二十一、Hadoop学记笔记————kafka的初识

这些场景的共同点就是数据由上层框架产生,需要由下层框架计算,其中间层就需要有一个消息队列传输系统

Apache flume系统,用于日志收集
Apache storm系统,用于实时数据处理
Spark系统,用于内存数据处理
elasticsearch系统,用于全文检索
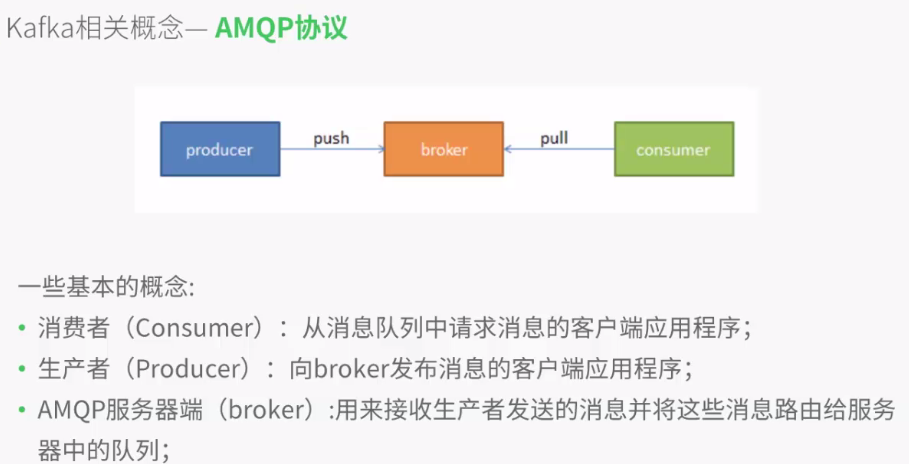
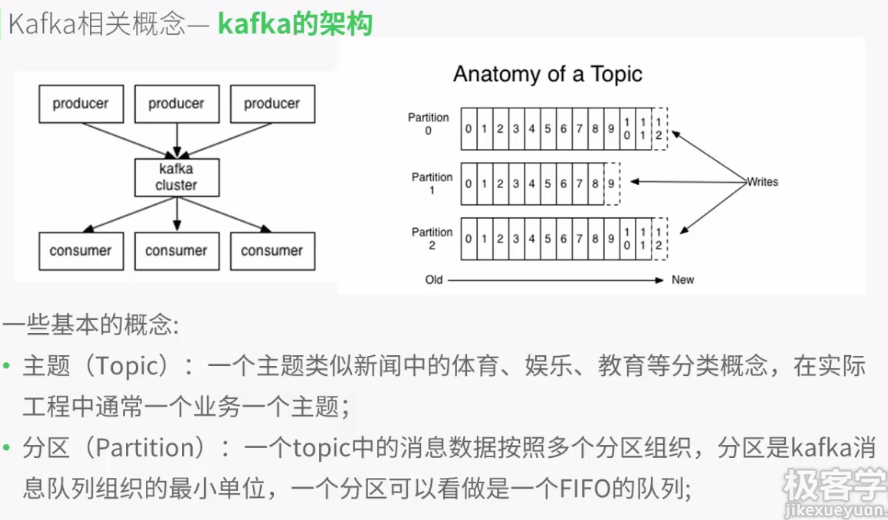

broker中每个partition都会有备份,可自行设置,前端程序和读取数据的程序都可以是自己写的程序或者是各类框架,例如hadoop,flume
搭建集群:

kafka的包需要事先下载好,zookeeper环境搭建之前已经做过介绍:
新建一个目录专门给kafka使用,这样方便管理,先解压每个服务器的kafka,然后在kafka目录下新建一个Log文件夹,用于存放kafka的消息

进入kafka的配置目录,发现还有zookeeper配置文件,kafka集群可以通过zookeeper启动,但是一般通过自己独立的启动方式启动
首先关注server.properties配置文件
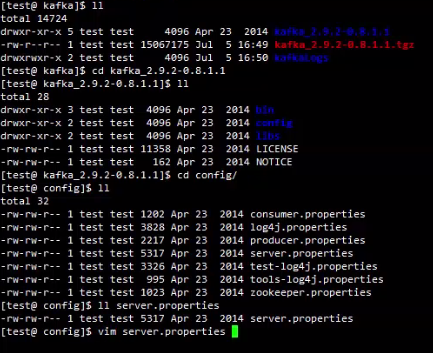
当前服务器集群ip分别为10.206.216.13,10.206.212.14,10.46.189.18
id为每个服务器的唯一参数,默认端口9092,为了防止会发生冲突,可以将端口设置比较大一点
hostname为服务器ip地址,一般该参数是关闭的,在0.8.1中有bug,默认参数是localhost,kafka在解析dns的时候会解析成ip,会有失败率,因此打开,之后的版本已经修复该bug。若修改了hosts名称也可以直接写名称:
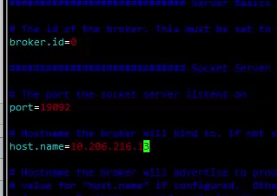
之后配置如下三项:分别为消息put字节数组大小,消息备份数和消息pull字节数组大小,图中两个字节数组大小都为5M

之后配置zookeeper集群地址,zookeeper集群默认端口为2181,为了防止端口冲突,可以改为12181,该操作可有可无:

配置log路径,若有多个可用逗号分隔,如果有多个的话,那num.io.threads参数的值必须大于配置路径的个数:

在每台服务器都配置完毕后,分别启动kafka集群:
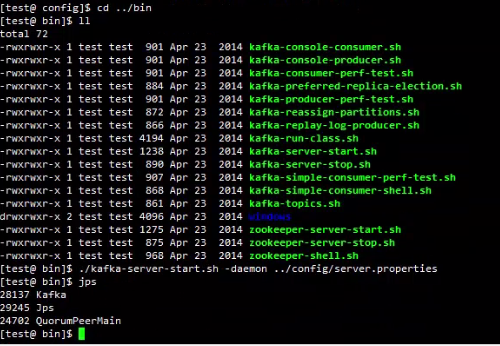
之后验证有没有错误:
先在集群上建立topic,即消息发送方,然后设置一台服务器为消息发送方producer,设置另一台服务器为consumer订阅该服务器:



在producer中发送hello消息,然后在consumer中可立即收到:


之后还有list指令和descrip指令,分别用于列出所有的topic和某个topic的描述,之后还有许多指令,需要查看官方文档:

进入zookeeper命令行之后,发现有如下目录被创建:


二十一、Hadoop学记笔记————kafka的初识的更多相关文章
- 二十二、Hadoop学记笔记————Kafka 基础实战 :消费者和生产者实例
kafka的客户端也支持其他语言,这里主要介绍python和java的实现,这两门语言比较主流和热门 图中有四个分区,每个图形对应一个consumer,任意一对一即可 获取topic的分区数,每个分区 ...
- 二十三、Hadoop学记笔记————Spark简介与计算模型
spark优势在于基于内存计算,速度很快,计算的中间结果也缓存在内存,同时spark也支持streaming流运算和sql运算 Mesos是资源管理框架,作为资源管理和任务调度,类似Hadoop中的Y ...
- 二十、Hadoop学记笔记————Hive On Hbase
Hive架构图: 一般用户接口采用命令行操作, hive与hbase整合之后架构图: 使用场景 场景一:通过insert语句,将文件或者table中的内容加入到hive中,由于hive和hbase已经 ...
- 二十五、Hadoop学记笔记————Hive复习与深入
Hive主要为了简化MapReduce流程,使非编程人员也能进行数据的梳理,即直接使用sql语句代替MapReduce程序 Hive建表的时候元数据(表明,字段信息等)存于关系型数据库中,数据存于HD ...
- 二十四、Hadoop学记笔记————Spark的架构
master为主节点 一个集群中可能运行多个application,因此也可能会有多个driver DAG Scheduler就是讲RDD Graph拆分成一个个stage 一个Task对应一个Spa ...
- 十九、Hadoop学记笔记————Hbase和MapReduce
概要: hadoop和hbase导入环境变量: 要运行Hbase中自带的MapReduce程序,需要运行如下指令,可在官网中找到: 如果遇到如下问题,则说明Hadoop的MapReduce没有权限访问 ...
- 十七、Hadoop学记笔记————Hbase入门
简而言之,Hbase就是一个建立在Hdfs文件系统上的数据库(mysql,orecle等),不同的是Hbase是针对列的数据库 Hbase和普通的关系型数据库区别如下: Hbase有一些基本的术语,主 ...
- 十八、Hadoop学记笔记————Hbase架构
Hbase结构图: Client,Zookeeper,Hmaster和HRegionServer相互交互协调,各个组件作用如下: 这几个组件在实际使用过程中操作如下所示: Region定位,先读取zo ...
- 学记笔记 $\times$ 巩固 · 期望泛做$Junior$
最近泛做了期望的相关题目,大概\(Luogu\)上提供的比较简单的题都做了吧\(233\) 好吧其实是好几天之前做的了,不过因为太颓废一直没有整理-- \(Task1\) 期望的定义 在概率论和统计学 ...
随机推荐
- windows下程序启动检查,只启动一个实例
问题来源:http://bbs.csdn.net/topics/390998279?page=1#post-398983061 // Only_once.cpp : 定义控制台应用程序的入口点. // ...
- Android开发常用网站汇总
1.eoe Android开发者论坛 目前国内最早的Android开发者社区,人气非常旺聚集了不少Android开发方面的高手,开发中遇到的问题大都能在这里获得解决,网站最大的特色是定期发布<e ...
- HOW TO LINK THE TRANSACTION_SOURCE_ID TO TRANSACTION_SOURCE_TYPE_ID
In this Document Goal Solution References APPLIES TO: Oracle Inventory Management - Version 11 ...
- "《算法导论》之‘图’":不带权二分图最大匹配(匈牙利算法)
博文“二分图的最大匹配.完美匹配和匈牙利算法”对二分图相关的几个概念讲的特别形象,特别容易理解.本文介绍部分主要摘自此博文. 还有其他可参考博文: 趣写算法系列之--匈牙利算法 用于二分图匹配的匈牙利 ...
- Android特效专辑(八)——实现心型起泡飞舞的特效,让你的APP瞬间暖心
Android特效专辑(八)--实现心型起泡飞舞的特效,让你的APP瞬间暖心 马上也要放年假了,家里估计会没网,更完这篇的话,可能要到年后了,不过在此期间会把更新内容都保存在本地,这样有网就可以发表了 ...
- Android Binder IPC详解-Android学习之旅(96)
linux内存空间与BInder Driver Android进程和linux进程一样,他们只运行在进程固有的虚拟空间中.一个4GB的虚拟地址空间,其中3GB是用户空间,1GB是内核空间 ,用户空间是 ...
- 【14】-java的单例设计模式详解
预加载模式 代码: public class Singleton { private volatile static Singleton singleton = new Singleton(); pr ...
- 和菜鸟一起学linux之linux性能分析工具oprofile移植
一.内核编译选项 make menuconfig General setup---> [*] Profiling support <*> OProfile system profil ...
- ELF 文件 动态链接 - 地址无关代码(GOT)
Linux 系统中,ELF动态链接文件被称为 动态共享对象(DSO,Dynamic Shared Object),简称共享对象 文件拓展名为".so" 动态链接下 一个程序可以被分 ...
- 添加极光推送以及在ios中的问题
项目为 ionic1 + angular1 1.添加极光推送插件 用cordova进行添加 cordova plugin add jpush-phonegap-plugin --variable AP ...