requests库爬取豆瓣热门国产电视剧数据并保存到本地
首先要做的就是去豆瓣网找对应的接口,这里就不赘述了,谷歌浏览器抓包即可,然后要做的就是分析返回的json数据的结构:
这是接口地址,可以大概的分析一下各个参数的规则:
- type=tv,表示的是电视剧的分类
- tag=国产剧,表示是国产剧的分类
- sort参数,这里猜测是一个排序方式
- page_limit=20,这个一定就是每页所存取的数据数量了
- page_start=0,表示的是这页从哪条数据开始,比如第二页就为page_start=20,第三页为page_start=40,以此类推
- 最终我们要用到的主要是page_start和page_limit两个参数
下面这里是返回的json数据格式,可以看出我们要的是json中subjects列表中的每条数据,在之后的程序中会把每一个电视剧的信息保存到文件里的一行

有了这些,就直接上程序了,因为感觉程序还是比较好懂,主要还是遵从面向对象的程序设计:
import json
import requests class DoubanSpider(object):
"""爬取豆瓣热门国产电视剧的数据并保存到本地""" def __init__(self):
# url_temp中的start的值是动态的,所以这里用{}替换,方便后面使用format方法
self.url_temp = 'https://movie.douban.com/j/search_subjects?type=tv&tag=%E5%9B%BD%E4%BA%A7%E5%89%A7&sort=recommend&page_limit=20&page_start={}'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
} def pass_url(self, url): # 发送请求,获取响应
print(url)
response = requests.get(url, headers=self.headers)
return response.content.decode() def get_content_list(self, json_str): # 提取数据
dict_ret = json.loads(json_str)
content_list = dict_ret['subjects']
return content_list def save_content_list(self, content_list): # 保存
with open('douban.txt', 'a', encoding='utf-8') as f:
for content in content_list:
f.write(json.dumps(content, ensure_ascii=False)) # 一部电视剧的信息一行
f.write('\n') # 写入换行符进行换行
print('保存成功!') def run(self): # 实现主要逻辑
num = 0
while True:
# 1. start_url
url = self.url_temp.format(num)
# 2. 发送请求,获取响应
json_str = self.pass_url(url)
# 3. 提取数据
content_list = self.get_content_list(json_str)
# 4. 保存
self.save_content_list(content_list)
if len(content_list) < 20:
break
# 5. 构造下一页url地址,进入循环
num += 20 # 每一页有二十条数据 if __name__ == '__main__':
douban_spider = DoubanSpider()
douban_spider.run()
上面是利用循环遍历每一页,后来我又想到用递归也可以,虽然递归效率可能不高,这里还是展示一下,只需要改几个地方而已:
import json
import requests class DoubanSpider(object):
"""爬取豆瓣热门国产电视剧的数据并保存到本地"""
def __init__(self):
# url_temp中的start的值是动态的,所以这里用{}替换,方便后面使用format方法
self.url_temp = 'https://movie.douban.com/j/search_subjects?type=tv&tag=%E5%9B%BD%E4%BA%A7%E5%89%A7&sort=recommend&page_limit=20&page_start={}'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}
self.num = 0 def pass_url(self, url): # 发送请求,获取响应
print(url)
response = requests.get(url, headers=self.headers)
return response.content.decode() def get_content_list(self, json_str): # 提取数据
dict_ret = json.loads(json_str)
content_list = dict_ret['subjects']
return content_list def save_content_list(self, content_list): # 保存
with open('douban2.txt', 'a', encoding='utf-8') as f:
for content in content_list:
f.write(json.dumps(content, ensure_ascii=False)) # 一部电视剧的信息一行
f.write('\n') # 写入换行符进行换行
print('保存成功!') def run(self): # 实现主要逻辑
# 1. start_url
url = self.url_temp.format(self.num)
# 2. 发送请求,获取响应
json_str = self.pass_url(url)
# 3. 提取数据
content_list = self.get_content_list(json_str)
# 4. 保存
self.save_content_list(content_list)
# 5. 构造下一页url地址,进入循环
if len(content_list) == 20:
self.num += 20 # 每一页有二十条数据
self.run() if __name__ == '__main__':
douban_spider = DoubanSpider()
douban_spider.run()
最终文件得到的结果:
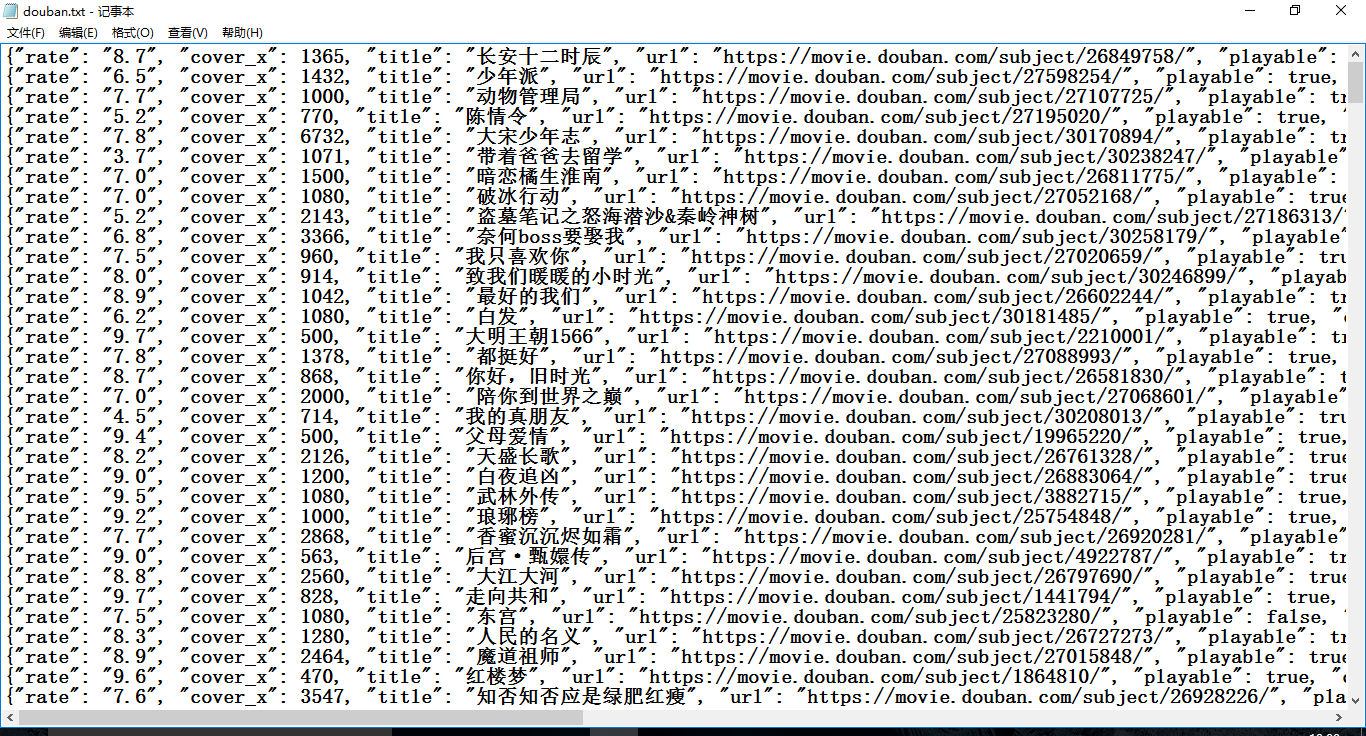
requests库爬取豆瓣热门国产电视剧数据并保存到本地的更多相关文章
- python--爬取豆瓣热门国产电视剧保存为文件
# -*- coding: utf-8 -*- __author__ = 'Frank Li' import requests import json class HotSpider(object): ...
- requests+正则爬取豆瓣图书
#requests+正则爬取豆瓣图书 import requests import re def get_html(url): headers = {'User-Agent':'Mozilla/5.0 ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- scrapy爬取校花网男神图片保存到本地
爬虫四部曲,本人按自己的步骤来写,可能有很多漏洞,望各位大神指点指点 1.创建项目 scrapy startproject xiaohuawang scrapy.cfg: 项目的配置文件xiaohua ...
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
- 【Python成长之路】Python爬虫 --requests库爬取网站乱码(\xe4\xb8\xb0\xe5\xa)的解决方法【华为云分享】
[写在前面] 在用requests库对自己的CSDN个人博客(https://blog.csdn.net/yuzipeng)进行爬取时,发现乱码报错(\xe4\xb8\xb0\xe5\xaf\x8c\ ...
- requests库爬取猫眼电影“最受期待榜”榜单 --网络爬虫
目标站点:https://maoyan.com/board/6 # coding:utf8 import requests, re, json from requests.exceptions imp ...
- requests库/爬取zhihu表情包
先学了requests库的一些基本操作,简单的爬了一下. 用到了requests.get()方法,就是以GET方式请求网页,得到一个Response对象.不加headers的话可能会400error所 ...
- python requests库爬取网页小实例:ip地址查询
ip地址查询的全代码: 智力使用ip183网站进行ip地址归属地的查询,我们在查询的过程是通过构造url进行查询的,将要查询的ip地址以参数的形式添加在ip183url后面即可. #ip地址查询的全代 ...
随机推荐
- luogu4212
P4212 外太空旅行 题目描述 在人类的触角伸向银河系的边缘之际,普通人上太空旅行已经变得稀松平常了.某理科试验班有n个人,现在班主任要从中选出尽量多的人去参加一次太空旅行活动. 可是n名同学并不是 ...
- 用Python操作excel文档
使用Python第三方库 这一节我们学习如何使用Python去操作Excel文档.如果大家有人不知道Excel的话,那么建议先学一学office办公基础.这里想要操作Excel,必须安装一个Pytho ...
- [spring cloud] [error] java.lang.IllegalStateException: Only one connection receive subscriber allowed.
前言 最近在开发api-gateway的时候遇到了一个问题,网上能够找到的解决方案也很少,之后由公司的大佬解决了这个问题.写下这篇文章记录一下解决方案.希望可以帮助到更多的人. 环境 java版本:8 ...
- Java 注解指导手册(上)
编者的话:注解是java的一个主要特性且每个java开发者都应该知道如何使用它. 我们已经在Java Code Geeks提供了丰富的教程, 如Creating Your Own Java A ...
- 域名与服务器 ip地址的理解
域名 服务器 ip地址具有怎样的关系呢 通俗的讲,我们访问一个网站就相当于访问一个服务器的文件,如果想要通过自己的域名来访问一个网站,首先得将域名部署到你的服务器上,然后就可以通过域名访问到你服务器上 ...
- How to Fix Grub error: no such partition Grub Rescue
错误信息: error: no such partition Entering rescue mode... grub rescue> _ 错误原因: grub找不到文件normal.mod 解 ...
- pandas.DataFrame 中的insert(), pop()
pandas.DataFrame 中的insert(), pop() 在pandas中,del.drop和pop方法都可以用来删除数据,insert可以在指定位置插入数据. 可以看看以下示例. imp ...
- VI快捷键速记
enjoy :P
- 使用微软易升安装纯净版win10
1.打开官方网址 https://www.microsoft.com/zh-cn/software-download/windows10 2.下载工具 3.根据你的需求,我这里是给另外以外机器安装,一 ...
- 使用 certbot 自动给 nginx 加上 https
概述 目前,Let's Encrypt 可以算是最好用的 https 证书申请网站了吧.而 certbot 可以算是它的客户端,能够很方便的自动生成 https 证书.我把自己的使用经历记录下来,供以 ...