POJ 1330 Nearest Common Ancestors(Targin求LCA)
| Time Limit: 1000MS | Memory Limit: 10000K | |
| Total Submissions: 26612 | Accepted: 13734 |
Description
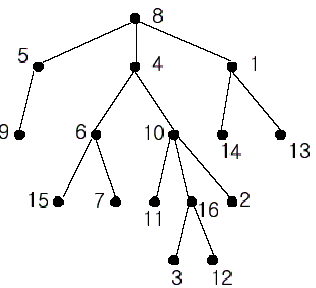
For other examples, the nearest common ancestor of nodes 2 and 3 is node 10, the nearest common ancestor of nodes 6 and 13 is node 8, and the nearest common ancestor of nodes 4 and 12 is node 4. In the last example, if y is an ancestor of z, then the nearest common ancestor of y and z is y.
Write a program that finds the nearest common ancestor of two distinct nodes in a tree.
Input
Output
Sample Input
2 16 1 14 8 5 10 16 5 9 4 6 8 4 4 10 1 13 6 15 10 11 6 7 10 2 16 3 8 1 16 12 16 7 5 2 3 3 4 3 1 1 5 3 5
Sample Output
4 3
思路
最近公共祖先模板题
#include<iostream>
#include<cstdio>
#include<cstring>
#include<vector>
using namespace std;
const int maxn = 10005;
struct Edge{
int to,next;
}edge[maxn];
vector<int>qry[maxn];
int N,tot,fa[maxn],head[maxn],indegree[maxn],ancestor[maxn];
bool vis[maxn];
void init()
{
tot = 0;
for (int i = 1;i <= N;i++) fa[i] = i,head[i] = -1,indegree[i] = 0,vis[i] = false,qry[i].clear();
}
void addedge(int u,int to)
{
edge[tot] = (Edge){to,head[u]};
head[u] = tot++;
}
int find(int x)
{
int r = x;
while (r != fa[r]) r = fa[r];
int i = x,j;
while (i != r)
{
j = fa[i];
fa[i] = r;
i = j;
}
return r;
}
void Union(int x,int y)
{
x = find(x),y = find(y);
if (x == y) return;
fa[y] = x; //不能写成fa[x] = y,与集合合并的祖先有关系
}
void targin_LCA(int u)
{
ancestor[u] = u;
for (int i = head[u];i != -1;i = edge[i].next)
{
int v = edge[i].to;
targin_LCA(v);
Union(u,v);
ancestor[find(u)] = u;
}
vis[u] = true;
int size = qry[u].size();
for (int i = 0;i < size;i++)
{
if (vis[qry[u][i]]) printf("%d\n",ancestor[find(qry[u][i])]);
return;
}
}
int main()
{
int T;
scanf("%d",&T);
while (T--)
{
int u,v;
scanf("%d",&N);
init();
for (int i = 1;i < N;i++)
{
scanf("%d%d",&u,&v);
addedge(u,v);
indegree[v]++;
}
scanf("%d%d",&u,&v);
qry[u].push_back(v),qry[v].push_back(u);
for (int i = 1;i <= N;i++)
{
if (!indegree[i])
{
targin_LCA(i);
break;
}
}
}
return 0;
}
#include<stdio.h>
#include<string.h>
#include<iostream>
#include<algorithm>
#include<math.h>
#include<vector>
using namespace std;
const int MAXN=10010;
int F[MAXN];//并查集
int r[MAXN];//并查集中集合的个数
bool vis[MAXN];//访问标记
int ancestor[MAXN];//祖先
struct Node
{
int to,next;
}edge[MAXN*2];
int head[MAXN];
int tol;
void addedge(int a,int b)
{
edge[tol].to=b;
edge[tol].next=head[a];
head[a]=tol++;
edge[tol].to=a;
edge[tol].next=head[b];
head[b]=tol++;
}
struct Query
{
int q,next;
int index;//查询编号
}query[MAXN*2];//查询数
int answer[MAXN*2];//查询结果
int cnt;
int h[MAXN];
int tt;
int Q;//查询个数
void add_query(int a,int b,int i)
{
query[tt].q=b;
query[tt].next=h[a];
query[tt].index=i;
h[a]=tt++;
query[tt].q=a;
query[tt].next=h[b];
query[tt].index=i;
h[b]=tt++;
}
void init(int n)
{
for(int i=1;i<=n;i++)
{
F[i]=-1;
r[i]=1;
vis[i]=false;
ancestor[i]=0;
tol=0;
tt=0;
cnt=0;//已经查询到的个数
}
memset(head,-1,sizeof(head));
memset(h,-1,sizeof(h));
}
int find(int x)
{
if(F[x]==-1)return x;
return F[x]=find(F[x]);
}
void Union(int x,int y)//合并
{
int t1=find(x);
int t2=find(y);
if(t1!=t2)
{
if(r[t1]<=r[t2])
{
F[t1]=t2;
r[t2]+=r[t1];
}
else
{
F[t2]=t1;
r[t1]+=r[t2];
}
}
}
void LCA(int u)
{
//if(cnt>=Q)return;//不要加这个
ancestor[u]=u;
vis[u]=true;//这个一定要放在前面
for(int i=head[u];i!=-1;i=edge[i].next)
{
int v=edge[i].to;
if(vis[v])continue;
LCA(v);
Union(u,v);
ancestor[find(u)]=u;
}
for(int i=h[u];i!=-1;i=query[i].next)
{
int v=query[i].q;
if(vis[v])
{
answer[query[i].index]=ancestor[find(v)];
cnt++;//已经找到的答案数
}
}
}
bool flag[MAXN];
int main()
{
//freopen("in.txt","r",stdin);
//freopen("out.txt","w",stdout);
int T;
int N;
int u,v;
scanf("%d",&T);
while(T--)
{
scanf("%d",&N);
init(N);
memset(flag,false,sizeof(flag));
for(int i=1;i<N;i++)
{
scanf("%d%d",&u,&v);
flag[v]=true;
addedge(u,v);
}
Q=1;//查询只有一组
scanf("%d%d",&u,&v);
add_query(u,v,0);//增加一组查询
int root;
for(int i=1;i<=N;i++)
if(!flag[i])
{
root=i;
break;
}
LCA(root);
for(int i=0;i<Q;i++)//输出所有答案
printf("%d\n",answer[i]);
}
return 0;
}
POJ 1330 Nearest Common Ancestors(Targin求LCA)的更多相关文章
- POJ - 1330 Nearest Common Ancestors(基础LCA)
POJ - 1330 Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000KB 64bit IO Format: %l ...
- poj 1330 Nearest Common Ancestors 单次LCA/DFS
Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 19919 Accept ...
- POJ 1330 Nearest Common Ancestors(裸LCA)
Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 39596 Accept ...
- POJ 1330 Nearest Common Ancestors(Tarjan离线LCA)
Description A rooted tree is a well-known data structure in computer science and engineering. An exa ...
- poj 1330 Nearest Common Ancestors 裸的LCA
#include<iostream> #include<cstdio> #include<cstring> #include<algorithm> #i ...
- POJ 1330 Nearest Common Ancestors / UVALive 2525 Nearest Common Ancestors (最近公共祖先LCA)
POJ 1330 Nearest Common Ancestors / UVALive 2525 Nearest Common Ancestors (最近公共祖先LCA) Description A ...
- POJ.1330 Nearest Common Ancestors (LCA 倍增)
POJ.1330 Nearest Common Ancestors (LCA 倍增) 题意分析 给出一棵树,树上有n个点(n-1)条边,n-1个父子的边的关系a-b.接下来给出xy,求出xy的lca节 ...
- POJ 1330 Nearest Common Ancestors(lca)
POJ 1330 Nearest Common Ancestors A rooted tree is a well-known data structure in computer science a ...
- POJ 1330 Nearest Common Ancestors 倍增算法的LCA
POJ 1330 Nearest Common Ancestors 题意:最近公共祖先的裸题 思路:LCA和ST我们已经很熟悉了,但是这里的f[i][j]却有相似却又不同的含义.f[i][j]表示i节 ...
- LCA POJ 1330 Nearest Common Ancestors
POJ 1330 Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 24209 ...
随机推荐
- MVC5 + EF6 + Bootstrap3 (15) 应用ModelState和Data Annotation做服务器端数据验证
Slark.NET-博客园 http://www.cnblogs.com/slark/p/mvc5-ef6-bs3-get-started-server-side-validation.html 系列 ...
- 纯手工打造漂亮的垂直时间轴,使用最简单的HTML+CSS+JQUERY完成100个版本更新记录的华丽转身!
前言 FineUI控件库发展至今已经有 5 个年头,目前论坛注册的QQ会员 5000 多人,捐赠用户 500 多人(捐赠用户转化率达到10%以上,在国内开源领域相信这是一个梦幻数字!也足以证明Fine ...
- Asp.Net Core-几行代码解决Razor中的嵌套if语句
MVC开发中,经常会遇到在razor中插入简单的逻辑判断. @if (clientManager.IsAdmin) { if (!Model.Topic.Top) { <a asp-action ...
- 东大OJ-Max Area
1034: Max Area 时间限制: 1 Sec 内存限制: 128 MB 提交: 40 解决: 6 [提交][状态][讨论版] 题目描述 又是这道题,请不要惊讶,也许你已经见过了,那就请你再 ...
- ubuntu-16.4TLS安装QQ
01下载Winqq 下载地址:http://www.ubuntukylin.com/application/show.php?lang=cn&id=27902解压zip unzip wine- ...
- C++ new失败的处理
我们都知道,使用 malloc/calloc 等分配内存的函数时,一定要检查其返回值是否为“空指针”(亦即检查分配内存的操作是否成功),这是良好的编程习惯,也是编写可靠程序所必需的.但是,如果你简单地 ...
- 十天冲刺---Day6
站立式会议 站立式会议内容总结: 燃尽图 照片 一个队友回家有事,一个队友参加校运会比赛,只剩下两个人. 失去了UI是噩梦
- 十天冲刺---Day9
站立式会议 站立式会议内容总结: 燃尽图 照片 队员们都回来了,写完之后继续对alpha版本进行迭代. 希望演示的时候能拿得出来.
- ubuntu mysql远程登录设置
1:打开命令终端:vim /etc/mysql/my.cnf 并找到bind-address = 127.0.0.1这行 注释掉这行,如:#bind-address = 127.0.0.1,即在前面加 ...
- Maven-eclipse运行maven命令
右击项目,点击Run as,如下图: 即可看到有很多现有的maven命令,点击即可运行,并在控制台可以看到运行信息 如果你想运行的maven命令在这里没有找到,点击Maven build创建新的命令, ...