MapReduce的原理及执行过程
MapReduce简介
- MapReduce是一种分布式计算模型,是Google提出的,主要用于搜索领域,解决海量数据的计算问题。
- MR有两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算。
MapReduce执行流程
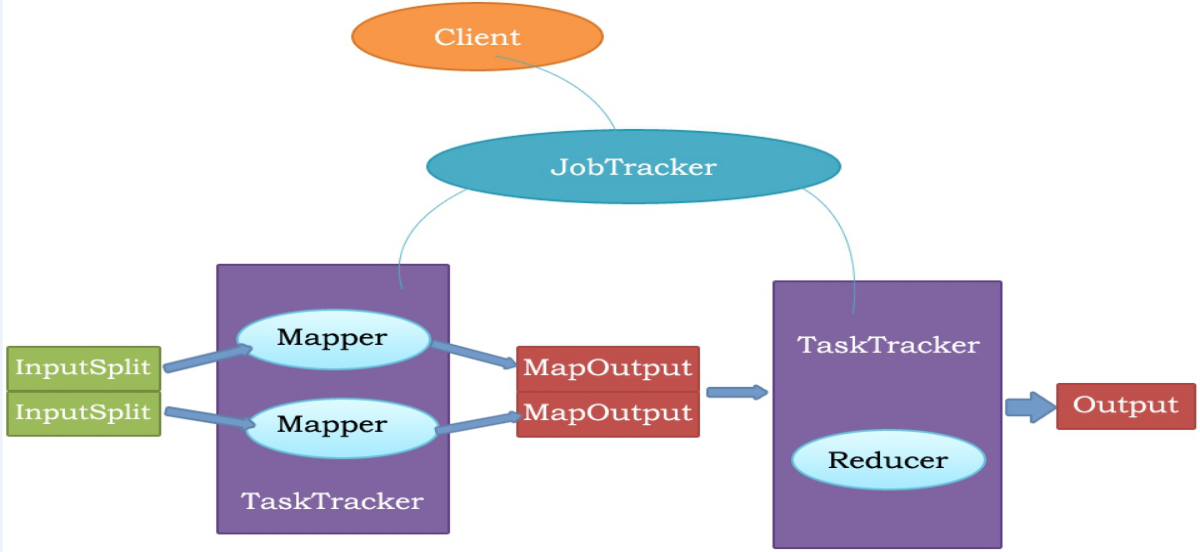
MapReduce原理
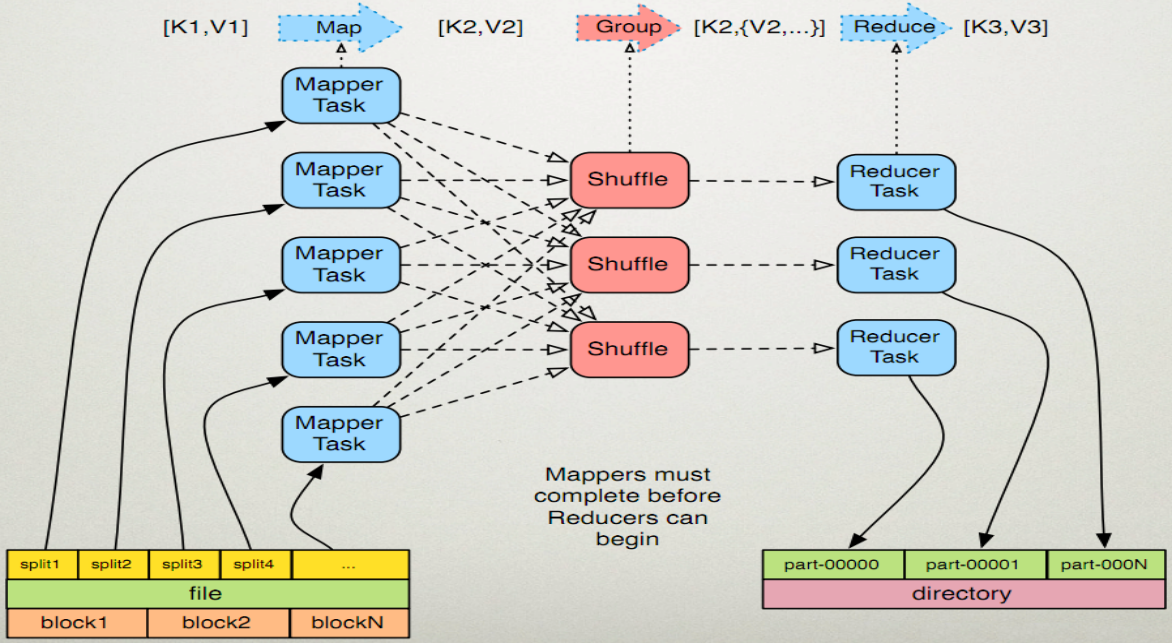
MapReduce的执行步骤:
1、Map任务处理
1.1 读取HDFS中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数。 <0,hello you> <10,hello me>
1.2 覆盖map(),接收1.1产生的<k,v>,进行处理,转换为新的<k,v>输出。 <hello,1> <you,1> <hello,1> <me,1>
1.3 对1.2输出的<k,v>进行分区。默认分为一个区。详见《Partitioner》
1.4 对不同分区中的数据进行排序(按照k)、分组。分组指的是相同key的value放到一个集合中。 排序后:<hello,1> <hello,1> <me,1> <you,1> 分组后:<hello,{1,1}><me,{1}><you,{1}>
1.5 (可选)对分组后的数据进行归约。详见《Combiner》
2、Reduce任务处理
2.1 多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点上。(shuffle)详见《shuffle过程分析》
2.2 对多个map的输出进行合并、排序。覆盖reduce函数,接收的是分组后的数据,实现自己的业务逻辑, <hello,2> <me,1> <you,1>
处理后,产生新的<k,v>输出。
2.3 对reduce输出的<k,v>写到HDFS中。
Java代码实现
注:要导入org.apache.hadoop.fs.FileUtil.java。
1、先创建一个hello文件,上传到HDFS中
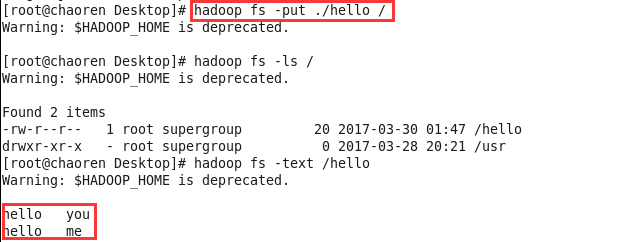
2、然后再编写代码,实现文件中的单词个数统计(代码中被注释掉的代码,是可以省略的,不省略也行)
package mapreduce; import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class WordCountApp {
static final String INPUT_PATH = "hdfs://chaoren:9000/hello";
static final String OUT_PATH = "hdfs://chaoren:9000/out"; public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
Path outPath = new Path(OUT_PATH);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath, true);
} Job job = new Job(conf, WordCountApp.class.getSimpleName()); // 1.1指定读取的文件位于哪里
FileInputFormat.setInputPaths(job, INPUT_PATH);
// 指定如何对输入的文件进行格式化,把输入文件每一行解析成键值对
//job.setInputFormatClass(TextInputFormat.class); // 1.2指定自定义的map类
job.setMapperClass(MyMapper.class);
// map输出的<k,v>类型。如果<k3,v3>的类型与<k2,v2>类型一致,则可以省略
//job.setOutputKeyClass(Text.class);
//job.setOutputValueClass(LongWritable.class); // 1.3分区
//job.setPartitionerClass(org.apache.hadoop.mapreduce.lib.partition.HashPartitioner.class);
// 有一个reduce任务运行
//job.setNumReduceTasks(1); // 1.4排序、分组 // 1.5归约 // 2.2指定自定义reduce类
job.setReducerClass(MyReducer.class);
// 指定reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); // 2.3指定写出到哪里
FileOutputFormat.setOutputPath(job, outPath);
// 指定输出文件的格式化类
//job.setOutputFormatClass(TextOutputFormat.class); // 把job提交给jobtracker运行
job.waitForCompletion(true);
} /**
*
* KEYIN 即K1 表示行的偏移量
* VALUEIN 即V1 表示行文本内容
* KEYOUT 即K2 表示行中出现的单词
* VALUEOUT 即V2 表示行中出现的单词的次数,固定值1
*
*/
static class MyMapper extends
Mapper<LongWritable, Text, Text, LongWritable> {
protected void map(LongWritable k1, Text v1, Context context)
throws java.io.IOException, InterruptedException {
String[] splited = v1.toString().split("\t");
for (String word : splited) {
context.write(new Text(word), new LongWritable(1));
}
};
} /**
* KEYIN 即K2 表示行中出现的单词
* VALUEIN 即V2 表示出现的单词的次数
* KEYOUT 即K3 表示行中出现的不同单词
* VALUEOUT 即V3 表示行中出现的不同单词的总次数
*/
static class MyReducer extends
Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(Text k2, java.lang.Iterable<LongWritable> v2s,
Context ctx) throws java.io.IOException,
InterruptedException {
long times = 0L;
for (LongWritable count : v2s) {
times += count.get();
}
ctx.write(k2, new LongWritable(times));
};
}
}
3、运行成功后,可以在Linux中查看操作的结果

MapReduce的原理及执行过程的更多相关文章
- 通过源码了解ASP.NET MVC 几种Filter的执行过程
一.前言 之前也阅读过MVC的源码,并了解过各个模块的运行原理和执行过程,但都没有形成文章(所以也忘得特别快),总感觉分析源码是大神的工作,而且很多人觉得平时根本不需要知道这些,会用就行了.其实阅读源 ...
- 通过源码了解ASP.NET MVC 几种Filter的执行过程 在Winform中菜单动态添加“最近使用文件”
通过源码了解ASP.NET MVC 几种Filter的执行过程 一.前言 之前也阅读过MVC的源码,并了解过各个模块的运行原理和执行过程,但都没有形成文章(所以也忘得特别快),总感觉分析源码是大神 ...
- MapReduce概述,原理,执行过程
MapReduce概述 MapReduce是一种分布式计算模型,运行时不会在一台机器上运行.hadoop是分布式的,它是运行在很多的TaskTracker之上的. 在我们的TaskTracker上面跑 ...
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- Web APi之过滤器执行过程原理解析【二】(十一)
前言 上一节我们详细讲解了过滤器的创建过程以及粗略的介绍了五种过滤器,用此五种过滤器对实现对执行Action方法各个时期的拦截非常重要.这一节我们简单将讲述在Action方法上.控制器上.全局上以及授 ...
- 四、Struts2的执行过程和原理
执行过程和原理(可能面试题) 学习目标:熟知struts2的执行过程(下图记住).源码可以不看 a.过滤器的初始化 .StrutsPrepareAndExecuteFilter是一个过滤器,过滤器就有 ...
- 分析MapReduce执行过程
分析MapReduce执行过程 MapReduce运行的时候,会通过Mapper运行的任务读取HDFS中的数据文件,然后调用自己的方法,处理数据,最后输出. Reducer任务会接收Mapper任务输 ...
- JSP起源、JSP的运行原理、JSP的执行过程
JSP起源 在很多动态网页中,绝大部分内容都是固定不变的,只有局部内容需要动态产生和改变. 如果使用Servlet程序来输出只有局部内容需要动态改变的网页,其中所有的静态内容也需要程序员用Java程序 ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
随机推荐
- JavaScript中replace()方法的第二个参数解析
语法 string.replace(searchvalue,newvalue) 参数值 searchvalue 必须.规定子字符串或要替换的模式的 RegExp 对象.请注意,如果该值是一个字符串,则 ...
- redis内存模型
前言 Redis是目前最火爆的内存数据库之一,通过在内存中读写数据,大大提高了读写速度,可以说Redis是实现网站高并发不可或缺的一部分. 我们使用Redis时,会接触Redis的5种对象类型(字符串 ...
- 设置view controller到iPhone或者iPad模式
在写iOS程序时,view controller的显示大小以及控件大小的调节是在是一个费力的事,尤其是对于用mac本的童鞋,更难驾驭,这时我们可以根据需要设置专门针对iphone或者ipad的view ...
- jQuery制作鼠标经过显示图片大图,生成图片tips效果
一般tips都是文字,这个可以支持图片,很漂亮: 演示 <script type="text/javascript"> // Load this script on ...
- asp.net中GridView传多个值到其它页面的方法
网站开发中,在页面之间的跳转,经常会用到传值,其中可能会传递多个值. 一.CommadArgument传多个值到其他页面. 像Gridview dataList repeater等数据绑定控件中,可以 ...
- 谁说码农不懂浪漫?(js写的'老婆生日快乐'特效)
一直被老婆抱怨不懂浪漫,老婆的生日又来了,老婆指着闺蜜空间上贴的老公做的胡萝卜心形浪漫晚餐告诉我:必须送她一份用心的礼物.我绞尽脑汁想出这么一法子,还是得用我们码农的独特方式,经过一天多的努力,终于做 ...
- 【leetcode 简单】 第六十题 反转链表
反转一个单链表. 示例: 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL 进阶: 你可以迭代 ...
- 【多视图几何】TUM 课程 第6章 多视图重建
课程的 YouTube 地址为:https://www.youtube.com/playlist?list=PLTBdjV_4f-EJn6udZ34tht9EVIW7lbeo4 .视频评论区可以找到课 ...
- Memcached服务器UDP反射放大攻击
1.前言 2月28日,Memcache服务器被曝出存在UDP反射放大攻击漏洞.攻击者可利用这个漏洞来发起大规模的DDoS攻击,从而影响网络正常运行.漏洞的形成原因为Memcache 服务器UDP 协议 ...
- sql 内联,左联,右联,全联
联合查询效率较高,以下例子来说明联合查询(内联.左联.右联.全联)的好处: T1表结构(用户名,密码) userid (int) username varchar(20) password varc ...