Flink on Yarn三部曲之一:准备工作
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
关于Flink on Yarn三部曲
本文是《Flink on Yarn三部曲》的第一篇,整个系列由以下三篇组成:
- 准备工作:搭建Flink on Yarn环境前,将所有硬件、软件资源准备好;
- 部署和设置:部署CDH和Flink,然后做相关设置
- Flink实战:在Yarn环境提交Flink任务
整个三部曲的实战内容如下图所示:
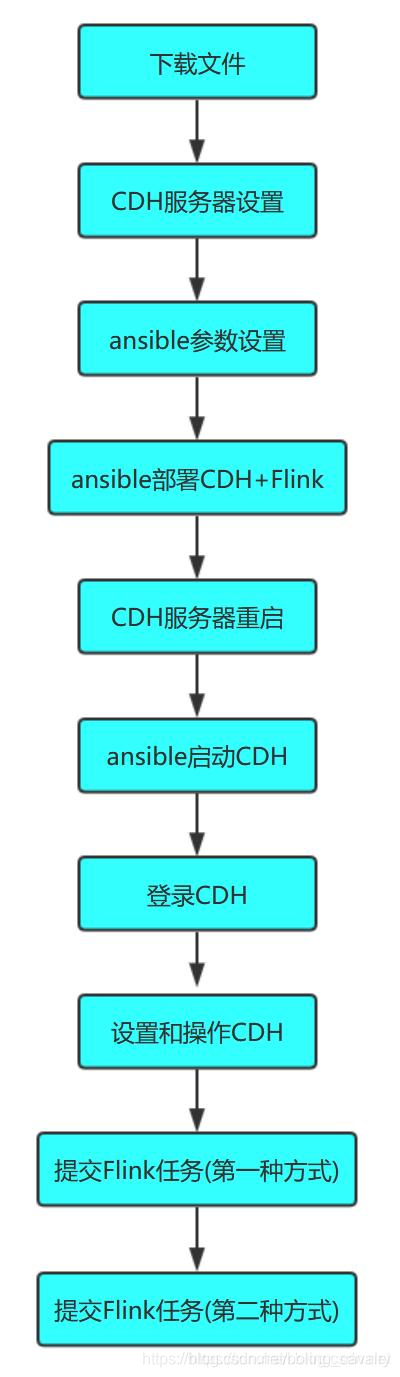
接下来就从最基本的准备工作开始吧。
全文链接
关于Flink on Yarn
除了常见的standalone模式,Flink还支持将任务提交到Yarn环境执行,任务所需的计算资源由Yarn Remource Manager来分配,如下图(来自Flink官网):
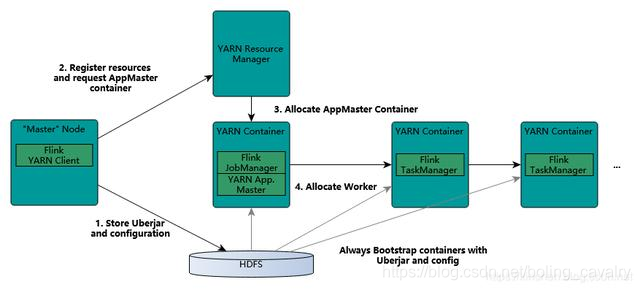
因此需要搭建一套Yarn环境,通过CDH部署Yarn、HDFS等服务是常见方式,接下来就采用此方式来部署;
部署方式
ansible是常用的运维工具,可以大幅度简化整个部署过程,接下来会使用ansible来完成部署工作,如果您对ansible还不够了解,请参考《ansible2.4安装和体验》,部署操作如下图所示,在一台安装了ansible的电脑上运行脚本,由ansible远程连接到一台CentOS7.7的服务器上,完成部署工作:
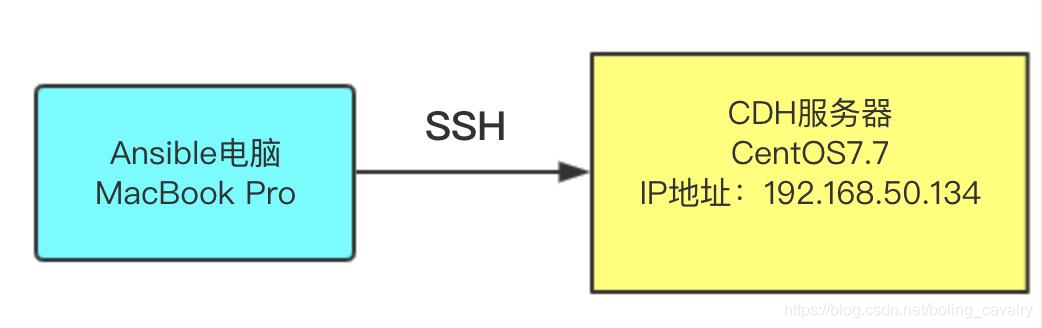
硬件准备
- 一台可以运行ansible的电脑,我这里用的是MacBook Pro,也用CentOS验证过,都可以顺利完成部署;
- 一台CentOS7.7的电脑用于运行Yarn和Flink(文中的CDH服务器就是指该电脑),为了操作简单,本次实战将CDH、Yarn、HDFS、Flink都部署在这一台机器上,实测发现,此电脑CPU至少要双核,内存不低于16G,如果您想用多台电脑部署CDH,建议自行修改ansible脚本来分别部署,脚本地址后面会给出;
软件版本
- ansible电脑操作系统:macOS Catalina 10.15(实测用CentOS也能成功)
- CDH服务器操作系统:CentOS Linux release 7.7.1908
- cm版本:6.3.1
- parcel版本:5.16.2
- flink版本:1.7.2
注意:因为flink需要hadoop2.6版本,所以parcel选择了5.16.2,这里面对应的hadoop是2.6版
CDH服务器设置
需要登录CDH服务器执行以下设置:
- 检查/etc/hostname文件是否正确,如下图:

- 修改/etc/hosts文件,将自己的IP地址和hostname配置上去,如下图红框所示(事实证明这一步很重要,如果不做可能导致在部署时一直卡在"分配"阶段,看agent日志显示agent下载parcel的进度一直是百分之零):

下载文件(ansible电脑)
本次实战要准备13个文件,如下表所示(后面会给出每个文件的获取方式):
| 编号 | 文件名 | 简介 |
|---|---|---|
| 1 | jdk-8u191-linux-x64.tar.gz | Linux版的jdk安装包 |
| 2 | mysql-connector-java-5.1.34.jar | mysql的JDBC驱动 |
| 3 | cloudera-manager-server-6.3.1-1466458.el7.x86_64.rpm | cm的server安装包 |
| 4 | cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm | cm的daemon安装包 |
| 5 | cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm | cm的agent安装包 |
| 6 | CDH-5.16.2-1.cdh5.16.2.p0.8-el7.parcel | CDH应用离线安装包 |
| 7 | CDH-5.16.2-1.cdh5.16.2.p0.8-el7.parcel.sha | CDH应用离线安装包sha验证码 |
| 8 | flink-1.7.2-bin-hadoop26-scala_2.11.tgz | flink安装包 |
| 9 | hosts | ansible用到的远程主机配置,里面记录了CDH6服务器的信息 |
| 10 | ansible.cfg | ansible用到的配置信息 |
| 11 | cm6-cdh5-flink1.7-single-install.yml | 部署CDH时用到的ansible脚本 |
| 12 | cdh-single-start.yml | 初次启动CDH时用到的ansible脚本 |
| 13 | var.yml | 脚本中用到的变量都在在此设值, 例如CDH包名、flink文件名等,便于维护 |
下面是每个文件的下载地址:
- jdk-8u191-linux-x64.tar.gz:Oracle官网可下,另外我将jdk-8u191-linux-x64.tar.gz和mysql-connector-java-5.1.34.jar一起打包上传到csdn,您可以一次性下载,地址:https://download.csdn.net/download/boling_cavalry/12098987
- mysql-connector-java-5.1.34.jar:maven中央仓库可下,另外我将jdk-8u191-linux-x64.tar.gz和mysql-connector-java-5.1.34.jar一起打包上传到csdn,您可以一次性下载,地址:https://download.csdn.net/download/boling_cavalry/12098987
- cloudera-manager-server-6.3.1-1466458.el7.x86_64.rpm:https://archive.cloudera.com/cm6/6.3.1/redhat7/yum/RPMS/x86_64/cloudera-manager-server-6.3.1-1466458.el7.x86_64.rpm
- cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm:https://archive.cloudera.com/cm6/6.3.1/redhat7/yum/RPMS/x86_64/cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm
- cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm:https://archive.cloudera.com/cm6/6.3.1/redhat7/yum/RPMS/x86_64/cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm
- CDH-5.16.2-1.cdh5.16.2.p0.8-el7.parcel:https://archive.cloudera.com/cdh5/parcels/5.16.2/CDH-5.16.2-1.cdh5.16.2.p0.8-el7.parcel
- CDH-5.16.2-1.cdh5.16.2.p0.8-el7.parcel.sha:https://archive.cloudera.com/cdh5/parcels/5.16.2/CDH-5.16.2-1.cdh5.16.2.p0.8-el7.parcel.sha1 (下载完毕后,将扩展名从.sha1为.sha)
- flink-1.7.2-bin-hadoop26-scala_2.11.tgz:http://ftp.jaist.ac.jp/pub/apache/flink/flink-1.7.2/flink-1.7.2-bin-hadoop26-scala_2.11.tgz
- hosts、ansible.cfg、cm6-cdh5-flink1.7-single-install.yml、cdh-single-start.yml、var.yml :这五个文件都保存在我的GitHub仓库,地址是:https://github.com/zq2599/blog_demos ,这里面有多个文件夹,上述文件在名为ansible-cm6-cdh5-flink172-single的文件夹中,如下图红框所示:
文件摆放(ansible电脑)
如果您已经下载好了上述13个文件,请按照如下位置摆放,这样才能顺利完成部署:
在家目录下新建名为playbooks的文件夹:mkdir ~/playbooks
把这五个文件放入playbooks文件夹:hosts、ansible.cfg、cm6-cdh5-flink1.7-single-install.yml、cdh-single-start.yml、vars.yml
在playbooks文件夹里新建名为cdh6的子文件夹;
把这八个文件放入cdh6文件夹(即剩余的八个):jdk-8u191-linux-x64.tar.gz、mysql-connector-java-5.1.34.jar、cloudera-manager-server-6.3.1-1466458.el7.x86_64.rpm、cloudera-manager-daemons-6.3.1-1466458.el7.x86_64.rpm、cloudera-manager-agent-6.3.1-1466458.el7.x86_64.rpm、CDH-5.16.2-1.cdh5.16.2.p0.8-el7.parcel、CDH-5.16.2-1.cdh5.16.2.p0.8-el7.parcel.sha、flink-1.7.2-bin-hadoop26-scala_2.11.tgz
摆放完毕后目录和文件情况如下图,再次提醒:文件夹playbooks一定要放在家目录下(即:~/):
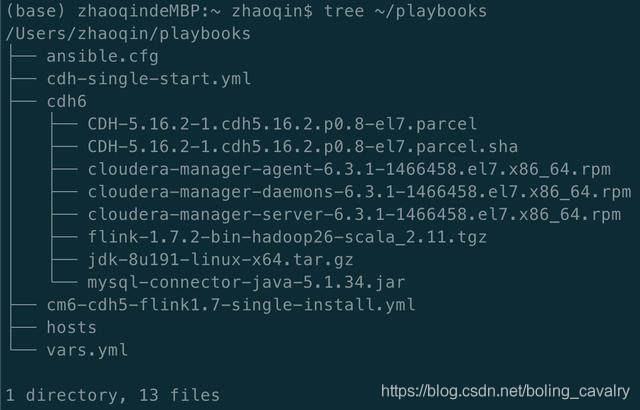
ansible参数设置(ansible电脑)
ansible参数设置的操作设置很简单:配置好CDH服务器的访问参数即可,包括IP地址、登录账号、密码等,修改~/playbooks/hosts文件,内容如下所示,您需要根据自身情况修改deskmini、ansible_host、ansible_port、ansible_user、ansible_password:
[cdh_group]deskmini ansible_host=192.168.50.134 ansible_port=22 ansible_user=root ansible_password=888888
至此,所有准备工作已完成,下一篇文章我们将完成这些操作:
- 部署CDH和Flink
- 启动CDH
- 设置CDH、在线安装Yarn、HDFS等
- 调整Yarn参数,使Flink任务可以提交成功
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
Flink on Yarn三部曲之一:准备工作的更多相关文章
- Flink on Yarn三部曲之二:部署和设置
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink on Yarn三部曲之三:提交Flink任务
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink on yarn的配置及执行
1. 写在前面 Flink被誉为第四代大数据计算引擎组件,即可以用作基于离线分布式计算,也可以应用于实时计算.Flink可以自己搭建集群模式已提供为庞大数据的计算.但在实际应用中.都是计算hdfs上的 ...
- flink on yarn 用户代码获取keytab本地文件和principal的方法
flink on yarn的情况下配置的keytab文件会根据每次yarn application 分配taskmanager的变化都是不一样的,在部分场景下用户代码也需要获得keytab文件在yar ...
- flink on yarn部分源码解析
转发请注明原创地址:https://www.cnblogs.com/dongxiao-yang/p/9403427.html flink任务的deploy形式有很多种选择,常见的有standalone ...
- flink hadoop yarn
新一代大数据处理引擎 Apache Flink https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-flink/ 新一代大数据处 ...
- Flink on Yarn模式启动流程分析
此文已由作者岳猛授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. Flink On Yarn 架构 Paste_Image.png 前提条件首先需要配置YARN_CONF_DI ...
- Flink on Yarn模式启动流程源代码分析
此文已由作者岳猛授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. Flink on yarn的启动流程可以参见前面的文章 Flink on Yarn启动流程,下面主要是从源码角 ...
- Flink on YARN时,如何确定TaskManager数
转自: https://www.jianshu.com/p/5b670d524fa5 答案写在最前面:Job的最大并行度除以每个TaskManager分配的任务槽数. 问题 在Flink 1.5 Re ...
随机推荐
- ctfhub sql注入字符型
手工注入 1, 检查是否存在注入 2.猜字段数.列数 3.获得注入点,数据库名称,数据库版本 4.获得表名 5.获得字段名 6.获得flag sqlmap方法 1.查数据库库名 2.查表名 3.查字段 ...
- 轻松上手SpringBoot Security + JWT Hello World示例
前言 在本教程中,我们将开发一个Spring Boot应用程序,该应用程序使用JWT身份验证来保护公开的REST API.在此示例中,我们将使用硬编码的用户和密码进行用户身份验证. 在下一个教程中,我 ...
- C#开发PACS医学影像处理系统(十九):Dicom影像放大镜
在XAML代码设计器中,添加canvas画布与圆形几何对象,利用VisualBrush笔刷来复制画面内容到指定容器: <Canvas x:Name="CvsGlass" Wi ...
- 容器云平台No.3~kubernetes使用
今天是是第三篇,接着上一篇继续 首先,通过kubectl可以看到,三个节点都正常运行 [root@k8s-master001 ~]# kubectl get no NAME STATUS ROLES ...
- 20行代码实现,使用Tarjan算法求解强连通分量
今天是算法数据结构专题的第36篇文章,我们一起来继续聊聊强连通分量分解的算法. 在上一篇文章当中我们分享了强连通分量分解的一个经典算法Kosaraju算法,它的核心原理是通过将图翻转,以及两次递归来实 ...
- Spring Cloud各组件学习
Spring-Cloud 介绍 SpringCloud各个组件详解,因为SpringCloud部分组件停止更新,故本项目包含原SpringCloud(基于SpringCloud H版和SpringBo ...
- Python练习题 032:Project Euler 004:最大的回文积
本题来自 Project Euler 第4题:https://projecteuler.net/problem=4 # Project Euler: Problem 4: Largest palind ...
- GOOGLE工作法(世界一速)|木深读书笔记
- 01 AS 首次编译执行项目过程中遇到的几个常见问题
问题01 as打开时出现The environment variable JAVA_HOME (with The value of C:\Java\jdk1.8.0_101\bin) does not ...
- 05 sublime环境配置及编译运行后输出中文乱码的解决
编译后的乱码问题 编译后的输出:中文显示异常: 编译C出现乱码问题解决 解决思路:解决办法很简单,就是先设置文件编码为GBK格式,之后再输入中文文字,运行时的中文就不是乱码了. 首先,sublime中 ...