用Python爬取智联招聘信息做职业规划
上学期在实验室发表时写了一个爬取智联招牌信息的爬虫。
操作流程大致分为:信息爬取——数据结构化——存入数据库——所需技能等分词统计——数据可视化
1.数据爬取
job = "通信工程师" #以爬取通信工程师职业为例
leibie = ''
url_job = [] for page in range(99):
x = str(page) #爬取的页码
p = str(page+1)
print("正在抓取第一"+p+"页...\n") #提示
url = "http://sou.zhaopin.com/jobs/searchresult.ashx?in=210500%3B160400%3B160000%3B160500%3B160200%3B300100%3B160100%3B160600&jl=上海%2B杭州%2B北京%2B广州%2B深圳&kw="+job+"&p="+x+"&isadv=0" #url地址,此处为示例,可更据实际情况更改
r = requests.post(url) #发送请求
data = r.text
pattern=re.compile('ssidkey=y&ss=201&ff=03" href="(.*?)" target="_blank"',re.S) #正则匹配出招聘信息的URL地址
tmp_job = re.findall(pattern,data)
url_job.extend(tmp_job) #加入队列
上面代码以上海、杭州、北京、广州、深圳的“通信工程师”为例实现爬取了智联招聘上每一则招聘信息的URL地址。
(示例)在智联招聘上如下图所示的招聘地址:

2.数据结构化
获得URL之后,就通过URL,发送get请求,爬取每一则招聘的数据,然后使用Xpath或者正则表达式把所有数据结构化,代码如下:
for x in url_job:
print(x)
d = requests.post(x) #发送post请求
zhiwei = d.text
selector = etree.HTML(zhiwei) #获得招聘页面源码
name = selector.xpath('//div[@class="inner-left fl"]/h1/text()') #匹配到的职业名称
mone = selector.xpath('//div[@class="terminalpage clearfix"]/div[@class="terminalpage-left"]/ul[@class="terminal-ul clearfix"]/li[1]/strong/text()') #匹配到该职位的月薪
adress = selector.xpath('//div[@class="terminalpage clearfix"]/div[@class="terminalpage-left"]/ul[@class="terminal-ul clearfix"]/li[2]/strong/a/text()') #匹配工作的地址
exp = selector.xpath('//div[@class="terminalpage clearfix"]/div[@class="terminalpage-left"]/ul[@class="terminal-ul clearfix"]/li[5]/strong/text()') #匹配要求的工作经验
education = selector.xpath('//div[@class="terminalpage clearfix"]/div[@class="terminalpage-left"]/ul[@class="terminal-ul clearfix"]/li[6]/strong/text()') #匹配最低学历
zhiweileibie = selector.xpath('//div[@class="terminalpage clearfix"]/div[@class="terminalpage-left"]/ul[@class="terminal-ul clearfix"]/li[8]/strong/a/text()') #匹配职位类别 match = re.compile('<!-- SWSStringCutStart -->(.*?)<!-- SWSStringCutEnd -->',re.S)#此处为匹配对职位的描述,并且对其结构化处理
description = re.findall(match,zhiwei)
des = description[0]
des = filter_tags(des) #filter_tags此函数下面会讲到
des = des.strip()
des = des.replace(' ','')
des = des.rstrip('\n')
des = des.strip(' \t\n')
try: #尝试判断是否为最后一则
name = to_str(name[0])
mone = to_str(mone[0])
adress = to_str(adress[0])
exp = to_str(exp[0])
education = to_str(education[0])
zhiweileibie = to_str(zhiweileibie[0])
des = to_str(des)
except Exception as e:
continue
上面代码中使用了filter_tags函数,此函数的目的在于把HTML代码替换实体,并且去掉各种标签、注释和换行空行等,该函数代码如下:
def filter_tags(htmlstr):
#先过滤CDATA
re_cdata=re.compile('//<!\[CDATA\[[^>]*//\]\]>',re.I) #匹配CDATA
re_script=re.compile('<\s*script[^>]*>[^<]*<\s*/\s*script\s*>',re.I)#Script
re_style=re.compile('<\s*style[^>]*>[^<]*<\s*/\s*style\s*>',re.I)#style
re_br=re.compile('<br\s*?/?>')#处理换行
re_h=re.compile('</?\w+[^>]*>')#HTML标签
re_comment=re.compile('<!--[^>]*-->')#HTML注释
s=re_cdata.sub('',htmlstr)#去掉CDATA
s=re_script.sub('',s) #去掉SCRIPT
s=re_style.sub('',s)#去掉style
#s=re_br.sub('\n',s)#将br转换为换行
s=re_h.sub('',s) #去掉HTML 标签
s=re_comment.sub('',s)#去掉HTML注释
#去掉多余的空行
blank_line=re.compile('\n+')
s=blank_line.sub('\n',s)
# s=replaceCharEntity(s)#替换实体
return s
3.存入数据库
上面的代码已经帮我们实现根据数据表中设置的字段清洗好杂乱无章的数据了,之后只要在循环中把结构化的数据存入数据库即可。
具体代码如下:
conn = pymysql.connect(host='127.0.0.1',user='root',passwd='××××××',db='zhiye_data',port=3306,charset='utf8')
cursor=conn.cursor() sql='INSERT INTO `main_data_3` (`name`,`mone`,`adress`,`exp`,`education`,`zhiweileibie`,`description`,`leibie`,`company_range`,`company_kind`) VALUES(\''+name+'\',\''+mone+'\',\''+adress+'\',\''+exp+'\',\''+education+'\',\''+zhiweileibie+'\',\''+des+'\',\''+leibie+'\',\'a\',\'b\');'#%(name,mone,adress,exp,education,zhiweileibie,des,leibie) #print(sql)
try:
cursor.execute(sql)
conn.commit()
print (cursor.rowcount)
except Exception as e:
print (e)
cursor.close()
conn.close()
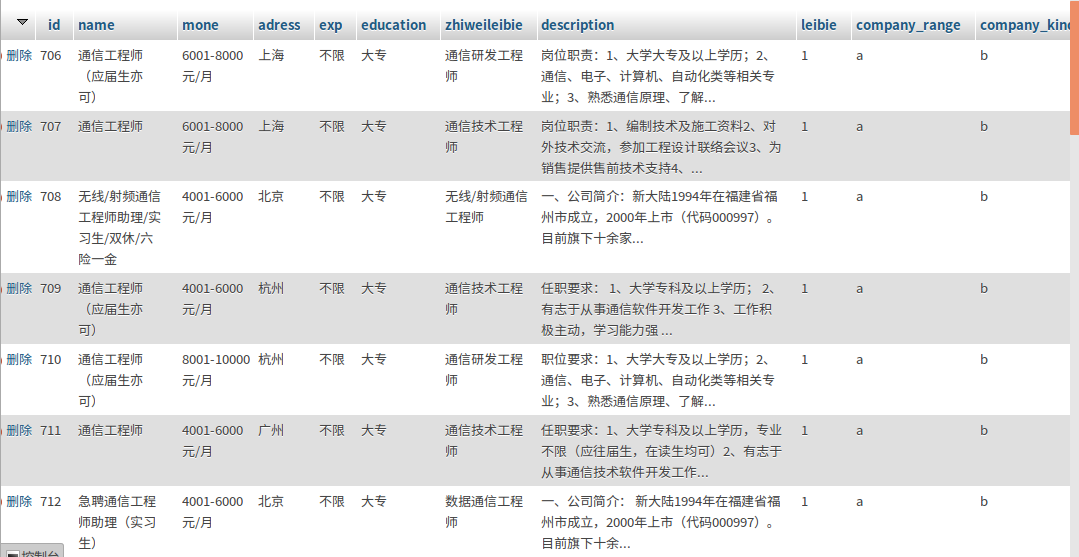
存入数据库中的具体数据示例如下图:
4.数据统计
首先对职位的描述进行分词统计,以便分析出该职业所需要的技能。
对职位描述进行分词我先使用的是SAE的分词服务,示例代码(PHP)如下(仅供参考):
public function get()
{
$h = D('hotword');
$data = $h->get_des(); foreach ($data as $k => $v) {
$content = POST("http://segment.sae.sina.com.cn/urlclient.php?encoding=UTF-8&word_tag=1","context=".$v['description']);
$text = json_decode($content,true);
if (empty($text[0]['word_tag'])) {
exit;
}
$sta = $h->hotword_save($text);
dump($sta);
}
}
向服务地址发送post请求,会以JSON格式返回具体的分析结果。存入数据库(如下图):

对每个词的出现频率进行统计,去掉一些无关的和通用的词之后就是所需职业技能的关键词。
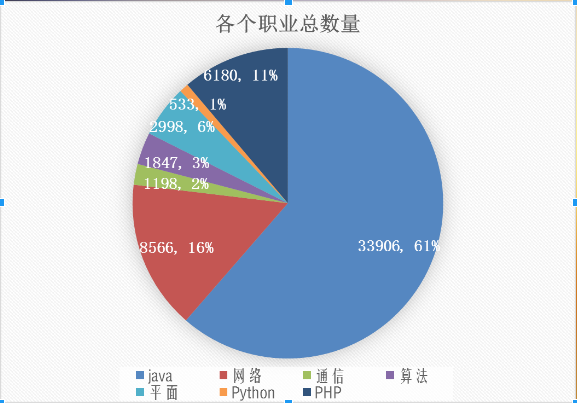
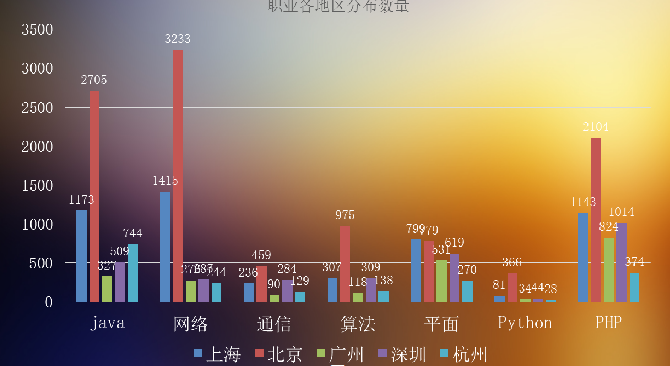
然后我也对各个地区各个职业的月薪、数量等也进行栏统计。
下面放几张结果的示例图(不清晰的截图,,,见谅哈):

下图为不同职业对学历要求的统计图

下图为Python开发出现最多的技能词

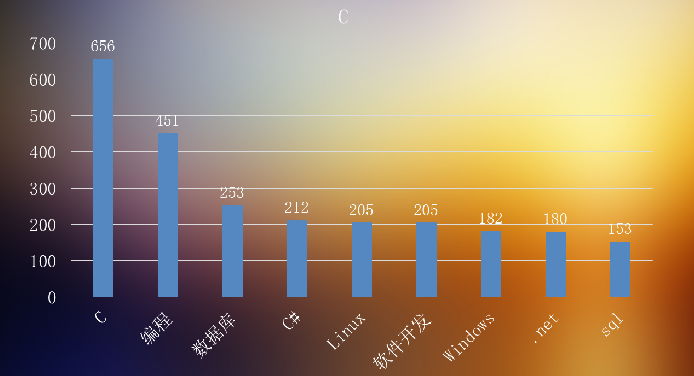
下图为C开发出现最多的技能词
最后的分析我这里就不多说了,聪明的人看图都应该能看懂了哈。
用Python爬取智联招聘信息做职业规划的更多相关文章
- 用python抓取智联招聘信息并存入excel
用python抓取智联招聘信息并存入excel tags:python 智联招聘导出excel 引言:前一阵子是人们俗称的金三银四,跳槽的小朋友很多,我觉得每个人都应该给自己做一下规划,根据自己的进步 ...
- python爬取智联招聘职位信息(多进程)
测试了下,采用单进程爬取5000条数据大概需要22分钟,速度太慢了点.我们把脚本改进下,采用多进程. 首先获取所有要爬取的URL,在这里不建议使用集合,字典或列表的数据类型来保存这些URL,因为数据量 ...
- python爬取智联招聘职位信息(单进程)
我们先通过百度搜索智联招聘,进入智联招聘官网,一看,傻眼了,需要登录才能查看招聘信息 没办法,用账号登录进去,登录后的网页如下: 输入职位名称点击搜索,显示如下网页: 把这个URL:https://s ...
- node.js 89行爬虫爬取智联招聘信息
写在前面的话, .......写个P,直接上效果图.附上源码地址 github/lonhon ok,正文开始,先列出用到的和require的东西: node.js,这个是必须的 request,然发 ...
- python爬虫实战之爬取智联职位信息和博客文章信息
1.python爬取招聘信息 简单爬取智联招聘职位信息 # !/usr/bin/env python # -*-coding:utf-8-*- """ @Author ...
- Python+selenium爬取智联招聘的职位信息
整个爬虫是基于selenium和Python来运行的,运行需要的包 mysql,matplotlib,selenium 需要安装selenium火狐浏览器驱动,百度的搜寻. 整个爬虫是模块化组织的,不 ...
- 用生产者消费模型爬取智联招聘python岗位信息
爬取python岗位智联招聘 这里爬取北京地区岗位招聘python岗位,并存入EXECEL文件内,代码如下: import json import xlwt import requests from ...
- scrapy项目2:爬取智联招聘的金融类高端岗位(spider类)
---恢复内容开始--- 今天我们来爬取一下智联招聘上金融行业薪酬在50-100万的职位. 第一步:解析解析网页 当我们依次点击下边的索引页面是,发现url的规律如下: 第1页:http://www. ...
- scrapy框架爬取智联招聘网站上深圳地区python岗位信息。
爬取字段,公司名称,职位名称,公司详情的链接,薪资待遇,要求的工作经验年限 1,items中定义爬取字段 import scrapy class ZhilianzhaopinItem(scrapy.I ...
随机推荐
- [Selenium] 操作 警告框、提示框、确认框
以如下页面为例: http://sislands.com/coin70/week1/dialogbox.htm 示例代码: pachage com.learningselenium.normalweb ...
- maven+springmvc+spring+mybatis+mysql详细搭建整合过程讲解
转自:https://www.cnblogs.com/lmei/p/7190755.html?utm_source=itdadao&utm_medium=referral @_@ 写在最前 之 ...
- Cocos2d-x 3.2 创建新应用
1.cd 到 Cocos2d-x 3.2 的目录: 2.python setup.py: 3.source /Users/netty/.bash_profile ; 4.cocos new TestP ...
- ORACLE PL/SQL 实例精解之第一章 PL/SQL概念
1.传统一层一层传数据,而PLSQL作为独立的单元返回客户端,减少查询,减少网路传输的往返,高效 2.PL/SQL语句块 分为两种:命名(子程序,函数,包保存在数据库中,后期可以根据名称进行引用),匿 ...
- [WPF自定义控件库] 自定义控件的代码如何与ControlTemplate交互
1. 前言 WPF有一个灵活的UI框架,用户可以轻松地使用代码控制控件的外观.例设我需要一个控件在鼠标进入的时候背景变成蓝色,我可以用下面这段代码实现: protected override void ...
- 洛谷 - P1115 - 最大子段和 - 简单dp
https://www.luogu.org/problemnew/show/P1115 简单到不想说……dp[i]表示以i为结尾的最大连续和的值. 那么答案肯定就是最大值了.求一次max就可以了. 仔 ...
- Gist使用经验
注:本文只是分享Gist使用经验,不讨论类似软件或服务的优劣,对于技术或软件不要有傲慢与偏见 一.Gist是什么 关于Gist的详细介绍,请阅读官方文档About gists,下面只简略介绍我所用到的 ...
- curl:出现SSL错误提示
在上一篇博文中,升级ruby版本中,提示如下错误: 1) Error fetching https://mirrors.aliyun.com/rubygems/: [root@web ~]# gem ...
- C#语言开发规范-ching版
拙劣之处请大家斧正,愚某虚心接受,如有雷同,不胜荣幸 C#语言开发规范 作者ching 1. 命名规范 a) 类 [规则1-1]使用Pascal规则命名类名,即首字母要大写. eg: Class T ...
- hbase表结构 + hbase集群架构及表存储机制
本博文的主要内容有 .hbase读取数据过程 .HBase表结构 .附带PPT http://hbase.apache.org/ 读写的时候,就需要用hbase了,换句话说,就是读写的时候.需要 ...