Spark2.1.0之初识Spark
随着近十年互联网的迅猛发展,越来越多的人融入了互联网——利用搜索引擎查询词条或问题;社交圈子从现实搬到了Facebook、Twitter、微信等社交平台上;女孩子们现在少了逛街,多了在各大电商平台上的购买;喜欢棋牌的人能够在对战平台上找到世界各地的玩家对弈。在国内随着网民数量的持续增加,造成互联网公司的数据在体量、产生速度、多样性等方面呈现出巨大的变化。
互联网产生的数据相较于传统软件产生的数据,有着数据挖掘的巨大潜力。通过对数据的挖掘,可以统计出PV、UV,计算出不同设备与注册率、促销与下单率之间的关系,甚至构建热点分析、人群画像等算法模型,产生一系列报表、图形、离线统计、实时计算的产品。互联网公司如果能有效利用这些数据,将对决策和战略发展起到至关重要的作用。
在大数据的大势之下,Hadoop、Spark、Flink、Storm、Dremel、Impala、Tez等一系列大数据技术如雨后春笋般不断涌现。工程师们正在使用这些工具在摸索中前行。
Spark是一个通用的并行计算框架,由加州伯克利大学(UCBerkeley)的AMP实验室开发于2009年,并于2010年开源。2013年成长为Apache旗下在大数据领域最活跃的开源项目之一。
Spark目前已经走过了0.x和1.x两个时代,现在正在2.x时代稳步发展。Spark从2012年10月15日发布0.6到2016年1月4日发布1.6只经过了三年时间,那时候差不多每个月都会有新的版本发布,平均每个季度会发布一个新的二级版本。
自从2016年7月发布了2.0.0版本以来,只在当年12月又发布了2.1.0版本,直到目前为止还没有新的二级版本发布。Spark发布新版本的节奏明显慢了下来,当然这也跟Spark团队过于激进的决策(比如很多API不能向前兼容,让用户无力吐槽)有关。
Spark也是基于map reduce 算法模型实现的分布式计算框架,拥有Hadoop www.feihuanyule.com MapReduce所具有的优点,并且解决了Hadoop MapReduce中的诸多缺陷。
Hadoop MRv1的局限
早在Hadoop1.0版本,当时采用的是MRv1版本的MapReduce编程模型。MRv1版本的实现都封装在org.apache.hadoop.mapred包中,MRv1的Map和Reduce是通过接口实现的。MRv1包括三个部分:
- 运行时环境(JobTracker和TaskTracker);
- 编程模型(MapReduce);
- 数据处理引擎(Map任务和Reduce任务)。
MRv1存在以下不足。
- 可扩展性差:在运行时,JobTrac www.chushiyl.cn ker既负责资源管理又负责任务调度,当集群繁忙时,JobTracker很容易成为瓶颈,最终导致它的可扩展性问题。
- 可用性差:采用了单节点的Master,没有备用Master及选举操作,这导致一旦Master出现故障,整个集群将不可用。
- 资源利用率低:TaskTracker 使用slot等量划分本节点上的资源量。slot代表计算资源(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,Hadoop 调度器负责将各个TaskTracker 上的空闲slot 分配给Task 使用。一些Task并不能充分利用slot,而其他Task也无法使用这些空闲的资源。slot 分为Map slot和Reduce slot 两种,分别供MapTask 和Reduce Task 使用。有时会因为作业刚刚启动等原因导致MapTask很多,而Reduce Task任务还没有调度的情况,这时Reduce slot也会被闲置。
- 不能支持多种MapReduce框架:无法通过可插拔方式将自身的MapReduce框架替换为其他实现,如Spark、Storm等。
MRv1的示意如图1。

图1 MRv1示意图
Apache为了解决以上问题,对Hadoop升级改造,MRv2最终诞生了。MRv2中,重用了MRv1中的编程模型和数据处理引擎。但是运行时环境被重构了。JobTracker被拆分成了通用的资源调度平台(ResourceManager,简称RM)、节点管理器(NodeManager)和负责各个计算框架的任务调度模型(ApplicationMaster,简称AM)。ResourceManager依然负责对整个集群的资源管理,但是在任务资源的调度方面只负责将资源封装为Container分配给ApplicationMaster 的一级调度,二级调度的细节将交给ApplicationMaster去完成,这大大减轻了ResourceManager 的压力,使得ResourceManager 更加轻量。NodeManager负责对单个节点的资源管理,并将资源信息、Container运行状态、健康状况等信息上报给ResourceManager。ResourceManager 为了保证Container的利用率,会监控Container,如果Container未在有限的时间内使用,ResourceManager将命令NodeManager杀死Container,以便于将资源分配给其他任务。MRv2中MapReduce的核心不再是MapReduce框架,而是Yarn。在以Yarn为核心的MRv2中,MapReduce框架是可插拔的,完全可以替换为其他MapReduce实现,比如Spark、Storm等。MRv2的示意如图2所示。
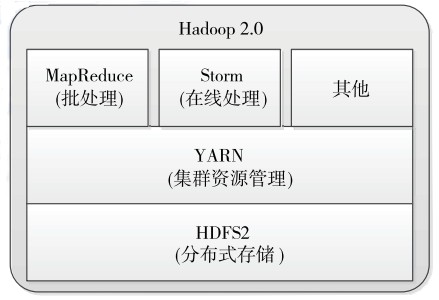
图2 MRv2示意图
Hadoop MRv2虽然解决了MRv1中的一些问题,但是由于对HDFS的频繁操作(包括计算结果持久化、数据备份、资源下载及Shuffle等)导致磁盘I/O成为系统性能的瓶颈,因此只适用于离线数据处理或批处理,而不能支持对迭代式、流式数据的处理。
Spark的特点
Spark看到MRv1的问题,对MapReduce做了大量优化,总结如下:
- 减少磁盘I/O:随着实时大数据应用越来越多,Hadoop作为离线的高吞吐、低响应框架已不能满足这类需求。HadoopMapReduce的map端将中间输出和结果存储在磁盘中,reduce端又需要从磁盘读写中间结果,势必造成磁盘IO成为瓶颈。Spark允许将map端的中间输出和结果存储在内存中,reduce端在拉取中间结果时避免了大量的磁盘I/O。Hadoop Yarn中的ApplicationMaster申请到Container后,具体的任务需要到利用NodeManager从HDFS的不同节点下载任务所需的资源(如Jar包),这也增加了磁盘I/O。Spark将应用程序上传的资源文件缓冲到Driver本地文件服务的内存中,当Executor执行任务时直接从Driver的内存中读取,也节省了大量的磁盘I/O。
- 增加并行度:由于将中间结果写到磁盘与从磁盘读取中间结果属于不同的环节,Hadoop将它们简单的通过串行执行衔接起来。Spark把不同的环节抽象为Stage,允许多个Stage既可以串行执行,又可以并行执行。
- 避免重新计算:当Stage中某个分区的Task执行失败后,会重新对此Stage调度,但在重新调度的时候会过滤已经执行成功的分区任务,所以不会造成重复计算和资源浪费。
- 可选的Shuffle排序:HadoopMapReduce在Shuffle之前有着固定的排序操作,而Spark则可以根据不同场景选择在map端排序或者reduce端排序。
- 灵活的内存管理策略:Spark将内存分为堆上的存储内存、堆外的存储内存、堆上的执行内存、堆外的执行内存4个部分。Spark既提供了执行内存和存储内存之间是固定边界的实现,又提供了执行内存和存储内存之间是“软”边界的实现。Spark默认使用“软”边界的实现,执行内存或存储内存中的任意一方在资源不足时都可以借用另一方的内存,最大限度的提高资源的利用率,减少对资源的浪费。Spark由于对内存使用的偏好,内存资源的多寡和使用率就显得尤为重要,为此Spark的内存管理器提供的Tungsten实现了一种与操作系统的内存Page非常相似的数据结构,用于直接操作操作系统内存,节省了创建的Java对象在堆中占用的内存,使得Spark对内存的使用效率更加接近硬件。Spark会给每个Task分配一个配套的任务内存管理器,对Task粒度的内存进行管理。Task的内存可以被多个内部的消费者消费,任务内存管理器对每个消费者进行Task内存的分配与管理,因此Spark对内存有着更细粒度的管理。
基于以上所列举的优化,Spark官网声称性能比Hadoop快100倍,如图3所示。即便是内存不足需要磁盘I/O时,其速度也是Hadoop的10倍以上。
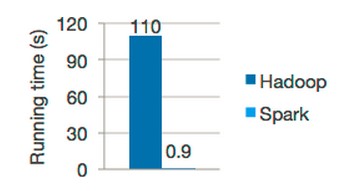
图3 Hadoop与Spark执行逻辑回归时间比较
Spark还有其他一些特点。
- 检查点支持:Spark的RDD之间维护了血缘关系(lineage),一旦某个RDD失败了,则可以由父RDD重建。虽然lineage可用于错误后RDD的恢复,但对于很长的lineage来说,恢复过程非常耗时。如果应用启用了检查点,那么在Stage中的Task都执行成功后,SparkContext将把RDD计算的结果保存到检查点,这样当某个RDD执行失败后,在由父RDD重建时就不需要重新计算,而直接从检查点恢复数据。
- 易于使用。Spark现在支持Java、Scala、Python和R等语言编写应用程序,大大降低了使用者的门槛。自带了80多个高等级操作符,允许在Scala,Python,R的shell中进行交互式查询。
- 支持交互式:Spark使用Scala开发,并借助于Scala类库中的Iloop实现交互式shell,提供对REPL(Read-eval-print-loop)的实现。
- 支持SQL查询。在数据查询方面,Spark支持SQL及Hive SQL,这极大的方便了传统SQL开发和数据仓库的使用者。
- 支持流式计算:与MapReduce只能处理离线数据相比,Spark还支持实时的流计算。Spark依赖SparkStreaming对数据进行实时的处理,其流式处理能力还要强于Storm。
- 可用性高。Spark自身实现了Standalone部署模式,此模式下的Master可以有多个,解决了单点故障问题。Spark也完全支持使用外部的部署模式,比如YARN、Mesos、EC2等。
- 丰富的数据源支持:Spark除了可以访问操作系统自身的文件系统和HDFS,还可以访问Kafka、Socket、Cassandra、HBase、Hive、Alluxio(Tachyon)以及任何Hadoop的数据源。这极大地方便了已经使用HDFS、HBase的用户顺利迁移到Spark。
- 丰富的文件格式支持:Spark支持文本文件格式、Csv文件格式、Json文件格式、Orc文件格式、Parquet文件格式、Libsvm文件格式,也有利于Spark与其他数据处理平台的对接。
Spark使用场景
Hadoop常用于解决高吞吐、批量处理的业务场景,例如对浏览量的离线统计。如果需要实时查看浏览量统计信息,Hadoop显然不符合这样的要求。Spark通过内存计算能力极大地提高了大数据处理速度,满足了以上场景的需要。此外,Spark还支持交互式查询,SQL查询,流式计算,图计算,机器学习等。通过对Java、Python、Scala、R等语言的支持,极大地方便了用户的使用。
笔者就目前所知道的Spark应用场景,进行介绍。
1.医疗健康
看病是一个非常典型的分析过程——医生根据患者的一些征兆、检验结果,结合医生本人的经验得出结论,最后给出相应的治疗方案。现在国内的医疗状况是各地区医疗水平参差不齐,医疗资源也非常紧张,特别是高水平医生更为紧缺,好医院的地区分布很不均衡。大城市有更完善的医疗体系,而农村可能就只有几个赤脚医生。一些农民看病可能要从村里坐车到镇,再到县城,再到地级市甚至省会城市,看病的路程堪比征程。
大数据根据患者的患病征兆、检验报告,通过病理分析模型找出病因并给出具体的治疗方案。即便是医疗水平落后的地区,只需要输入患者的患病征兆和病例数据既可体验高水平医师的服务。通过Spark从海量数据中实时计算出病因,各个地区的医疗水平和效率将获得大幅度提升,同时也能很好的降低因为医生水平而导致误诊的概率。
实施医疗健康的必然措施是监测和预测。通过监测不断更新整个医疗基础库的知识,并通过医疗健康模型预测出疾病易发的地区和人群。
2.电商
通过对用户的消费习惯、季节、产品使用周期等数据的收集,建立算法模型来判断消费者未来一个月、几个月甚至一年的消费需求(不是简单的根据你已经消费的产品,显示推荐广告位),进而提高订单转化率。
在市场营销方面,通过给买家打标签,构建人群画像,进而针对不同的人群,精准投放广告、红包或优惠券。
3.安全领域
面对日益复杂的网络安全,通过检测和数据分析区分出不同的安全类型。并针对不同的安全类型,实施不同的防御、打击措施。
- 端安全:使用安全卫士、云查杀对经过大数据分析得到的病毒、木马等进行防御。
- 电商安全:反刷单、反欺诈、合规。
- 金融安全:风险控制。
- 企业安全:反入侵。
- 国家安全:舆情监测,打击罪犯。
4.金融领域
构建金融云,通过对巨量的计量数据收集。通过Spark实时处理分析,利用低延迟的数据处理能力,应对急迫的业务需求和数据增长。
量化投资——收集大宗商品的价格,黄金,石油等各种数据,分析黄金、股票等指数趋势,支持投资决策。
除了以上领域外,在搜索引擎、生态圈异常检测、生物计算等诸多领域都有广泛的应用场景。
引用:本文的图1和图2都来源自http://www.233077.cn .www.233077.cn .net/uid www.taohuayuan178.com/-28311809-id-4383551.html。
Spark2.1.0之初识Spark的更多相关文章
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装
hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装 一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh ...
- Spark2.1.0分布式集群安装
一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh/p/6623530.html 1.2 Hadoop 参见博文:http://www.cnblogs ...
- spark-2.2.0安装和部署——Spark集群学习日记
前言 在安装后hadoop之后,接下来需要安装的就是Spark. scala-2.11.7下载与安装 具体步骤参见上一篇博文 Spark下载 为了方便,我直接是进入到了/usr/local文件夹下面进 ...
- Spark2.1.0——Spark初体验
学习一个工具的最好途径,就是使用它.这就好比<极品飞车>玩得好的同学,未必真的会开车,要学习车的驾驶技能,就必须用手触摸方向盘.用脚感受刹车与油门的力道.在IT领域,在深入了解一个系统的原 ...
- spark最新源码下载并导入到开发环境下助推高质量代码(Scala IDEA for Eclipse和IntelliJ IDEA皆适用)(以spark2.2.0源码包为例)(图文详解)
不多说,直接上干货! 前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. ...
- spark2.3.0 配置spark sql 操作hive
spark可以通过读取hive的元数据来兼容hive,读取hive的表数据,然后在spark引擎中进行sql统计分析,从而,通过spark sql与hive结合实现数据分析将成为一种最佳实践.配置步骤 ...
- Spark记录-源码编译spark2.2.0(结合Hive on Spark/Hive on MR2/Spark on Yarn)
#spark2.2.0源码编译 #组件:mvn-3.3.9 jdk-1.8 #wget http://mirror.bit.edu.cn/apache/spark/spark-2.2.0/spark- ...
- 初识spark的MLP模型
初识Spark的MLP模型 1. MLP介绍 Multi-layer Perceptron(MLP),即多层感知器,是一个前馈式的.具有监督的人工神经网络结构.通过多层感知器可包含多个隐藏层,实现对非 ...
- Hadoop2.7.3+Spark2.1.0完全分布式集群搭建过程
1.选取三台服务器(CentOS系统64位) 114.55.246.88 主节点 114.55.246.77 从节点 114.55.246.93 从节点 之后的操作如果是用普通用户操作的话也必须知道r ...
随机推荐
- 韩国KT软件NB-IOT开发记录V150(2)IOT maker通信相关
1. 测试的AT指令,创建端口和IP地址链接 AT#IMINIT=," 开始连接 AT#IMCONN 创建object ID AT#IMOBJMETA=,," 发送数据 AT#IM ...
- SpringBoot入门(一)——开箱即用
本文来自网易云社区 Spring Boot是什么 从根本上来讲Spring Boot就是一些库的集合,是一个基于"约定优于配置"的原则,快速搭建应用的框架.本质上依然Spring, ...
- 使用union 外加count
explain extended and name='aaa')) t; +----+--------------+------------+-------+---------------+----- ...
- focus如何实现事件委托
事件委托是利用事件冒泡机制的一种优化手段,如果有很多列表元素要绑定事件,那么就可以用事件委托来优化(不需要给每个元素都绑定事件).但是对于focus这种特殊的表单事件,它不会冒泡,那么又该如何实现这一 ...
- textview的阴影线
android:shadowColor="#000000" android:shadowDx="1" android:shadowDy="1" ...
- python3基础盲点
数值类型 Python支持四种不同的数值类型,包括int(整数)long(长整数)float(浮点数)complex (复数) python3对整数的大小不做限制 算数运算符 优先级: 逻辑运算符 优 ...
- 【system.folder】使用说明
对象:system.folder 说明:提供一系列针对文件夹的操作 目录: 方法 返回 说明 system.folder.exists(folderPath) [True | False] 检测指定文 ...
- 【form】 表单组件说明
form表单组件 1)将form组件内的用户输入的<switch/> <input/> <checkbox/> <slider/> <radio/ ...
- chrome编辑器与截图
在地址栏中输入 data:text/html,<html contenteditable>即可使用编辑功能,打开控制台,ctrl + shift + p 调用命令面板,输入 capture ...
- Hadoop第一课:Hadoop集群环境搭建
一. 检查列表 1.1.网络访问 设置电脑IP以及可以访问网络设置:进入etc/sysconfig/network-scripts/,使用命令“ls -all” 查看文件.会看到ifcfg-lo文件然 ...