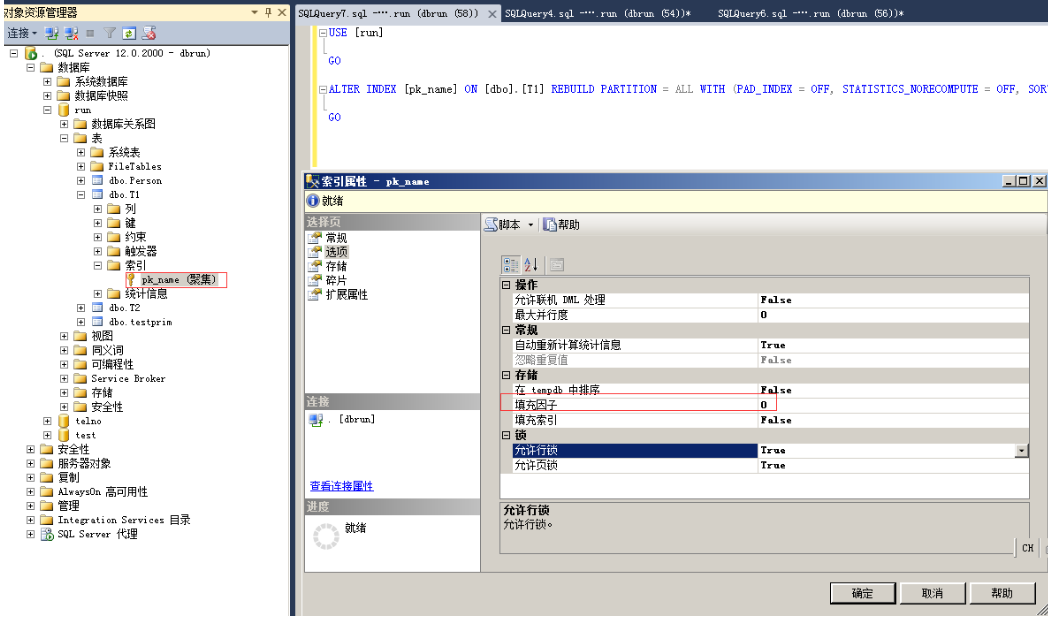
6.修改索引的填充因子
注:也是在图形化页面修改,也可以生成脚本
命令:alter index pk_name on dbo.T1 rebuild with (fillfactor=80)
7、打开IO统计,查看查询读取磁盘的IO次数
命令:
set statistics io on
select top 100 col2 from run.dbo.T1 where col2='99'
set statistics io off

三、索引碎片的解决办法
1、删除索引重新创建
这种操作会造成阻塞,会导致非聚集索引重建2次(删除重建,建立重建),数据量大的情况下耗时非常长,生产环境不建议这么做。
2.使用drop_existing语句重建索引
该方法可以避免重建2次索引,因为该语句是原子性的,不会导致非聚集索引重建2次,但同样会造成阻塞。
该方法可以重新创建使用约束的索引(如:唯一性约束)
命令:create unique clustered index pk_name on T1(Col1) with (drop_existing=on)
3.使用alter index rebuild语句重建索引
该种方式也是重建索引,但是是动态重建索引而不是卸载在重新重建,但是依旧会造成阻塞;
可以通过online关键字减少锁,但是会造成重建时间加长;
原子性操作,中途终止会事务回滚;
命令:
alter index pk_name on T1 rebuild
alter index pk_name on T1 rebuild with (online=on)
alter index all on T1 rebuild with (online=on) --在线重建所有索引
4.使用alter index reorganize整理索引页
该种方式不会重建索引,也不会生成新的页,仅仅是整理叶级数据,不涉及非叶级节点,当遇到加锁的页时跳过,所以不会造成阻塞,但整理效果会比前3种差。
重整索引不会锁定任何对象,它仅仅是优化当前的B树的叶子节点。
命令:
alter index pk_name on T1 reorganize --重整pk_name索引
alter index all on T1 reorganize --重整所有索引
14-SQLServer索引碎片的更多相关文章
- SqlServer索引碎片
1.产生碎片的操作 通过sys.dm_index_physical_stats来查看,索引上的页不在具有连续性时就会产生碎片,碎片是索引上页拆分的物理结果. (1).插入操作: INSERT操作在聚集 ...
- SQL Server性能优化(14)索引碎片
一. 外部碎片和内部碎片的概念 碎片的概念和检测,参考MSDN:https://msdn.microsoft.com/zh-cn/library/ms189858.aspx 二.对于碎片的解决办法 解 ...
- mssql sqlserver 索引专题
摘要: 下文将详细讲述sql server 索引的相关知识,如下所示: 实验环境: sql server 2008 R2 sqlserver索引简介: mssql sqlsever 索引分类简介 ms ...
- SQLServer中重建聚集索引之后会影响到非聚集索引的索引碎片吗
本文出处:http://www.cnblogs.com/wy123/p/7650215.html (保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错 ...
- SqlServer 如何知道是否发生了索引碎片
--如何知道是否发生了索引碎片 SELECT object_name(dt.object_id) Tablename,si.name IndexName,dt.avg_fragmentation_in ...
- SQLServer 数据库索引碎片
--改成当前库 use DB_Name --创建变量 指定要查看的表 declare @table_id int set @table_id=object_id('TableName') --执行 d ...
- sqlserver索引小结
1.1 什么是索引? SQL索引有两种,聚集索引和非聚集索引,索引主要目的是提高了SQL Server系统的性能,加快数据的查询速度与减少系统的响应时间 下面举两个简单的例子: 图书馆的例子:一个图书 ...
- SQL Server2005索引碎片分析和解决方法
SQL Server2005索引碎片分析和解决方法 本文作者(郑贤娴),请您在阅读本文时尊重作者版权. 摘要: SQL Server,为了反应数据的更新,需要维护表上的索引,因而这些索引会形成碎片.根 ...
- 转: SQL Server索引的维护 - 索引碎片、填充因子
转:http://www.cnblogs.com/kissdodog/archive/2013/06/14/3135412.html 实际上,索引的维护主要包括以下两个方面: 页拆分 碎片 这两个问题 ...
- 转:sql server索引碎片和解决方法
毫无疑问,给表添加索引是有好处的,你要做的大部分工作就是维护索引,在数据更改期间索引可能产生碎片,所以一些维护是必要的.碎片可能是你查询产生性能问题的来源. 那么到底什么是索引碎片呢?索引碎片实际上有 ...
随机推荐
- 移动端1px的边框
我们知道,在移动端存在物理像素(physical pixel)和设备独立像素(density-independent pixel)的概念.物理像素也称为设备像素,它是显示设备中一个最微小的物理部件,每 ...
- delphi 相关好的资料网站
1.Delphi编程技巧大全 http://www.delphitop.com/ (实例讲解所有组件) 2.Delphi学习大师 Delphi基础教程 视频教程 http://www.xue ...
- SqlException 服务器主体无法在当前安全上下文下访问数据库
遇到一个错误如下 System.Data.SqlClient.SqlException HResult=0x80131904 Message=服务器主体 "用户名" 无法在当前 ...
- Spring4学习回顾之路05—自动装配,Bean的继承,依赖和作用域
自动装配 xml配置里的Bean的自动装配,Spring IOC容器可以自动装配Bean,仅仅需要做的是在<bean>标签里的autowire属性里指定自动装配的模式. ①byType(根 ...
- VUE前后台分离
VUE前后台分离 配置js环境 jQuery >: cnpm install jquery vue/cli 3 配置jQuery:在vue.config.js中配置(没有,手动项目根目录下新建) ...
- peewee无外键连接
# 参考:https://blog.csdn.net/weixin_34273479/article/details/87587183 res = Name.select(Name, User.xxx ...
- 简单的pycharm使用秘籍视频
ttp://edu.51cto.com/center/course/lesson/index?id=163794 这个免费视频是我自己找的别人的,一些常用的基本上都还有,所以说善用百度之类的搜索引擎很 ...
- 你不知道的css各类布局(四)之响应式布局
响应式布局 概念 响应式布局指的是同一页面在不同屏幕尺寸下有不同的布局 布局特点 响应式设计的目标是确保一个页面在所有终端上(各种尺寸的PC.手机.手表.冰箱的Web浏览器等等)都能显示出令人满意的效 ...
- python之字符串类型及其操作
1.1字符串类型的表示 字符串是字符的序列表示,可以由一对单引号('). 双引号(")或三引号(’")构成.其中,单引号和双引号都可以表示单行字符串,两者作用相同.使用单引号时,双 ...
- CSS3--transform相关属性
---transform属性使用--- 1.过度时间 :transition: transform 2s; 2.transform: 应用 2D 或 3D 转换.可以对元素进行旋转.缩放.移动或倾斜. ...