POJ 1330 Nearest Common Ancestors(Targin求LCA)
| Time Limit: 1000MS | Memory Limit: 10000K | |
| Total Submissions: 26612 | Accepted: 13734 |
Description
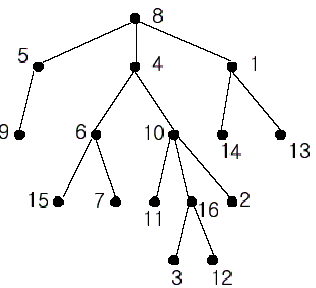
For other examples, the nearest common ancestor of nodes 2 and 3 is node 10, the nearest common ancestor of nodes 6 and 13 is node 8, and the nearest common ancestor of nodes 4 and 12 is node 4. In the last example, if y is an ancestor of z, then the nearest common ancestor of y and z is y.
Write a program that finds the nearest common ancestor of two distinct nodes in a tree.
Input
Output
Sample Input
2 16 1 14 8 5 10 16 5 9 4 6 8 4 4 10 1 13 6 15 10 11 6 7 10 2 16 3 8 1 16 12 16 7 5 2 3 3 4 3 1 1 5 3 5
Sample Output
4 3
思路
最近公共祖先模板题
#include<iostream>
#include<cstdio>
#include<cstring>
#include<vector>
using namespace std;
const int maxn = 10005;
struct Edge{
int to,next;
}edge[maxn];
vector<int>qry[maxn];
int N,tot,fa[maxn],head[maxn],indegree[maxn],ancestor[maxn];
bool vis[maxn];
void init()
{
tot = 0;
for (int i = 1;i <= N;i++) fa[i] = i,head[i] = -1,indegree[i] = 0,vis[i] = false,qry[i].clear();
}
void addedge(int u,int to)
{
edge[tot] = (Edge){to,head[u]};
head[u] = tot++;
}
int find(int x)
{
int r = x;
while (r != fa[r]) r = fa[r];
int i = x,j;
while (i != r)
{
j = fa[i];
fa[i] = r;
i = j;
}
return r;
}
void Union(int x,int y)
{
x = find(x),y = find(y);
if (x == y) return;
fa[y] = x; //不能写成fa[x] = y,与集合合并的祖先有关系
}
void targin_LCA(int u)
{
ancestor[u] = u;
for (int i = head[u];i != -1;i = edge[i].next)
{
int v = edge[i].to;
targin_LCA(v);
Union(u,v);
ancestor[find(u)] = u;
}
vis[u] = true;
int size = qry[u].size();
for (int i = 0;i < size;i++)
{
if (vis[qry[u][i]]) printf("%d\n",ancestor[find(qry[u][i])]);
return;
}
}
int main()
{
int T;
scanf("%d",&T);
while (T--)
{
int u,v;
scanf("%d",&N);
init();
for (int i = 1;i < N;i++)
{
scanf("%d%d",&u,&v);
addedge(u,v);
indegree[v]++;
}
scanf("%d%d",&u,&v);
qry[u].push_back(v),qry[v].push_back(u);
for (int i = 1;i <= N;i++)
{
if (!indegree[i])
{
targin_LCA(i);
break;
}
}
}
return 0;
}
#include<stdio.h>
#include<string.h>
#include<iostream>
#include<algorithm>
#include<math.h>
#include<vector>
using namespace std;
const int MAXN=10010;
int F[MAXN];//并查集
int r[MAXN];//并查集中集合的个数
bool vis[MAXN];//访问标记
int ancestor[MAXN];//祖先
struct Node
{
int to,next;
}edge[MAXN*2];
int head[MAXN];
int tol;
void addedge(int a,int b)
{
edge[tol].to=b;
edge[tol].next=head[a];
head[a]=tol++;
edge[tol].to=a;
edge[tol].next=head[b];
head[b]=tol++;
}
struct Query
{
int q,next;
int index;//查询编号
}query[MAXN*2];//查询数
int answer[MAXN*2];//查询结果
int cnt;
int h[MAXN];
int tt;
int Q;//查询个数
void add_query(int a,int b,int i)
{
query[tt].q=b;
query[tt].next=h[a];
query[tt].index=i;
h[a]=tt++;
query[tt].q=a;
query[tt].next=h[b];
query[tt].index=i;
h[b]=tt++;
}
void init(int n)
{
for(int i=1;i<=n;i++)
{
F[i]=-1;
r[i]=1;
vis[i]=false;
ancestor[i]=0;
tol=0;
tt=0;
cnt=0;//已经查询到的个数
}
memset(head,-1,sizeof(head));
memset(h,-1,sizeof(h));
}
int find(int x)
{
if(F[x]==-1)return x;
return F[x]=find(F[x]);
}
void Union(int x,int y)//合并
{
int t1=find(x);
int t2=find(y);
if(t1!=t2)
{
if(r[t1]<=r[t2])
{
F[t1]=t2;
r[t2]+=r[t1];
}
else
{
F[t2]=t1;
r[t1]+=r[t2];
}
}
}
void LCA(int u)
{
//if(cnt>=Q)return;//不要加这个
ancestor[u]=u;
vis[u]=true;//这个一定要放在前面
for(int i=head[u];i!=-1;i=edge[i].next)
{
int v=edge[i].to;
if(vis[v])continue;
LCA(v);
Union(u,v);
ancestor[find(u)]=u;
}
for(int i=h[u];i!=-1;i=query[i].next)
{
int v=query[i].q;
if(vis[v])
{
answer[query[i].index]=ancestor[find(v)];
cnt++;//已经找到的答案数
}
}
}
bool flag[MAXN];
int main()
{
//freopen("in.txt","r",stdin);
//freopen("out.txt","w",stdout);
int T;
int N;
int u,v;
scanf("%d",&T);
while(T--)
{
scanf("%d",&N);
init(N);
memset(flag,false,sizeof(flag));
for(int i=1;i<N;i++)
{
scanf("%d%d",&u,&v);
flag[v]=true;
addedge(u,v);
}
Q=1;//查询只有一组
scanf("%d%d",&u,&v);
add_query(u,v,0);//增加一组查询
int root;
for(int i=1;i<=N;i++)
if(!flag[i])
{
root=i;
break;
}
LCA(root);
for(int i=0;i<Q;i++)//输出所有答案
printf("%d\n",answer[i]);
}
return 0;
}
POJ 1330 Nearest Common Ancestors(Targin求LCA)的更多相关文章
- POJ - 1330 Nearest Common Ancestors(基础LCA)
POJ - 1330 Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000KB 64bit IO Format: %l ...
- poj 1330 Nearest Common Ancestors 单次LCA/DFS
Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 19919 Accept ...
- POJ 1330 Nearest Common Ancestors(裸LCA)
Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 39596 Accept ...
- POJ 1330 Nearest Common Ancestors(Tarjan离线LCA)
Description A rooted tree is a well-known data structure in computer science and engineering. An exa ...
- poj 1330 Nearest Common Ancestors 裸的LCA
#include<iostream> #include<cstdio> #include<cstring> #include<algorithm> #i ...
- POJ 1330 Nearest Common Ancestors / UVALive 2525 Nearest Common Ancestors (最近公共祖先LCA)
POJ 1330 Nearest Common Ancestors / UVALive 2525 Nearest Common Ancestors (最近公共祖先LCA) Description A ...
- POJ.1330 Nearest Common Ancestors (LCA 倍增)
POJ.1330 Nearest Common Ancestors (LCA 倍增) 题意分析 给出一棵树,树上有n个点(n-1)条边,n-1个父子的边的关系a-b.接下来给出xy,求出xy的lca节 ...
- POJ 1330 Nearest Common Ancestors(lca)
POJ 1330 Nearest Common Ancestors A rooted tree is a well-known data structure in computer science a ...
- POJ 1330 Nearest Common Ancestors 倍增算法的LCA
POJ 1330 Nearest Common Ancestors 题意:最近公共祖先的裸题 思路:LCA和ST我们已经很熟悉了,但是这里的f[i][j]却有相似却又不同的含义.f[i][j]表示i节 ...
- LCA POJ 1330 Nearest Common Ancestors
POJ 1330 Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 24209 ...
随机推荐
- Alpha版本测试报告
请根据团队项目中软件的需求文档.功能规格说明书和技术规格说明书,写出软件的测试计划.测试过程和测试结果,并回答下述问题. 1. 在测试过程中发现了多少Bug? 2. 你是怎么进行场景测试(scenar ...
- Common Issues Which Cause Roles to Recycle
This section lists some of the common causes of deployment problems, and offers troubleshooting tips ...
- 比较Windows Azure 网站(Web Sites), 云服务(Cloud Services)and 虚机(Virtual Machines)
Windows Azure提供了几个部署web应用程序的方法,比如Windows Azure网站.云服务和虚拟机.你可能无法确定哪一个最适合您的需要,或者你可能清楚的概念,比如IaaS vs PaaS ...
- NPOI2.0学习(一)
引用空间 using NPOI.HSSF.UserModel; using NPOI.SS.UserModel; 创建工作簿(workbook)和sheet HSSFWorkbook wk = new ...
- 转一篇关于Unity的PlayMaker
这篇文章转自http://va.lent.in/should-you-use-playmaker-in-production/ 此文作者大概深受其苦,吐槽了playmaker的多个蛋疼的地方,这其实说 ...
- SDRAM读写一字(下)
SDRAM读写一字 SDRAM控制模块 上电后进行初始化状态,初始化完成后进入空闲状态,在此进行判断如下判断: 如果自刷新时间到,则进行自刷新操作,操作完成后重新进入空闲状态: 如果读使能有效则进行读 ...
- Addressing Complex and Subjective Product-Related Queries with Customer Reviews-www2016-20160505
1.Information publication:www2016 author:Julian McAuley 2.What 学习商品评论中的信息,对商品的提问,自动给出回答:按照相关程度排序 3.D ...
- android 布局之scrollview
今天在布局页面的时候后犯了难,我要显示的内容一个页面展示不完,怎么办呢? 于是随便找了个app点开一看,哎呀原来还能翻动啊!这是啥布局呢?原来是ScrollView 官方api相关的内容全是英文,这可 ...
- 网上找到的一个jquery版网页换肤特效
这个跟我之前在锋利的JQuery那本书里看到的那个一模一样. <!DOCTYPE html> <html> <head> <meta name="& ...
- mysql常用方法学习
环境 create table phople ( id int(11) not null primary key auto_increment, name char(20) not null, sex ...