分布式计算框架-MapReduce 基本原理(MP用于分布式计算)
hadoop最主要的2个基本的内容要了解。上次了解了一下HDFS,本章节主要是了解了MapReduce的一些基本原理。
MapReduce文件系统:它是一种编程模型,用于大规模数据集(大于1TB)的并行运算。MapReduce将分为两个部分:Map(映射)和Reduce(归约)。
当你向mapreduce框架提交一个计算作业,它会首先把计算作业分成若干个map任务,然后分配到不同的节点上去执行,每一个map任务处理输入数据中的一部分,当map任务完成后,它会生成一些中间文件,这些中间文件将会作为reduce任务的输入数据。Reduce任务的主要目标就是把前面若干个map的数据汇总到一起并输出。
MapReduce的体系结构:
主从结构:主节点,只有一个:JobTracker;从节点,有很多个:Task Trackers
JobTracker负责:接收客户提交的计算任务;把计算任务分给Task Trackers执行;监控Task Tracker的执行情况;
Task Trackers负责:执行JobTracker分配的计算任务。
MapReduce是一种分布式计算模型,由google提出,主要用于搜索领域,解决海量数据的计算问题。
MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算,非常简单。
这两个函数的形参是key、value,表示函数的输入信息。
MapReduce执行流程:
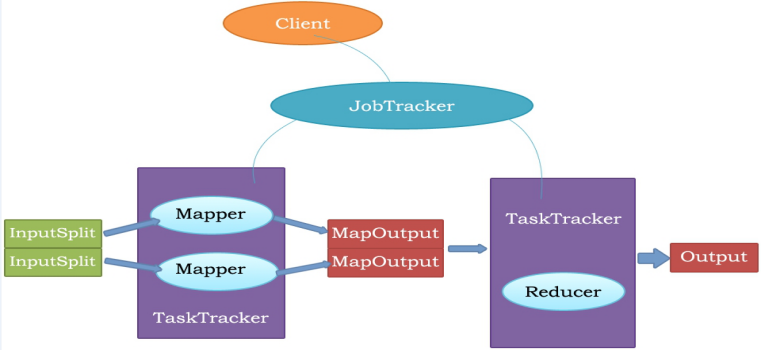
MapReduce原理:
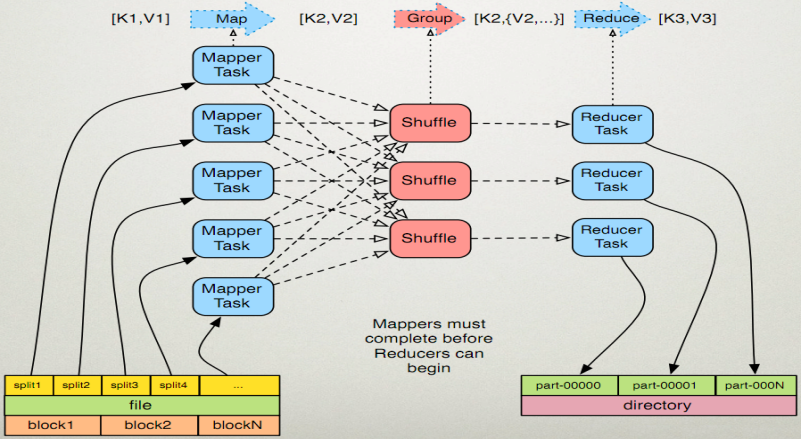
执行步骤:
1. map任务处理
1.1 读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。
1.2 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
1.3 对输出的key、value进行分区。
1.4 对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中。
1.5 (可选)分组后的数据进行归约。
2.reduce任务处理
2.1 对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
2.2 对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
2.3 把reduce的输出保存到文件中。
例子:实现WordCountApp
map、reduce键值对格式
|
函数 |
输入键值对 |
输出键值对 |
|
map() |
<k1,v1> |
<k2,v2> |
|
reduce() |
<k2,{v2}> |
<k3,v3> |
JobTracker
负责接收用户提交的作业,负责启动、跟踪任务执行。
JobSubmissionProtocol是JobClient与JobTracker通信的接口。
InterTrackerProtocol是TaskTracker与JobTracker通信的接口。
TaskTracker
负责执行任务
JobClient
是用户作业与JobTracker交互的主要接口。
负责提交作业的,负责启动、跟踪任务执行、访问任务状态和日志等。
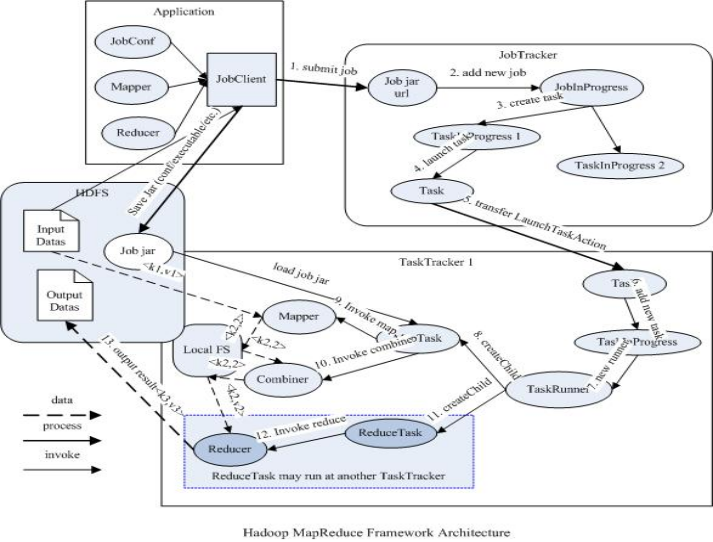
MapReduce驱动默认的设置
|
InputFormat(输入) |
TextInputFormat |
|
MapperClass(map类) |
IdentityMapper |
|
MapOutputKeyClass |
LongWritable |
|
MapOutputValueClass |
Text |
|
PartitionerClass |
HashPartitioner |
|
ReduceClass |
IdentityReduce |
|
OutputKeyClass |
LongWritable |
|
OutputValueClass |
Text |
|
OutputFormatClass |
TextOutputFormat |
序列化的概念:
序列化(Serialization)是指把结构化对象转化为字节流。
反序列化(Deserialization)是序列化的逆过程。即把字节流转回结构化对象。
Java序列化(java.io.Serializable)
Hadoop-序列化格式特点:
紧凑:高效使用存储空间。
快速:读写数据的额外开销小
可扩展:可透明地读取老格式的数据
互操作:支持多语言的交互
Hadoop的序列化格式:Writable
序列化在分布式环境的两大作用:进程间通信,永久存储。
Hadoop节点间通信。
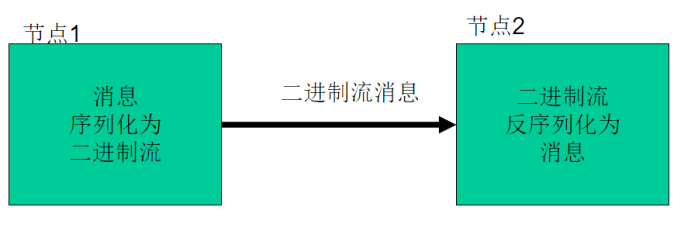
MapReduce输入的处理类:
FileInputFormat:是所有以文件为数据源的InputFormat实现的基类,FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法有不同的子类--TextInputFormat进行实现的。
InPutFormat负责处理MR的输入部分。
InPutFormat的三个作用:
验证作业的输入是否规范
把输入文件切成InputSplit
提供RecordReader的实现类,把InputSplit读到Mapper中进行处理。
FileInputSplit:
◆ 在执行mapreduce之前,原始数据被分割成若干split,每个split作为一个map任务的输入,在map执行过程中split会被分解成一个个记录(key-value对),map会依次处理每一个记录。
◆ FileInputFormat只划分比HDFS block大的文件,所以FileInputFormat划分的结果是这个文件或者是这个文件中的一部分.
◆ 如果一个文件的大小比block小,将不会被划分,这也是Hadoop处理大文件的效率要比处理很多小文件的效率高的原因。
◆ 当Hadoop处理很多小文件(文件大小小于hdfs block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个split并分配一个map任务,导致效率底下。
例如:一个1G的文件,会被划分成16个64MB的split,并分配16个map任务处理,而10000个100kb的文件会被10000个map任务处理。
TextInputFormat:
◆ TextInputformat是默认的处理类,处理普通文本文件。
◆ 文件中每一行作为一个记录,他将每一行在文件中的起始偏移量作为key,每一行的内容作为value。
◆ 默认以\n或回车键作为一行记录。
◆ TextInputFormat继承了FileInputFormat。
InputFormat类的层次结构:

分布式计算框架-MapReduce 基本原理(MP用于分布式计算)的更多相关文章
- Hadoop 三剑客之 —— 分布式计算框架 MapReduce
一.MapReduce概述 二.MapReduce编程模型简述 三.combiner & partitioner 四.MapReduce词频统计案例 4.1 项目简介 ...
- Hadoop 学习之路(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到Hadoop集群上用于并行处理大规模的数据集. MapReduce作业通 ...
- Hadoop 系列(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集. MapReduce ...
- Hadoop整理三(Hadoop分布式计算框架MapReduce)
一.概念 MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算.概念"Map(映射)"和"Reduce(归约)",是它们的主要思想.它极大 ...
- Hadoop整理四(Hadoop分布式计算框架MapReduce)
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提 ...
- 2_分布式计算框架MapReduce
一.mr介绍 1.MapReduce设计理念是移动计算而不是移动数据,就是把分析计算的程序,分别拷贝一份到不同的机器上,而不是移动数据. 2.计算框架有很多,不是谁替换谁的问题,是谁更适合的问题.mr ...
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装 大数据时代之hadoop(二):hadoop脚本解析 大数据时代之hadoop(三):hadoop数据流(生命周期) 大数据时代之hadoop(四): ...
- 分布式计算框架学习笔记--hadoop工作原理
(hadoop安装方法:http://blog.csdn.net/wangjia55/article/details/53160679这里不再累述) hadoop是针对大数据设计的一个计算架构.如果你 ...
- hadoop-MapReduce分布式计算框架
计算框架: MapReduce:主要用于离线计算 Storm:流式计算框架,更适合做实时计算 stack:内存计算框架,快速计算 MapReduce设计理念: --何为分布式计算 --移动计算,而不是 ...
随机推荐
- .net core集成JWT(基础)
关于JWT的基本概念,如果有不清晰的同学,请点击这里,就不在这里赘述了.接下来聊聊JWT是怎么发挥作用的. 第一,安装nuget包 Microsoft.AspNetCore.Authenticatio ...
- [收藏] 传说中的12306买票插件-chrome专用
12306.cn买票,难死了,登录登录登录... 现在不用了... js插件+chrome浏览器: /* * 12306 Auto Query => A javascript snippet t ...
- python 与 百度人脸识别api
用python来做人脸识别代码量少 思路清晰, 在使用之前我们需要在我们的配置的编译器中通过pip install baidu-aip 即可 from aip import AipFac ...
- rgw使用boto3生成可以访问的预签名url
前言 如果想访问一个ceph里面的s3地址,但是又不想直接提供secrect key的时候,可以通过预签名的方式生成url 生成方法 下载boto3 脚本如下 cat s3.py import bot ...
- Cephfs 操作输出到日志查询系统
前言 文件系统当中如果某些文件不见了,有什么办法判断是删除了还是自己不见了,这个就需要去日志里面定位了,通常情况下是去翻日志,而日志是会进行压缩的,并且查找起来非常的不方便,还有可能并没有开启 这个时 ...
- HDU100题简要题解(2040~2049)
HDU2040 亲和数 题目链接 Problem Description 古希腊数学家毕达哥拉斯在自然数研究中发现,220的所有真约数(即不是自身的约数)之和为: 1+2+4+5+10+11+20+2 ...
- 关于Redis的一些思考
1.从Java语言考虑,已经有ConcurrentHashMap等并发集合类了,与Redis相比,区别于差异在哪? 一直有这么个疑问,今天有搜了很久,很巧,搜到个有同样想法的问答,如下: When p ...
- mac实用软件推荐 mac好用的软件
终于入手了梦寐以求的苹果电脑,但却发现其操作系统与Windows大相径庭!不会使用怎么办?不用担心,我们可以借助软件的力量.一款实用的Mac软件不仅能够使你的工作效率显著提高,同时它还能帮助你更快地熟 ...
- css3系列之linear-gradient() repeating-linear-gradient() 和 radial-gradient() repeating-radial-gradient()
linear-gradient() (线性渐变) repeating-linear-gradient() (重复的线性渐变) radial-gradient() (镜像渐变) repeatin ...
- AppWeb认证绕过漏洞(CVE-2018-8715)
AppWeb认证绕过漏洞(CVE-2018-8715) 一.漏洞描述 Appweb简介 Appweb是一个嵌入式HTTP Web服务器,主要的设计思路是安全.这是直接集成到客户的应用和设备,便于开发和 ...