Elastic Stack-Elasticsearch使用介绍(三)
一、前言
上一篇说了这篇要讲解Search机制,但是在这个之前我们要明白下文件是怎么存储的,我们先来讲文件的存储然后再来探究机制;
二、文档存储
之前说过文档是存储在分片上的,这里要思考一个问题:文档是通过什么方式去分配到分片上的?我们来思考如下几种方式:
1.通过文档与分片取模实现,这样做的好处在于可以将文档平均分配到所以的分片上;
2.随机分配当然也可以,这种可能造成分配不均,照成空间浪费;
3.轮询这种是最不可取的,采用这种你需要建立文档与分片的映射关系,这样会导致成本太大;
经过一轮强烈的思考,我们选择方案1,没错你想对了,这里Elasticsearch也和我们思考的是一样的,我们来揭露下他分配的公式:
shard_num = hash(_routing)%num_primary_shards
routing是一个关键参数,默认是文档id,可以自行指定;
number_of_primary_shard 主分片数;
之前我们介绍过节点的类型,接下来我们来介绍下,当文档创建时候的流程:
假设的情况:1个主节点和2个数据节点,1个副本:
文档的创建:
1.客户端向节点发起创建文档的请求;
2.通过routing计算文档存储的分片,查询集群确认分片在数据节点1上,然后转发文档到数据节点1;
3.数据节点1接收到请求创建文档,同时发送请求到该住分片的副本;
4.主分片的副本接收到请求则开始创建文档;
5.副本分片文档完成以后发送成功的通知给主分片;
6.当主分片接收到创建完成的信息以后,发送给节点创建成功的通知;
7.节点返回结果给客户端;
三、Search机制
搜索的类型其实有2种:Query Then Ferch和DFS Query Then Ferch,当我们明白如何存储文件的是时候,再去理解这两种查询方式会很简单;
Query Then Ferch
Search在执行的时候分为两个步骤运作Query(查询)和Fetch(获取),基本流程如下:
1.将查询分配到每个分片;
2.找到所有匹配的文档,并在当前的分片的文档使用Term/Document Frequency信息进行打分;
3.构建结果的优先级队列(排序,分页等);
4.将结果的查询到的数据返回给请求节点。请注意,实际文档尚未发送,只是分数;
5.将所有分片的分数在请求节点上合并和排序,根据查询条件选择文档;
6.最后从筛选出的文档所在的各个分片中检索实际的文档;
7.结果将返回给客户端;
DFS Query Then Ferch
DFS是在进行真正的查询之前, 先把各个分片的词频率和文档频率收集一下, 然后进行词搜索的时候, 各分片依据全局的词频率和文档频率进行搜索和排名,基本流程如下:
1.提前查询每个shard,询问Term和Document frequency;
2.将查询分配到每个分片;
3.找到所有匹配到的文档,并且在所有分片的文档使用Term/Document Frequency信息进行打分;
4.构建结果的优先级队列(排序,分页等);
5.将结果的查询到的数据返回给请求节点。请注意,实际文档尚未发送,只是分数;
6.来自所有分片的分数合并起来,并在请求节点上进行排序,文档被按照查询要求进行选择;
7.最终,实际文档从他们各自所在的独立的分片上检索出来;
8.结果被返回给客户端;
总结下,根据上面的两种查询方式来看的DFS查询得分明显会更接近真实的得分,但是DFS 在拿到所有文档后再从新完整的计算一次相关性算分,耗费更多的cpu和内存,执行性能也比较低下,一般不建议使用。使用方式如下:

另外要是当文档数据不多的时候可以考虑使用一个分片;
这个地方我们在做一些深入的思考:我们搜索的时候是通过倒排索引,但是倒排索引一旦建立是不能修改的,这样做有那些好处坏处?
好处:
1.不用考虑并发写入文件的问题,杜绝锁机制带来的性能问题;
2.文件不再更改,可以充分利用文件系统缓存,只需载入一次,只要内容足够,对该文件的读取都会从内存中读取,性能高;
坏处:
写入新文档时,必须重新构建倒排索引文件,然后替换老文件后,新文档才能被检索,导致文档实时性差;
问题:
对于新插入文档的时候写入倒排索引,导致倒排索引重建的问题,假如根据新文档来重新构建倒排索引文件,然后生成一个新的倒排索引文件,再把用户的原查询切掉,切换到新的倒排索引。这样开销会很大,会导致实时性非常差。
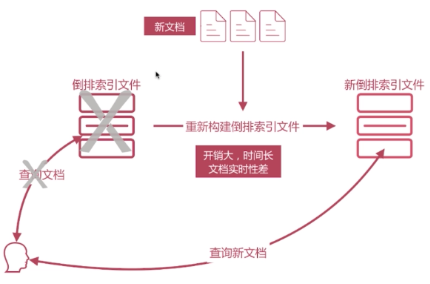
Elasticsearch如何解决文件搜索的实时性问题:

新文档直接生成新的倒排索引文件,查询的时候同时查询所有的倒排文件,然后做结果的汇总计算即可,ES是是通过Lucene构建的,Lucene就是通过这种方案处理的,我们介绍下Luncene构建文档的时候的结构:
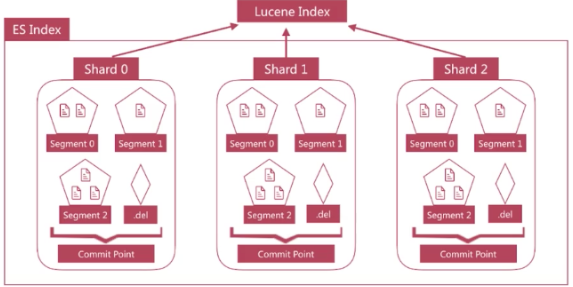
1.Luncene中单个倒排索引称为Segment,合在一起称为Index,这个Index与Elasticsearch概念是不相同的,Elasticsearch中的每个Shard对应一个Lucene Index;
2.Lucene会有个专门文件来记录所有的Segment信息,称为Commit Point,用来维护Segment的信息;
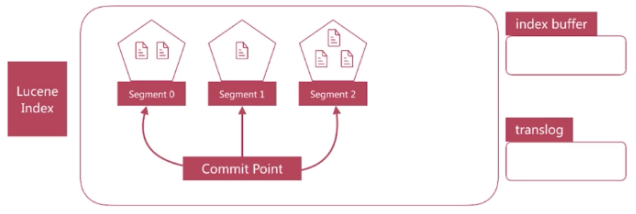
Segment写入磁盘的时候过程中也是比较慢的,Elasticsearch提供一个Refresh机制,是通过文件缓存的机制实现的,接下我们介绍这个过程:
1.在refresh之前的文档会先存储在一个Buffer里面,refresh时将Buffer中的所有文档清空,并生成Segment;
2.Elasticsearch默认每1秒执行一次refresh,因此文档的实时性被提高到1秒,这也是Elasticsearch称为近实时(Near Real Time)的原因;
Segment写入磁盘前如果发生了宕机,那么其中的文档就无法恢复了,怎么处理这个问题?
Elasticsearch引入translog(事务日志)机制,translog的写入也可以设置,默认是request,每次请求都会写入磁盘(fsync),这样就保证所有数据不会丢,但写入性能会受影响;如果改成async,则按照配置触发trangslog写入磁盘,注意这里说的只是trangslog本身的写盘。Elasticsearch启动时会检查translog文件,并从中恢复数据;
还有一种机制flush机制,负责将内存中的segment写入磁盘和删除旧的translog文件;
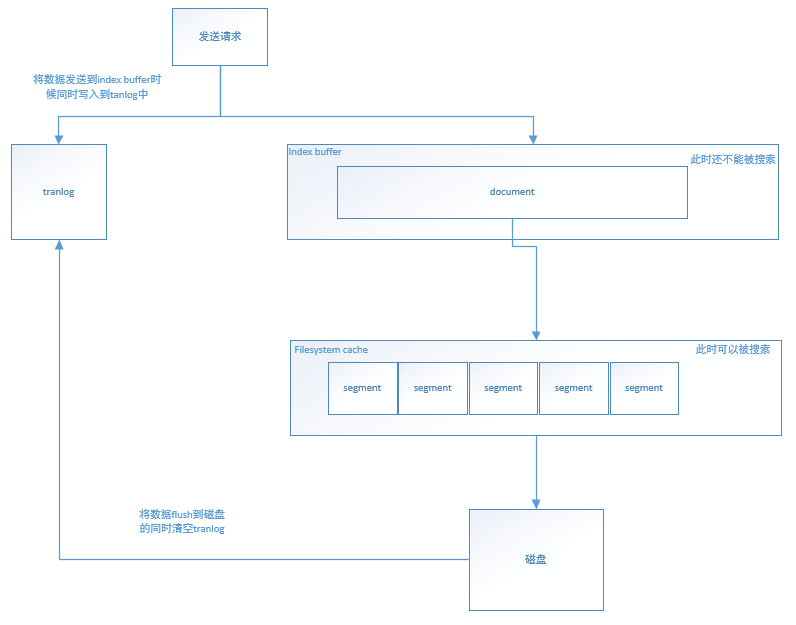
新增的时候搞定了,那删除和更新怎么办?
删除的时候,Lucene专门维护一个.del文件,记录所有已经删除的文档,del文件上记录的是文档在Lucene内部的id,查询结果返回前过滤掉.del中的所有文档;
更新就简单了,先删除然后再创建;
随着Segment增加,查询一次会涉及很多,查询速度会变慢,Elasticsearch会定时在后台进行Segment Merge的操作,减少Segment的数量,通过force_merge api可以手动强制做Segment Merge的操作;
另外可以参考下这篇文段合并;
四、下节预告
本来还想说下聚合、排序方面的查询,但是看篇幅也差不多了,留点时间出去浪,最近不光要撒狗粮,也要撒知识,国庆节期间准备完成Elastic Stack系列,下面接下来还会有4-5篇左右,欢迎大家加群438836709,欢迎大家关注我公众号!

Elastic Stack-Elasticsearch使用介绍(三)的更多相关文章
- Elastic Stack之ElasticSearch分布式集群二进制方式部署
Elastic Stack之ElasticSearch分布式集群二进制方式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家都知道ELK其实就是Elasticsearc ...
- Elastic Stack之ElasticSearch分布式集群yum方式搭建
Elastic Stack之ElasticSearch分布式集群yum方式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搜索引擎及Lucene基本概念 1>.什么 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- Elastic Stack核心产品介绍-Elasticsearch、Logstash和Kibana
Elastic Stack 是一系列开源产品的合集,包括 Elasticsearch.Kibana.Logstash 以及 Beats 等等,能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地 ...
- ES 集中式日志分析平台 Elastic Stack(介绍)
一.ELK 介绍 ELK 构建在开源基础之上,让您能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地对数据进行搜索.分析和可视化. 最近查看 ELK 官方网站,发现新一代的日志采集器 File ...
- 集中式日志分析平台 Elastic Stack(介绍)
一.ELK 介绍 二.ELK的几种常见架构 >>ELK 介绍<< ELK 构建在开源基础之上,让您能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地对数据进行搜索.分析 ...
- 浅尝 Elastic Stack (一) Elasticsearch、Kibana、Beats 安装
Elastic Stack 包括 Elasticsearch.Kibana.Beats 和 Logstash,也称为 ELK Stack.能够安全可靠地获取任何来源.任何格式的数据,然后实时地对数据进 ...
- Elastic Stack(ElasticSearch 、 Kibana 和 Logstash) 实现日志的自动采集、搜索和分析
Elastic Stack 包括 Elasticsearch.Kibana.Beats 和 Logstash(也称为 ELK Stack).能够安全可靠地获取任何来源.任何格式的数据,然后实时地对数据 ...
- 三十八 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticse ...
随机推荐
- IM开发者的零基础通信技术入门(一):通信交换技术的百年发展史(上)
[来源申明]本文原文来自:微信公众号“鲜枣课堂”,官方网站:xzclass.com,原题为:<通信交换的百年沧桑(上)>,本文引用时已征得原作者同意.为了更好的内容呈现,即时通讯网在收录时 ...
- Javascript高级编程学习笔记(95)—— WebGL(1) 类型化数组
WebGL webgl 是针对 canvas 的 3D上下文,与其它Web技术不同,WebGL并非是W3C制定的标准,而是由 Khronos Group 制定的. 类型化数组 WebGL所涉及的复杂运 ...
- 使用 Parallels Destop 最小化安装 centOS 操作系统
1. 环境准备 macOS 操作系统 Parallels Destop 13 CentOS 7.6 Minimal ISO 镜像文件 2. 新建操作系统 选择下载好的 CentosOS 7.6 即 C ...
- dubbo 序列化机制之 hessian2序列化实现原理分析
对于远程通信,往往都会涉及到数据持久化传输问题.往大了说,就是,从A发出的信息,怎样能被B接收到相同信息内容!小点说就是,编码与解码问题! 而在dubbo或者说是java的远程通信中,编解码则往往伴随 ...
- 使用Visual Studio Code开发.NET Core看这篇就够了
作者:依乐祝 原文地址:https://www.cnblogs.com/yilezhu/p/9926078.html 在本文中,我将带着大家一步一步的通过图文的形式来演示如何在Visual Studi ...
- Win32对话框程序(1)
之前学C语言是一直都是在控制台下面操作的,面对的都是黑框框,严重的打击了学习的兴趣.后来在TC下进行C语言课程设计,做了图形界面编程,但都是点线面画的…… 中间隔了好长一段时间没有碰过C语言,最近才开 ...
- API接口通讯参数规范
通常在很多的公司里面,对于接口的返回值没做太大规范,所以会比较常看到各个项目各自定义随意的返回值,比如以下情况: 1. 直接返回bool值(True或者False) 2. 返回void,只要不是异常信 ...
- 认识JWT
1. JSON Web Token是什么 JSON Web Token (JWT)是一个开放标准(RFC 7519),它定义了一种紧凑的.自包含的方式,用于作为JSON对象在各方之间安全地传输信息.该 ...
- RESTful API接口文档规范小坑
希望给你3-5分钟的碎片化学习,可能是坐地铁.等公交,积少成多,水滴石穿,谢谢关注. 前后端分离的开发模式,假如使用的是基于RESTful API的七层通讯协议,在联调的时候,如何避免配合过程中出现问 ...
- Scss预处理器的使用总结
变量 .嵌套.Mixin混合.function函数.插值 变量及文件导入 通过$定义变量 $white:#fff; $black:#000; 变量引用 .containner{ color:$blac ...