RocketMQ源码 — 七、 RocketMQ高可用(2)
上一篇说明了RocketMQ怎么支持broker集群的,这里接着说RocketMQ实现高可用的手段之一——冗余。
RocketMQ部署的时候一个broker set会有一个mater和一个或者多个slave,salve起到的作用就是同步master存储的的消息,并且会接收部分consumer读取消息的请求,下面围绕两个问题来阐明怎么做的冗余:
- 怎么实现冗余
- 冗余之后的消息读取
怎么实现冗余?
RocketMQ通过主从结构来实现消息冗余,master接收来自producer发送来的消息,然后同步消息到slave,根据master的role不同,同步的时机可分为两种不同的情况:
- SYNC_MASTER:如果master是这种角色,每次master在将producer发送来的消息写入内存(磁盘)的时候会同步等待master将消息传输到slave
- ASYNC_MASTER:这种角色下消息会异步复制到slave
这里注意的是master传输到slave只有CommitLog的物理文件。
master和slave之间传输CommitLog的主要流程如下:
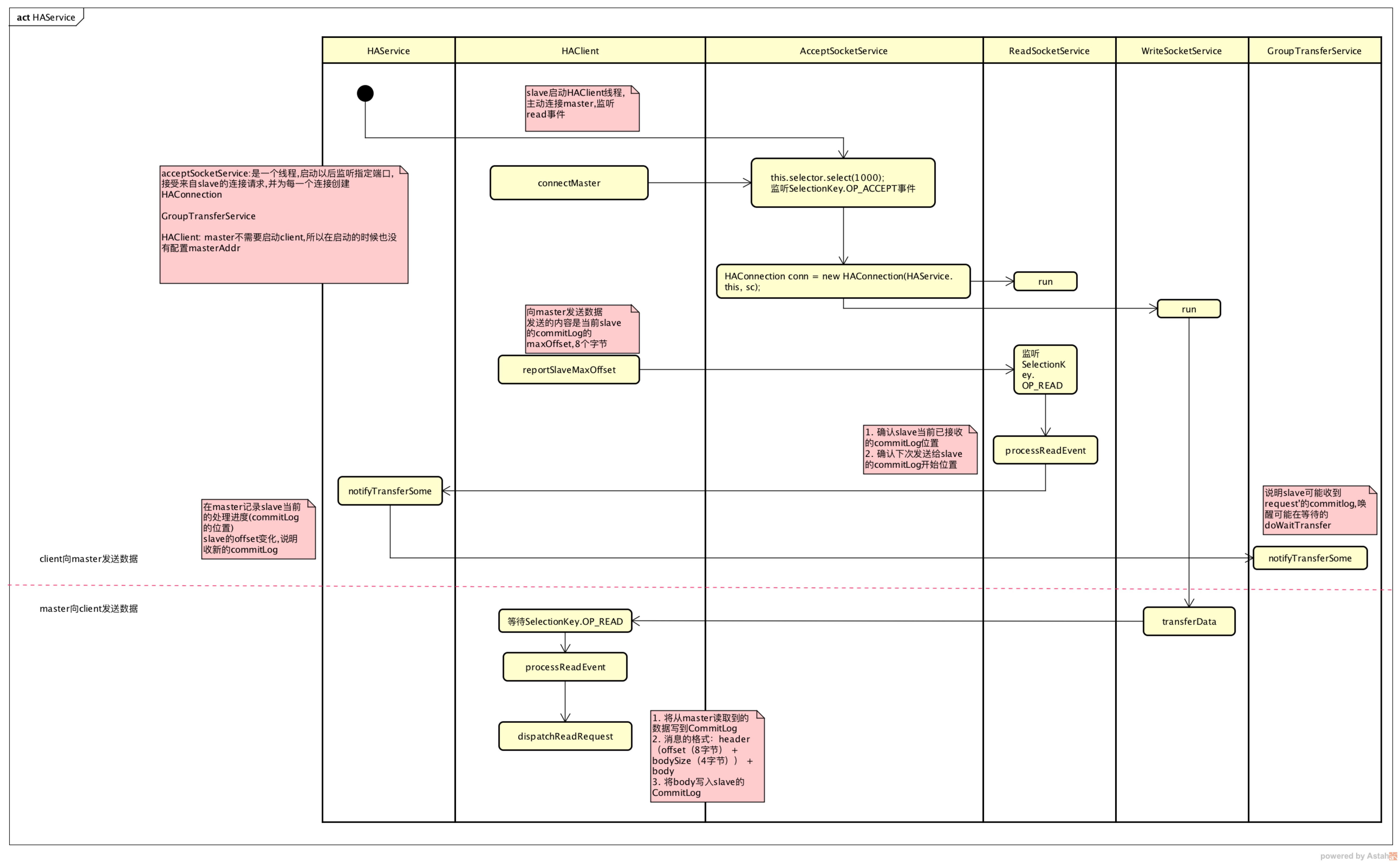
这里主要涉及到两个class(包括其内部类):HAService、HAConnection(这两个类的源码中文注释可以在这里找到)。
broker在启动的时候会调用DefaultMessageStore.start方法,这里面会调用HAService.start来启动相关的服务:
- AcceptSocketService:启动serverSocket并监听来自HAClient的连接
- GroupTransferService:broker写消息的时候如果需要同步等待消息同步到slave,会用到这个服务
- HAClient:如果是slave,才会启动haClient。
master和slave之间的数据通信过程是:
- master启动之后会监听来自slave的连接,slave启动之后会主动连接到master。
- 在连接建立之后,slave会向master上报自己的本地的CommitLog的offset
- master根据slave的offset来决定从那里开始向slave发送数据
slave发送给master的数据格式:
offset(8字节)
offset:slave本地CommitLog的maxOffset
master发送给slave的数据格式:
header(offset(8字节) + bodySize(4字节)) + body
offset:由于master发送给slave的CommitLog的单位是MappedFile的个数,这个offset是MappedFile的起始位置
bodySize:MappedFile的大小
body:MappedFile的内容
前面说过SYNC_MASTER和ASYNC_MASTER传输数据给slave的过程稍有不同,下面先看看ASYNC_MASTER怎么传输数据到slave的。
ASYNC_MASTER同步数据到slave
- salve连接到master,向master上报slave当前的offset
- master收到后确认给slave发送数据的开始位置
- master查询开始位置对应的MappedFIle
- master将查找到的数据发送给slave
- slave收到数据后保存到自己的CommitLog
// org.apache.rocketmq.store.ha.HAService.HAClient#run
public void run() {
log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
// 只有配置了HAMaster地址的broker才会连接到master
if (this.connectMaster()) {
if (this.isTimeToReportOffset()) {
// 向master上报slave本地最大的CommitLog的offset
boolean result = this.reportSlaveMaxOffset(this.currentReportedOffset);
if (!result) {
this.closeMaster();
}
}
this.selector.select(1000);
// 处理socket上的read事件,也就是处理master发来的数据
boolean ok = this.processReadEvent();
// 省略中间代码...
}
// master收到slave上报的offset后用下面的方法处理
// org.apache.rocketmq.store.ha.HAConnection.ReadSocketService#processReadEvent
private boolean processReadEvent() {
int readSizeZeroTimes = 0;
if (!this.byteBufferRead.hasRemaining()) {
this.byteBufferRead.flip();
this.processPostion = 0;
}
while (this.byteBufferRead.hasRemaining()) {
try {
int readSize = this.socketChannel.read(this.byteBufferRead);
if (readSize > 0) {
readSizeZeroTimes = 0;
this.lastReadTimestamp = HAConnection.this.haService.getDefaultMessageStore().getSystemClock().now();
if ((this.byteBufferRead.position() - this.processPostion) >= 8) {
int pos = this.byteBufferRead.position() - (this.byteBufferRead.position() % 8);
long readOffset = this.byteBufferRead.getLong(pos - 8);
this.processPostion = pos;
// slave上报过来的offset说明offset之前的数据slave都已经收到
HAConnection.this.slaveAckOffset = readOffset;
if (HAConnection.this.slaveRequestOffset < 0) {
// 如果是刚刚和slave建立连接,需要知道slave需要从哪里开始接收commitLog
HAConnection.this.slaveRequestOffset = readOffset;
log.info("slave[" + HAConnection.this.clientAddr + "] request offset " + readOffset);
}
// 如果收到来自slave的确认之后,唤醒等待同步到slave的线程(如果是SYNC_MASTER)
HAConnection.this.haService.notifyTransferSome(HAConnection.this.slaveAckOffset);
// 省略中间代码...
}
通过上面slave和master的通信,master已经知道第一次从哪里(slaveRequestOffset)开始给slave传输数据
@Override
public void run() {
HAConnection.log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
this.selector.select(1000);
// 说明还没收到来自slave的offset,等10ms重试
if (-1 == HAConnection.this.slaveRequestOffset) {
Thread.sleep(10);
continue;
}
// 如果是第一次发送数据需要计算出从哪里开始给slave发送数据
if (-1 == this.nextTransferFromWhere) {
if (0 == HAConnection.this.slaveRequestOffset) {
long masterOffset = HAConnection.this.haService.getDefaultMessageStore().getCommitLog().getMaxOffset();
masterOffset =
masterOffset
- (masterOffset % HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig()
.getMapedFileSizeCommitLog());
if (masterOffset < 0) {
masterOffset = 0;
}
this.nextTransferFromWhere = masterOffset;
} else {
this.nextTransferFromWhere = HAConnection.this.slaveRequestOffset;
}
log.info("master transfer data from " + this.nextTransferFromWhere + " to slave[" + HAConnection.this.clientAddr
+ "], and slave request " + HAConnection.this.slaveRequestOffset);
}
// 如果上一次transfer完成了才进行下一次transfer
if (this.lastWriteOver) {
long interval =
HAConnection.this.haService.getDefaultMessageStore().getSystemClock().now() - this.lastWriteTimestamp;
// 为什么要发送一个body的size是0的数据呢?怕时间太久连接断开?
if (interval > HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig()
.getHaSendHeartbeatInterval()) {
// Build Header
this.byteBufferHeader.position(0);
this.byteBufferHeader.limit(headerSize);
this.byteBufferHeader.putLong(this.nextTransferFromWhere);
this.byteBufferHeader.putInt(0);
this.byteBufferHeader.flip();
this.lastWriteOver = this.transferData();
if (!this.lastWriteOver)
continue;
}
} else {
// 说明上一次的数据还没有传输完成,这里继续上一次的传输
this.lastWriteOver = this.transferData();
if (!this.lastWriteOver)
continue;
}
SelectMappedBufferResult selectResult =
HAConnection.this.haService.getDefaultMessageStore().getCommitLogData(this.nextTransferFromWhere);
if (selectResult != null) {
// 发送找到的MappedFile数据
int size = selectResult.getSize();
if (size > HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig().getHaTransferBatchSize()) {
size = HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig().getHaTransferBatchSize();
}
long thisOffset = this.nextTransferFromWhere;
// 计算下次需要给slave发送数据的起始位置
this.nextTransferFromWhere += size;
selectResult.getByteBuffer().limit(size);
this.selectMappedBufferResult = selectResult;
// Build Header
this.byteBufferHeader.position(0);
this.byteBufferHeader.limit(headerSize);
this.byteBufferHeader.putLong(thisOffset);
this.byteBufferHeader.putInt(size);
this.byteBufferHeader.flip();
// 向slave发送数据
this.lastWriteOver = this.transferData();
} else {
// 如果没有需要给slave发送的数据,传输数据的线程等到100ms
// 或者等待broker接收到新发送来的消息的时候唤醒这个线程
HAConnection.this.haService.getWaitNotifyObject().allWaitForRunning(100);
}
// 省略中间代码
}
// 发送数据给slave,格式:header(offset(8字节) + body的size(4字节)) + body
private boolean transferData() throws Exception {
int writeSizeZeroTimes = 0;
// Write Header
// 前面已将需要发送的header数据放入byteBufferHeader
while (this.byteBufferHeader.hasRemaining()) {
int writeSize = this.socketChannel.write(this.byteBufferHeader);
if (writeSize > 0) {
writeSizeZeroTimes = 0;
this.lastWriteTimestamp = HAConnection.this.haService.getDefaultMessageStore().getSystemClock().now();
} else if (writeSize == 0) {
if (++writeSizeZeroTimes >= 3) {
break;
}
} else {
throw new Exception("ha master write header error < 0");
}
}
if (null == this.selectMappedBufferResult) {
return !this.byteBufferHeader.hasRemaining();
}
writeSizeZeroTimes = 0;
// Write Body
if (!this.byteBufferHeader.hasRemaining()) {
// selectMappedBufferResult里存放的是需要发送的MappedFile数据
while (this.selectMappedBufferResult.getByteBuffer().hasRemaining()) {
int writeSize = this.socketChannel.write(this.selectMappedBufferResult.getByteBuffer());
if (writeSize > 0) {
writeSizeZeroTimes = 0;
this.lastWriteTimestamp = HAConnection.this.haService.getDefaultMessageStore().getSystemClock().now();
} else if (writeSize == 0) {
if (++writeSizeZeroTimes >= 3) {
break;
}
} else {
throw new Exception("ha master write body error < 0");
}
}
}
boolean result = !this.byteBufferHeader.hasRemaining() && !this.selectMappedBufferResult.getByteBuffer().hasRemaining();
if (!this.selectMappedBufferResult.getByteBuffer().hasRemaining()) {
// 每次发送完成数据后清空selectMappedBufferResult,保证下一次发送前selectMappedBufferResult=null
this.selectMappedBufferResult.release();
this.selectMappedBufferResult = null;
}
return result;
}
上面master已经通过网络将MappedFile数据发送给slave,接下来就是slave收到master的数据,然后保存到自己的CommitLog。HAClient启动的时候向和master连接的socket上注册了read事件的selector,收到read事件之后,一次执行以下方法:
org.apache.rocketmq.store.ha.HAService.HAClient#processReadEvent
org.apache.rocketmq.store.ha.HAService.HAClient#dispatchReadRequest
slave接收数据主要的逻辑在dispatchReadRequest
// 将从master读取到的数据写到CommitLog
// 消息的格式:header(offset(8字节) + bodySize(4字节)) + body
private boolean dispatchReadRequest() {
final int msgHeaderSize = 8 + 4; // phyoffset + size
int readSocketPos = this.byteBufferRead.position();
while (true) {
// 当前从master读取到的数据的总大小 - 上一次处理(写入CommitLog)到的位置
int diff = this.byteBufferRead.position() - this.dispatchPostion;
// 确定收到的数据是完整的
if (diff >= msgHeaderSize) {
long masterPhyOffset = this.byteBufferRead.getLong(this.dispatchPostion);
int bodySize = this.byteBufferRead.getInt(this.dispatchPostion + 8);
long slavePhyOffset = HAService.this.defaultMessageStore.getMaxPhyOffset();
if (slavePhyOffset != 0) {
// 保证本次消息同步slave的commitLog起始位置和master这个mappedFile的起始位置相同
if (slavePhyOffset != masterPhyOffset) {
log.error("master pushed offset not equal the max phy offset in slave, SLAVE: "
+ slavePhyOffset + " MASTER: " + masterPhyOffset);
return false;
}
}
if (diff >= (msgHeaderSize + bodySize)) {
byte[] bodyData = new byte[bodySize];
this.byteBufferRead.position(this.dispatchPostion + msgHeaderSize);
this.byteBufferRead.get(bodyData);
// 将收到的MappedFile写入slave的commitLog
HAService.this.defaultMessageStore.appendToCommitLog(masterPhyOffset, bodyData);
this.byteBufferRead.position(readSocketPos);
// 记录本(上次)次读取消息的位置
this.dispatchPostion += msgHeaderSize + bodySize;
if (!reportSlaveMaxOffsetPlus()) {
return false;
}
continue;
}
}
// 到这里说明当前收到的信息不完整,需要使用byteBufferRead继续接收,所以要保证byteBufferRead的空间是足够接收的
if (!this.byteBufferRead.hasRemaining()) {
this.reallocateByteBuffer();
}
break;
}
return true;
}
slave的处理逻辑主要是:
- slave将接收到的数据都存在byteBufferRead
- 判断收到的数据是否完整,如果byteBufferRead待处理的数据大于headerSize则认为可以开始处理
- 判断收到的数据的offset是否和slave当前offset是否一致(也就是判断是否是slave需要的下一个MappedFile),如果不一致说明系统错误
- 按照数据协议从byteBufferRead依次读出offset、size、body
- 将body(MappedFile)写入slave的CommitLog
- 更新byteBufferRead里面的处理进度(当前已处理的字节数)
- 如果上面判断出收到的数据尚不足以处理,需要继续接收数据之前先对byteBufferRead进行扩容
这里对byteBufferRead“扩容”的说法并不准确,因为并没有扩大byteBufferRead的大小,具体的算法如下
// readBuffer不够的时候"重新"申请buffer
// "重新":其实并没有重新申请,只是将尚未读取的部分放在准备好(backup)的buffer中,然后将backup赋值给readBuffer
// org.apache.rocketmq.store.ha.HAService.HAClient#reallocateByteBuffer
private void reallocateByteBuffer() {
// 计算byteBufferRead尚未处理部分的size
int remain = READ_MAX_BUFFER_SIZE - this.dispatchPostion;
// 如果byteBufferRead中还有未处理的字节的时候
if (remain > 0) {
this.byteBufferRead.position(this.dispatchPostion);
this.byteBufferBackup.position(0);
this.byteBufferBackup.limit(READ_MAX_BUFFER_SIZE);
this.byteBufferBackup.put(this.byteBufferRead);
}
this.swapByteBuffer();
// 设置下次写入的位置为之前byteBufferRead尚未处理部分的后面
this.byteBufferRead.position(remain);
this.byteBufferRead.limit(READ_MAX_BUFFER_SIZE);
// 从0开始处理byteBufferRead中的数据
this.dispatchPostion = 0;
}
SYNC_MASTER同步数据到slave
SYNC_MASTER和ASYNC_MASTER传输数据到salve的过程是一致的,只是时机上不一样。SYNC_MASTER接收到producer发送来的消息时候,会同步等待消息也传输到salve。
- master将需要传输到slave的数据构造为GroupCommitRequest交给GroupTransferService
- 唤醒传输数据的线程(如果没有更多数据需要传输的的时候HAClient.run会等待新的消息)
- 等待当前的传输请求完成
// org.apache.rocketmq.store.CommitLog#handleHA
public void handleHA(AppendMessageResult result, PutMessageResult putMessageResult, MessageExt messageExt) {
// 如果是SYNC_MASTER才会同步等待
if (BrokerRole.SYNC_MASTER == this.defaultMessageStore.getMessageStoreConfig().getBrokerRole()) {
HAService service = this.defaultMessageStore.getHaService();
if (messageExt.isWaitStoreMsgOK()) {
// Determine whether to wait
// 存在slave并且slave落后master不能太多
if (service.isSlaveOK(result.getWroteOffset() + result.getWroteBytes())) {
GroupCommitRequest request = new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes());
service.putRequest(request);
// 唤醒可能等待新的消息数据的传输数据线程
service.getWaitNotifyObject().wakeupAll();
// 等待当前的消息被传输到slave,等待slave收到该消息的确认之后则flushOK=true
boolean flushOK =
request.waitForFlush(this.defaultMessageStore.getMessageStoreConfig().getSyncFlushTimeout());
if (!flushOK) {
log.error("do sync transfer other node, wait return, but failed, topic: " + messageExt.getTopic() + " tags: "
+ messageExt.getTags() + " client address: " + messageExt.getBornHostNameString());
putMessageResult.setPutMessageStatus(PutMessageStatus.FLUSH_SLAVE_TIMEOUT);
}
}
// Slave problem
else {
// Tell the producer, slave not available
putMessageResult.setPutMessageStatus(PutMessageStatus.SLAVE_NOT_AVAILABLE);
}
}
}
}
在HAService启动的时候会启动GroupTransferService线程,GroupTransferService并没有真正的传输数据,传数据还是上面一节说的传输方式,GroupTransferService只是将push2SlaveMaxOffset和需要传输到slave的消息的offset比较,如果
push2SlaveMaxOffset > req.getNextOffset()
则说明slave已经收到该消息,这个时候就会通知request,消息已经传输完成。
push2SlaveMaxOffset这个字段表示当前slave收到消息的最大的offset,每次master收到slave的ACK之后会更新这个值。
冗余之后消息怎么读取
broker实现冗余之后,就有多个消息副本了,那么consumer怎么知道究竟是从master读取消息还是从slave读取消息呢?
从前面我们知道consumer通过负载均衡算法计算出本次消息从哪一个MessageQueue消费,但是MessageQueue只决定了从哪一个broker set下的哪一个queue消费消息,并不能确定具体的broker,但是在发送pull请求的时候会确定具体的broker
// org.apache.rocketmq.client.impl.consumer.PullAPIWrapper#pullKernelImpl
public PullResult pullKernelImpl(
final MessageQueue mq,
final String subExpression,
final String expressionType,
final long subVersion,
final long offset,
final int maxNums,
final int sysFlag,
final long commitOffset,
final long brokerSuspendMaxTimeMillis,
final long timeoutMillis,
final CommunicationMode communicationMode,
final PullCallback pullCallback
) throws MQClientException, RemotingException, MQBrokerException, InterruptedException {
FindBrokerResult findBrokerResult =
this.mQClientFactory.findBrokerAddressInSubscribe(mq.getBrokerName(),
this.recalculatePullFromWhichNode(mq), false);
if (null == findBrokerResult) {
this.mQClientFactory.updateTopicRouteInfoFromNameServer(mq.getTopic());
findBrokerResult =
this.mQClientFactory.findBrokerAddressInSubscribe(mq.getBrokerName(),
this.recalculatePullFromWhichNode(mq), false);
}
// 省略部分代码...
}
上面调用recalculatePullFromWhichNode来计算从哪一个broker来消费消息
// org.apache.rocketmq.client.impl.consumer.PullAPIWrapper#recalculatePullFromWhichNode
public long recalculatePullFromWhichNode(final MessageQueue mq) {
if (this.isConnectBrokerByUser()) {
// org.apache.rocketmq.client.impl.consumer.PullAPIWrapper#connectBrokerByUser配置为true的时候会从msater读取
return this.defaultBrokerId;
}
// pullFromWhichNodeTable这个数据结构保存的是broker返回的建议从哪一个broker读取消息的信息
AtomicLong suggest = this.pullFromWhichNodeTable.get(mq);
if (suggest != null) {
return suggest.get();
}
// 如果没有建议的broker,则默认从master消费
return MixAll.MASTER_ID;
}
上面可以看出如果没有建议的broker则从master消费,那么就要看看哪些情况下会有建议的broker?会有哪些建议的broker?
要解决这两个问题需要回到broker处理producer发来的消息的时候:
// org.apache.rocketmq.broker.processor.PullMessageProcessor#processRequest(io.netty.channel.Channel, org.apache.rocketmq.remoting.protocol.RemotingCommand, boolean)
private RemotingCommand processRequest(final Channel channel, RemotingCommand request, boolean brokerAllowSuspend)
throws RemotingCommandException {
// 省略部分代码...
if (getMessageResult != null) {
// 省略部分代码...
// 如果slave配置了可读
if (this.brokerController.getBrokerConfig().isSlaveReadEnable()) {
// consume too slow ,redirect to another machine
// 如果读取消息的时候发现consumer消费的太慢就会建议从slave读取消息
if (getMessageResult.isSuggestPullingFromSlave()) {
responseHeader.setSuggestWhichBrokerId(subscriptionGroupConfig.getWhichBrokerWhenConsumeSlowly());
}
// consume ok
else {
// 如果没有消费过慢的问题则依然建议从本broker消费
responseHeader.setSuggestWhichBrokerId(subscriptionGroupConfig.getBrokerId());
}
} else {
// 如果slave不允许读取消息则从master读取
responseHeader.setSuggestWhichBrokerId(MixAll.MASTER_ID);
}
// 省略部分代码...
case ResponseCode.PULL_OFFSET_MOVED:
if (this.brokerController.getMessageStoreConfig().getBrokerRole() != BrokerRole.SLAVE
|| this.brokerController.getMessageStoreConfig().isOffsetCheckInSlave()) {
// 省略部分代码...
} else {
// 如果当前broker是slave并且消费消息的offset在broker中没有找到的时候
// 建议consumer再次向这个broker发送请求重试,
responseHeader.setSuggestWhichBrokerId(subscriptionGroupConfig.getBrokerId());
response.setCode(ResponseCode.PULL_RETRY_IMMEDIATELY);
// 省略部分代码...
}
org.apache.rocketmq.common.protocol.header.PullMessageResponseHeader#suggestWhichBrokerId字段就是最后返回给consumer的建议的brokerId,最后会被存入字段:org.apache.rocketmq.client.impl.consumer.PullAPIWrapper#pullFromWhichNodeTable
结合上面的代码broker会返回给consumer建议的brokerId的情况有以下几种:
- 如果slave可读并且当前broker消费过慢的时候:如果没有配置org.apache.rocketmq.common.subscription.SubscriptionGroupConfig#whichBrokerWhenConsumeSlowly的时候,默认是返回brokerId时1 的broker
- 如果slave可读并且当前broker消费正常的时候:返回当前的broker
- 如果slave不可读的时候:返回master
- 如果当前broker是slave并且需要消费消息的offset不在合理范围(broker没有消息的时候或offset > maxOffset或offset < minOffset)的时候:返回当前slave
所以consumer一开始是从master消费消息的,如果出现消费消费过慢的情况,consumer就会从slave(如果slave配置为可读)消费。
关于消息消费过慢的说明:
RocketMQ是根据以下两个值进行判断的:
a = 当前CommitLog的maxOffset - 需要消费消息的offset的结果
b = RocketMQ可用内存的大小
如果a > b则判断为消息消费过慢,a > b表示需要消费的消息一定不在内存中了,还需要读取文件,这样会给还需要写消息的broker带来一定的性能压力,所以这个时候master建议从slave读取消息。
RocketMQ源码 — 七、 RocketMQ高可用(2)的更多相关文章
- Linux源码安装RabbitMQ高可用集群
1.环境说明 linux版本:CentOS Linux release 7.9.2009 erlang版本:erlang-24.0 rabbitmq版本:rabbitmq_server-3.9.13 ...
- RocketMQ源码 — 六、 RocketMQ高可用(1)
高可用究竟指的是什么?请参考:关于高可用的系统 RocketMQ做了以下的事情来保证系统的高可用 多master部署,防止单点故障 消息冗余(主从结构),防止消息丢失 故障恢复(本篇暂不讨论) 那么问 ...
- RocketMQ源码详解 | Broker篇 · 其五:高可用之主从架构
概述 对于一个消息中间件来讲,高可用功能是极其重要的,RocketMQ 当然也具有其对应的高可用方案. 在 RocketMQ 中,有主从架构和 Dledger 两种高可用方案: 第一种通过主 Brok ...
- 读完 RocketMQ 源码,我学会了如何优雅的创建线程
RocketMQ 是一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时.高可靠的消息发布与订阅服务. 这篇文章,笔者整理了 RocketMQ 源码中创建线程的几点技巧,希望大家读完之后,能 ...
- 源码分析 RocketMQ DLedger(多副本) 之日志复制(传播)
目录 1.DLedgerEntryPusher 1.1 核心类图 1.2 构造方法 1.3 startup 2.EntryDispatcher 详解 2.1 核心类图 2.2 Push 请求类型 2. ...
- 【RocketMQ源码学习】- 4. Client 事务消息源码解析
介绍 > 基于4.5.2版本的源码 1. RocketMQ是从4.3.0版本开始支持事务消息的. 2. RocketMQ的消息队列能够保证生产端,执行数据和发送MQ消息事务一致性,而消费端的事务 ...
- RocketMQ 源码分析 —— Message 发送与接收
1.概述 Producer 发送消息.主要是同步发送消息源码,涉及到 异步/Oneway发送消息,事务消息会跳过. Broker 接收消息.(存储消息在<RocketMQ 源码分析 —— Mes ...
- 【RocketMQ源码分析】深入消息存储(3)
前文回顾 CommitLog篇 --[RocketMQ源码分析]深入消息存储(1) ConsumeQueue篇 --[RocketMQ源码分析]深入消息存储(2) 前面两篇已经说过了消息如何存储到Co ...
- RocketMQ源码详解 | Producer篇 · 其二:消息组成、发送链路
概述 在上一节 RocketMQ源码详解 | Producer篇 · 其一:Start,然后 Send 一条消息 中,我们了解了 Producer 在发送消息的流程.这次我们再来具体下看消息的构成与其 ...
随机推荐
- View绘制流程
1. View 树的绘图流程 当 Activity 接收到焦点的时候,它会被请求绘制布局,该请求由 Android framework 处理.绘制是从根节点开始,对布局树进行 measure 和 dr ...
- 牛腩新闻发布系统--学习Web的小技巧汇总
2014年11月10日,是个难忘的日子,这一天,小编的BS学习开始了,BS的开头,从牛腩新闻发布系统开始,之前学习的内容都是CS方面的知识,软考过后,开始学习BS,接触BS有几天的时间了,跟着牛腩老师 ...
- LINUX0.11 内核阅读笔记
一.源码目录 图1 二.系统总体流程: 系统从boot开始动作,把内核从启动盘装到正确的位置,进行一些基本的初始化,如检测内存,保护模式相关,建立页目录和内存页表,GDT表,IDT表.然后进入main ...
- Uva - 12174 - Shuffle
用滑动窗口的思想,用一个数组保存每个数在窗口中出现的次数.再用一个变量记录在窗口中恰好出现一次的的数的个数,这样可以枚举所有可能的答案,判断它所对应的所有串口,当且仅当所有的串口均满足要求时这个答案可 ...
- 基于Struts+Hibernate开发过程中遇到的错误
1.import javax.servlet.http.HttpServletRequest 导入包出错 导入包出错,通常是包未引入,HttpServletRequest包是浏览器通过http发出的 ...
- struts2 令牌 实现源代码 JSP
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"% ...
- Cygwin获取root权限
.启动cygwin进入以后,就会以真正的root权限运行了.
- XBMC源代码分析 1:整体结构以及编译方法
XBMC(全称是XBOX Media Center)是一个开源的媒体中心软件.XBMC最初为Xbox而开发,可以运行在Linux.OSX.Windows.Android4.0系统.我自己下载了一个然后 ...
- 华为机试题【10】-求数字基root
题目描述: 求整数的Root:给定正整数,求每位数字之和;如果和不是一位数,则重复; 输入:输入任意一个或多个整数 输出:输出各位数字之和,直到和为个位数为止(输入异常,则返回-1),多行,每行对应一 ...
- android沉浸式状态栏的实现
在style.xml中添加 [html] view plaincopy <style name="Theme.Timetodo" parent="@android: ...