Spark学习笔记——读写Hbase
1.首先在Hbase中建立一张表,名字为student
一个cell的值,取决于Row,Column family,Column Qualifier和Timestamp
Hbase表结构

2.往Hbase中写入数据,写入的时候,需要写family和column
build.sbt
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "2.1.0",
"mysql" % "mysql-connector-java" % "5.1.31",
"org.apache.spark" %% "spark-sql" % "2.1.0",
"org.apache.hbase" % "hbase-common" % "1.3.0",
"org.apache.hbase" % "hbase-client" % "1.3.0",
"org.apache.hbase" % "hbase-server" % "1.3.0",
"org.apache.hbase" % "hbase" % "1.2.1"
)
在hbaseshell中写数据的时候,写的是String,但是在idea中写代码的话,如果写的是int类型的,就会出现\x00...的情况
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql._
import java.util.Properties
import com.google.common.collect.Lists
import org.apache.spark.sql.types.{ArrayType, StringType, StructField, StructType}
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.{Get, Put, Result, Scan}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapred.TableOutputFormat
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapred.JobConf
/**
* Created by mi on 17-4-11.
*/
case class resultset(name: String,
info: String,
summary: String)
case class IntroItem(name: String, value: String)
case class BaikeLocation(name: String,
url: String = "",
info: Seq[IntroItem] = Seq(),
summary: Option[String] = None)
case class MewBaikeLocation(name: String,
url: String = "",
info: Option[String] = None,
summary: Option[String] = None)
object MysqlOpt {
def main(args: Array[String]): Unit = {
// 本地模式运行,便于测试
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
// 创建 spark context
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
//定义数据库和表信息
val url = "jdbc:mysql://localhost:3306/baidubaike?useUnicode=true&characterEncoding=UTF-8"
val table = "baike_pages"
// 读取Hbase文件,在hbase的/usr/local/hbase/conf/hbase-site.xml中写的地址
val hbasePath = "file:///usr/local/hbase/hbase-tmp"
// 创建hbase configuration
val hBaseConf = HBaseConfiguration.create()
hBaseConf.set(TableInputFormat.INPUT_TABLE, "student")
// 初始化jobconf,TableOutputFormat必须是org.apache.hadoop.hbase.mapred包下的!
val jobConf = new JobConf(hBaseConf)
jobConf.setOutputFormat(classOf[TableOutputFormat])
jobConf.set(TableOutputFormat.OUTPUT_TABLE, "student")
val indataRDD = sc.makeRDD(Array("1,99,98","2,97,96","3,95,94"))
val rdd = indataRDD.map(_.split(',')).map{arr=>{
/*一个Put对象就是一行记录,在构造方法中指定主键
* 所有插入的数据必须用org.apache.hadoop.hbase.util.Bytes.toBytes方法转换
* Put.add方法接收三个参数:列族,列名,数据
*/
val put = new Put(Bytes.toBytes(arr(0)))
put.add(Bytes.toBytes("course"),Bytes.toBytes("math"),Bytes.toBytes(arr(1)))
put.add(Bytes.toBytes("course"),Bytes.toBytes("english"),Bytes.toBytes(arr(2)))
//转化成RDD[(ImmutableBytesWritable,Put)]类型才能调用saveAsHadoopDataset
(new ImmutableBytesWritable, put)
}}
rdd.saveAsHadoopDataset(jobConf)
sc.stop()
}
}
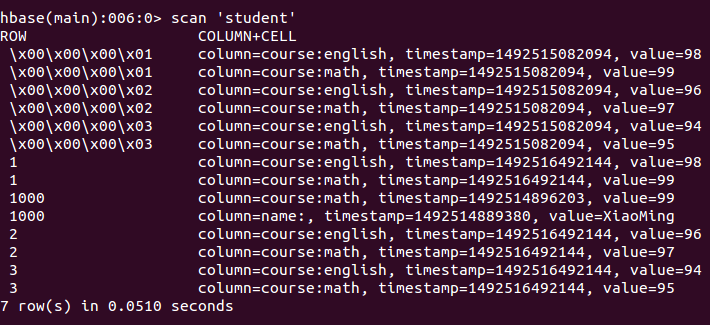
3.从Hbase中读取数据
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql._
import java.util.Properties
import com.google.common.collect.Lists
import org.apache.spark.sql.types.{ArrayType, StringType, StructField, StructType}
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.{Get, Put, Result, Scan}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapred.TableOutputFormat
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapred.JobConf
/**
* Created by mi on 17-4-11.
*/
case class resultset(name: String,
info: String,
summary: String)
case class IntroItem(name: String, value: String)
case class BaikeLocation(name: String,
url: String = "",
info: Seq[IntroItem] = Seq(),
summary: Option[String] = None)
case class MewBaikeLocation(name: String,
url: String = "",
info: Option[String] = None,
summary: Option[String] = None)
object MysqlOpt {
def main(args: Array[String]): Unit = {
// 本地模式运行,便于测试
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
// 创建 spark context
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
//定义数据库和表信息
val url = "jdbc:mysql://localhost:3306/baidubaike?useUnicode=true&characterEncoding=UTF-8"
val table = "baike_pages"
// 读取Hbase文件,在hbase的/usr/local/hbase/conf/hbase-site.xml中写的地址
val hbasePath = "file:///usr/local/hbase/hbase-tmp"
// 创建hbase configuration
val hBaseConf = HBaseConfiguration.create()
hBaseConf.set(TableInputFormat.INPUT_TABLE, "student")
// 从数据源获取数据并转化成rdd
val hBaseRDD = sc.newAPIHadoopRDD(hBaseConf, classOf[TableInputFormat], classOf[ImmutableBytesWritable], classOf[Result])
println(hBaseRDD.count())
// 将数据映射为表 也就是将 RDD转化为 dataframe schema
hBaseRDD.foreach{case (_,result) =>{
//获取行键
val key = Bytes.toString(result.getRow)
//通过列族和列名获取列
val math = Bytes.toString(result.getValue("course".getBytes,"math".getBytes))
println("Row key:"+key+" Math:"+math)
}}
sc.stop()
}
}
输出
Row key: Math:99
Row key: Math:97
Row key: Math:95
Row key:1 Math:99
Row key:1000 Math:99
Row key:2 Math:97
Row key:3 Math:95
Spark学习笔记——读写Hbase的更多相关文章
- Spark学习笔记——读写HDFS
使用Spark读写HDFS中的parquet文件 文件夹中的parquet文件 build.sbt文件 name := "spark-hbase" version := " ...
- Spark学习笔记——读写MySQL
1.使用Spark读取MySQL中某个表中的信息 build.sbt文件 name := "spark-hbase" version := "1.0" scal ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
- Hadoop学习笔记之HBase Shell语法练习
Hadoop学习笔记之HBase Shell语法练习 作者:hugengyong 下面我们看看HBase Shell的一些基本操作命令,我列出了几个常用的HBase Shell命令,如下: 名称 命令 ...
- HBase学习笔记之HBase的安装和配置
HBase学习笔记之HBase的安装和配置 我是为了调研和验证hbase的bulkload功能,才安装hbase,学习hbase的.为了快速的验证bulkload功能,我安装了一个节点的hadoop集 ...
随机推荐
- mogodb排序
db.getClloection('user').find().sort({'age':-1}).pretty() 2.自然排序,也就是插入的先后顺序 db.getClloection('user') ...
- C++学习笔记38:事件机制
事件基本概念 操作系统或应用程序内部发生某件事,程序的某个组件需要响应该事件,并进行特定处理 面向对象架构中,事件响应函数最可能为成员函数 问题:指向类成员函数的指针不能转换为哑型指针void *,也 ...
- eclipse中配置server
打开Eclipse,在打开上面的help--- install new software---- work with 里面点开选择--All Available Sites-- 等下面的pending ...
- Git:本地建服务器及入门使用方法
1. 安装与配置Git服务器 sudo apt-get install git 1.1 注册一个git账号, 用于运行和维护git sudo adduser git 1.2 创建证书登录: 收集所有需 ...
- android 布局文件 ScrollView 中的 listView item 显示不全解决方案
import android.content.Context;import android.util.AttributeSet;import android.widget.ListView; /** ...
- 移动端web禁止长按选择文字以及弹出菜单
/*如果是禁用长按选择文字功能,用css*/ * { -webkit-touch-callout:none; -webkit-user-select:none; -khtml-user-select: ...
- 如何成为一名Top DevOps Engineer
软件世界的战场 如果你对devops的概念不是很了解的话,没有关系,可以先跳到维基百科阅读一下DevOps条目.有了模模糊糊的概念之后, 我们先抛开所有市面上对于devops的各种夸大和炒作,首先来思 ...
- Web 前端面试题整理(不定时更新)
重要知识需要系统学习.透彻学习,形成自己的知识链.万不可投机取巧,临时抱佛脚只求面试侥幸混过关是错误的! 面试有几点需注意: 面试题目: 根据你的等级和职位的变化,入门级到专家级,广度和深度都会有所增 ...
- linux 切分文件
linux经常需要处理文件,如果文件比较大,那么需要切分成为若干的小文件再处理. 命令:split 比如有一个文件: ll -h 1431531915758 -rw-r--r-- 1 ticketde ...
- C#串口SerialPort常用属性方法
SerialPort(): //属性 .BaudRate;获取或设置波特率 .BytesToRead;得到 接收到数据的字节数 .BytesToWrites;得到送往串口的字节数 .DataBits; ...