Spark学习笔记——读写HDFS
使用Spark读写HDFS中的parquet文件
文件夹中的parquet文件

build.sbt文件
name := "spark-hbase" version := "1.0" scalaVersion := "2.11.8" libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "2.1.0",
"mysql" % "mysql-connector-java" % "5.1.31",
"org.apache.spark" %% "spark-sql" % "2.1.0",
"org.apache.hbase" % "hbase-common" % "1.3.0",
"org.apache.hbase" % "hbase-client" % "1.3.0",
"org.apache.hbase" % "hbase-server" % "1.3.0",
"org.apache.hbase" % "hbase" % "1.2.1"
)
Scala实现方法
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql._
import java.util.Properties
import com.google.common.collect.Lists
import org.apache.spark.sql.types.{ArrayType, StringType, StructField, StructType}
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.{Result, Scan}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
/**
* Created by mi on 17-4-11.
*/
case class resultset(name: String,
info: String,
summary: String)
case class IntroItem(name: String, value: String)
case class BaikeLocation(name: String,
url: String = "",
info: Seq[IntroItem] = Seq(),
summary: Option[String] = None)
case class MewBaikeLocation(name: String,
url: String = "",
info: Option[String] = None,
summary: Option[String] = None)
object MysqlOpt {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
//定义数据库和表信息
val url = "jdbc:mysql://localhost:3306/baidubaike?useUnicode=true&characterEncoding=UTF-8"
val table = "baike_pages"
//读取parquetFile,并写入Mysql
val sparkSession = SparkSession.builder()
.master("local")
.appName("spark session example")
.getOrCreate()
val parquetDF = sparkSession.read.parquet("/home/mi/coding/coding/baikeshow_data/baikeshow")
// parquetDF.collect().take(20).foreach(println)
//parquetDF.show()
//BaikeLocation是读取的parquet文件中的case class
val ds = parquetDF.as[BaikeLocation].map { line =>
//把info转换为新的case class中的类型String
val info = line.info.map(item => item.name + ":" + item.value).mkString(",")
//注意需要把字段放在一个case class中,不然会丢失列信息
MewBaikeLocation(name = line.name, url = line.url, info = Some(info), summary = line.summary)
}.cache()
ds.show()
// ds.take(2).foreach(println)
//写入Mysql
// val prop = new Properties()
// prop.setProperty("user", "root")
// prop.setProperty("password", "123456")
// ds.write.mode(SaveMode.Append).jdbc(url, "baike_location", prop)
//写入parquetFile
ds.repartition(10).write.parquet("/home/mi/coding/coding/baikeshow_data/baikeshow1")
}
}
df.show打印出来的信息,如果没放在一个case class中的话,name,url,info,summary这列信息会变成1,2,3,4

使用spark-shell查看写回去的parquet文件的信息
#进入spark-shell
import org.apache.spark.sql.SQLContext
val sqlContext = new SQLContext(sc)
val path = "file:///home/mi/coding/coding/baikeshow_data/baikeshow1"
val df = sqlContext.parquetFile(path)
df.show
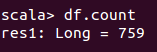
df.count

如果只想显示某一列的话,可以这么做
df.select("title").take(100).foreach(println) //只显示title这一列的信息
Spark学习笔记——读写HDFS的更多相关文章
- Spark学习笔记——读写Hbase
1.首先在Hbase中建立一张表,名字为student 参考 Hbase学习笔记——基本CRUD操作 一个cell的值,取决于Row,Column family,Column Qualifier和Ti ...
- Spark学习笔记——读写MySQL
1.使用Spark读取MySQL中某个表中的信息 build.sbt文件 name := "spark-hbase" version := "1.0" scal ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记2——RDD(上)
目录 Spark学习笔记2--RDD(上) RDD是什么? 例子 创建 RDD 并行化方式 读取外部数据集方式 RDD 操作 转化操作 行动操作 惰性求值 Spark学习笔记2--RDD(上) 笔记摘 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
随机推荐
- window 10系统怎样手动更改电脑的时间
win10系统的电脑显示时间默认的是自动网络校时,也就是电脑的时间跟网络时间同步,那么win10系统怎样手动更改电脑时间呢? 点击电脑左下方的win图标,找到菜单里的[设置] 点击菜单里的[设置],弹 ...
- tcp nonblock connection rst
客户端(>5w)异步connect连接到server端,server端listen backlog设置为1024,发现存在部分客户端建立连接后,收到服务端的rst包. 先看下tcp监听套接字维护 ...
- 在AngularJS中使用谷歌地图把当前位置显示出来
如何使用谷歌地图把当前位置显示出来呢? --在html5中,为我们提供了navigator.geolocation.getCurrentPosition(f1, f2)函数,f1是定位成功调用的函数, ...
- JVM Debugger Memory View for IntelliJ IDEA
Posted on August 19, 2016 by Andrey Cheptsov Every day we try to find new ways to improve developer ...
- app v1界面
- Spark2.2+ES6.4.2(三十一):Spark下生成测试数据,并在Spark环境下使用BulkProcessor将测试数据入库到ES
Spark下生成2000w测试数据(每条记录150列) 使用spark生成大量数据过程中遇到问题,如果sc.parallelize(fukeData, 64);的记录数特别大比如500w,1000w时 ...
- Node.js Cheerio parser breaks UTF-8 encoding
From: https://stackoverflow.com/questions/31574127/node-js-cheerio-parser-breaks-utf-8-encoding [问题] ...
- HOW TO REPLACE ALL OCCURRENCES OF A CHARACTER IN A STD::STRING
From: http://www.martinbroadhurst.com/replacing-all-occurrences-of-a-character-in-a-stdstring.html T ...
- 〖Android〗从Android Studio转为Eclipse开发项目运行程序闪退的解决方法
很久没有撸Android App开发了- 最近把一个月前通过反编译.二次修改的Android SSHD项目进行简单修改一下: 突然发现迁移项目时,报了一个错误,同时还出现了闪退情况: - ::): t ...
- SoapUI Pro Project Solution Collection-XML assert
in soapui the XML object used here is from org.w3c.dom package so you need to read this article car ...