Golang 网络爬虫框架gocolly/colly 四
Golang 网络爬虫框架gocolly/colly 四
爬虫靠演技,表演得越像浏览器,抓取数据越容易,这是我多年爬虫经验的感悟。回顾下个人的爬虫经历,共分三个阶段:第一阶段,09年左右开始接触爬虫,那时由于项目需要,要访问各大国际社交网站,Facebook,myspace,filcker,youtube等等,国际上叫得上名字的社交网站都爬过,大部分网站提供restful api,有些功能没有api,就只能用http抓包工具分析协议,自己爬;国内的优酷、土豆、校内网、web版qq、网页邮箱等等也都爬过;那时候先用C#写demo,项目是C++的,所以还要转换成托管C++的代码。第一阶段的主要心得是cookie管理,比较难搞的cookie就借助于webbrowser控件。
第二阶段是13年左右,做的是金融数据分析类软件和网络机器人,爬虫编程语言依然借助于C# ,发包收包全靠HttpWebRequest和HttpWebResponse,cookie管理靠CookieContainer,HTML分析靠HtmlAgilityPack,验证码识别靠自己预处理封装过的tesseract,协议分析靠fiddler,元素选择靠浏览器调试器,这套功夫在手基本可以畅游网络,实现的机器人随意游走于博客、微博,自动留言、发帖、评论;各大金融网站、上交所、深交所、巨潮网络、互动平台等等数据任爬。
第三阶段就是现在了。四年多过去了,重新学习审视爬虫技术,发现武器更强大了:go语言,goquery,colly,chromedp,webloop等,强大的语言及工具使爬虫更简单、更高效。
多年的爬虫经验总结了开头那句话。已知的爬虫手段无外乎三大类:一,分析HTTP协议,构造请求;二,利用浏览器控件,获取cookie、页面元素、调用js脚本等;phantomjs、webloop属于此类;第三类是直接操作浏览器,chromedp属于此类;微软还提供了操纵ie浏览器的com接口,很早以前用C++写过,比较难用,代码写起来很恶心,需要较多的条件判断。构造请求直接快速,浏览器控件和操纵浏览器可靠安全,可以省去很多不必要的协议分析、js脚本分析,但速度慢,加载了很多无用的数据、图片等;第二、三种与第一种混用效果更佳,只要表演地越像浏览器就越安全可靠,或者干脆操纵浏览器,只要不超过服务器的人类操作阈值判定,ip基本不会被封。单ip不够用时,就设置代理来切换。
学无止境,不断用新的武器武装自己。下面贡献一个小例子,爬取上交所的AB股股票列表,简单地show下演技。(哈哈哈)
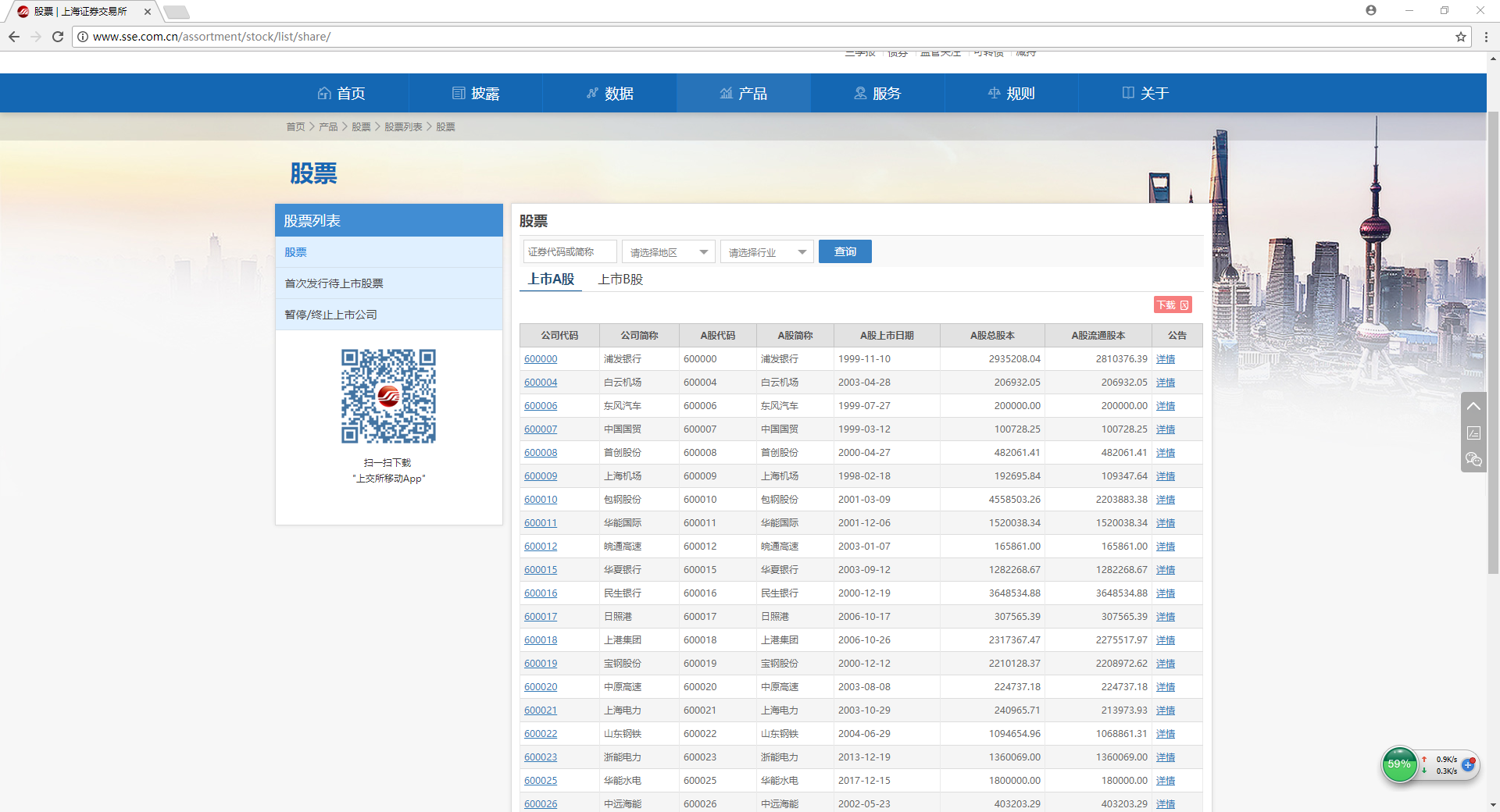
该页面提供了下载功能,A股的下载地址 http://query.sse.com.cn/security/stock/downloadStockListFile.do?csrcCode=&stockCode=&areaName=&stockType=1
B股的下载地址 http://query.sse.com.cn/security/stock/downloadStockListFile.do?csrcCode=&stockCode=&areaName=&stockType=2
拿到了这个地址就开始Visit了
c.Visit("http://query.sse.com.cn/security/stock/downloadStockListFile.do?csrcCode=&stockCode=&areaName=&stockType=1")
UserAgent设置成了Chrome
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36"
发现不行,程序会报错,
// :: Forbidden
把这个网址直接在浏览器地址栏中打开也是不行的,会报告“Error 403: SRVE0190E: 找不到文件:/error/error_cn.jsp”
服务端做了些限制,打开fiddler看下协议
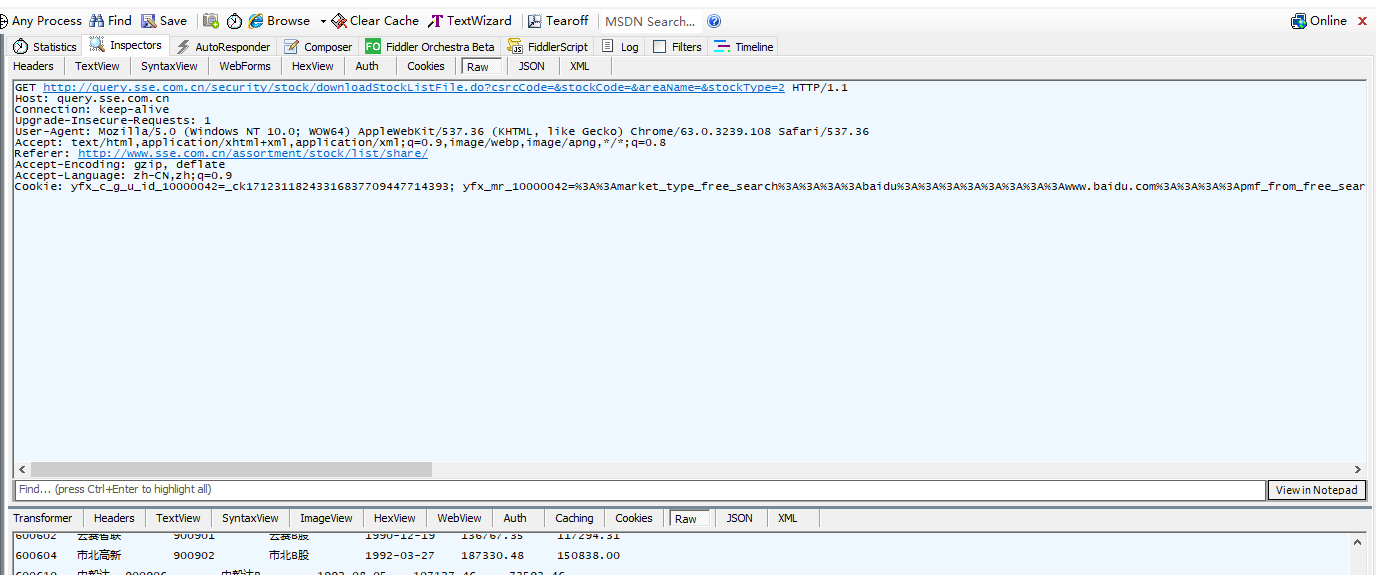
请求中有一大堆cookie,第一感觉是可能没有加cookie的缘故,于是利用chromedp打开页面,再调用ajax去请求,刚开始ajax没有带cookie也请求成功了,
后来发现关键在于请求头中的“Referer”,有了Referer就行了。
干脆把所有的头补全,更像浏览器些,这不会吃亏:
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("Host", "query.sse.com.cn")
r.Headers.Set("Connection", "keep-alive")
r.Headers.Set("Accept", "*/*")
r.Headers.Set("Origin", "http://www.sse.com.cn")
r.Headers.Set("Referer", "http://www.sse.com.cn/assortment/stock/list/share/") //关键头 如果没有 则返回 错误
r.Headers.Set("Accept-Encoding", "gzip, deflate")
r.Headers.Set("Accept-Language", "zh-CN,zh;q=0.9")
})
附上完整的代码,将股票保存到CSV文件
package sse import (
"encoding/csv"
"os"
"strings" "github.com/gocolly/colly"
) /*GetStockListA 获取上海证券交易所股票列表
A股
*/
func GetStockListA(saveFile string) (err error) { stocks, err := getStockList("http://query.sse.com.cn/security/stock/downloadStockListFile.do?csrcCode=&stockCode=&areaName=&stockType=1")
if err != nil {
return err
} err = saveStockList2CSV(stocks, saveFile)
return
} /*GetStockListB 获取上海证券交易所股票列表
B股
*/
func GetStockListB(saveFile string) (err error) {
stocks, err := getStockList("http://query.sse.com.cn/security/stock/downloadStockListFile.do?csrcCode=&stockCode=&areaName=&stockType=2")
if err != nil {
return err
}
err = saveStockList2CSV(stocks, saveFile)
return
}
func saveStockList2CSV(stockList string, file string) (err error) { vals := strings.Split(stockList, "\n") f, err := os.Create(file)
if err != nil {
return err
}
defer f.Close()
fw := csv.NewWriter(f) for _, row := range vals { rSplits := strings.Split(row, "\t") rSplitsRslt := make([]string, 0)
for _, sp := range rSplits {
trimSp := strings.Trim(sp, " ")
if len(trimSp) > 0 {
rSplitsRslt = append(rSplitsRslt, trimSp)
}
}
if len(rSplitsRslt) > 0 {
err = fw.Write(rSplitsRslt)
if err != nil {
return err
}
}
}
fw.Flush() return
} func getStockList(url string) (stockList string, err error) { //GET http://query.sse.com.cn/security/stock/downloadStockListFile.do?csrcCode=&stockCode=&areaName=&stockType=1 HTTP/1.1
//Host: query.sse.com.cn
//Connection: keep-alive
//Accept: */*
//Origin: http://www.sse.com.cn
//User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36
//Referer: http://www.sse.com.cn/assortment/stock/list/share/
//Accept-Encoding: gzip, deflate
//Accept-Language: zh-CN,zh;q=0.9` c := colly.NewCollector() c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36"
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("Host", "query.sse.com.cn")
r.Headers.Set("Connection", "keep-alive")
r.Headers.Set("Accept", "*/*")
r.Headers.Set("Origin", "http://www.sse.com.cn")
r.Headers.Set("Referer", "http://www.sse.com.cn/assortment/stock/list/share/") //关键头 如果没有 则返回 错误
r.Headers.Set("Accept-Encoding", "gzip, deflate")
r.Headers.Set("Accept-Language", "zh-CN,zh;q=0.9")
})
c.OnResponse(func(resp *colly.Response) {
stockList = string(resp.Body)
}) c.OnError(func(resp *colly.Response, errHttp error) {
err = errHttp
}) err = c.Visit(url) return
}
func main() {
var err error
err = sse.GetStockListA("e:\\sseA.csv")
if err != nil {
log.Fatal(err)
}
err = sse.GetStockListB("e:\\sseB.csv")
if err != nil {
log.Fatal(err)
}
}
转载请注明出处: http://www.cnblogs.com/majianguo/p/8186429.html
Golang 网络爬虫框架gocolly/colly 四的更多相关文章
- Golang 网络爬虫框架gocolly/colly 五 获取动态数据
Golang 网络爬虫框架gocolly/colly 五 获取动态数据 gcocolly+goquery可以非常好地抓取HTML页面中的数据,但碰到页面是由Javascript动态生成时,用goque ...
- Golang 网络爬虫框架gocolly/colly 三
Golang 网络爬虫框架gocolly/colly 三 熟悉了<Golang 网络爬虫框架gocolly/colly一>和<Golang 网络爬虫框架gocolly/colly二& ...
- Golang 网络爬虫框架gocolly/colly 二 jQuery selector
Golang 网络爬虫框架gocolly/colly 二 jQuery selector colly框架依赖goquery库,goquery将jQuery的语法和特性引入到了go语言中.如果要灵活自如 ...
- Golang 网络爬虫框架gocolly/colly 一
Golang 网络爬虫框架gocolly/colly 一 gocolly是用go实现的网络爬虫框架,目前在github上具有3400+星,名列go版爬虫程序榜首.gocolly快速优雅,在单核上每秒可 ...
- 试验一下Golang 网络爬虫框架gocolly/colly
参考:http://www.cnblogs.com/majianguo/p/8186429.html 框架源码在 github.com/gocolly/colly 代码如下(github源码中的dem ...
- 网络爬虫框架Scrapy简介
作者: 黄进(QQ:7149101) 一. 网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本:它是一个自动提取网页的程序,它为搜索引擎从万维 ...
- 基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库)
原文地址http://blog.csdn.net/qy20115549/article/details/52203722 本文为原创博客,仅供技术学习使用.未经允许,禁止将其复制下来上传到百度文库等平 ...
- [原创]一款基于Reactor线程模型的java网络爬虫框架
AJSprider 概述 AJSprider是笔者基于Reactor线程模式+Jsoup+HttpClient封装的一款轻量级java多线程网络爬虫框架,简单上手,小白也能玩爬虫, 使用本框架,只需要 ...
- Scrapy (网络爬虫框架)入门
一.Scrapy 简介: Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado) ...
随机推荐
- 将百度的ECharts整合到阿里的Weex中。
由于公司的业务,之前PC版产品中,大量的使用了百度的ECharts库.所以现在要做移动端,在大概熟悉了Weex基本语法和搭建环境后,就着手研究如何将这两个好东西糅合起来. 首先,按照Weex官方教程, ...
- This package contains sshd, pcal, mysql-client on Ubuntu14:04
[How to build:]cd /home/ops/work/demo/docker/aws/ubuntutouch Dockerfiledocker build -t ubuntu_base:v ...
- Python中的选择排序
选择排序 选择排序(Selection sort)是一种简单直观的排序算法.它的工作原理如下.首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大 ...
- 蓝桥杯 剪邮票 全排列+DFS
剪邮票 如[图1.jpg], 有12张连在一起的12生肖的邮票. 现在你要从中剪下5张来,要求必须是连着的. (仅仅连接一个角不算相连) 比如,[图2.jpg],[图3.jpg]中,粉红色所示部分就是 ...
- 一个js的动画,以前以为只有flash可以实现
11年刚干这行的时候,看到这种什么百叶窗的动画,以为都是flash实现的,最近突然灵光一闪,想到了用js实现(虽然我不是做前端的,本人做.net).代码虽然实现了,但是比较乱,先上个图: 代码主要就是 ...
- 浅谈 Integer 类
在讲解 Integer 之前,我们先看下面这段代码: public static void main(String[] args) { Integer i = 10; Integer j = 10; ...
- 走进Linux01-磁盘分区与文件夹结构
近期学习Linux,首先安装系统,遇到了磁盘分区.之前仅仅知道Linux分区是从/(根文件夹)開始的,至于磁盘格式,多块盘怎样挂载全然不了解,系统的查询了一下Linux磁盘分区和文件夹结构,整理一下. ...
- IDE转AHCI
1.Win + R.输入regedit.进入注冊表编辑器 2.找到HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Msahci.将当中的&qu ...
- 《Linux Device Drivers》第十八章 TTY驱动程序——note
简单介绍 tty设备的名称是从过去的电传打字机缩写而来,最初是指连接到Unix系统上的物理或虚拟终端 Linux tty驱动程序的核心紧挨在标准字符设备驱动层之下,并提供了一系列的功能,作为接口被终端 ...
- ccbpm工作流引擎是怎样支持多种流程模式的
前言: 在BPM领域支持流程运转的理论模型有多种.有的21种.28种.32种. 每种模式都代表了这样的模式的理论设计者研究者的人员主张.思想.这些模式尽可能的,全然去覆盖到现实生产.工作.应用上的流程 ...