kafka介绍 - 官网
介绍
Kafka是一个分布式的、分区的、冗余的日志提交服务。它使用了独特的设计,提供了所有消息传递系统所具有的功能。
我们先来看下几个消息传递系统的术语:
- Kafka维护消息类别的东西是主题(topic).
- 我们称发布消息到Kafka主题的进程叫生产者(producer).
- 我们称订阅主题、获取消息的进程叫消费者(consumer).
- Kafka是由多个服务器组成的机器,每个服务器称作代理(broker).
在较高的层次上看,生产者通过网络发送消息到Kafka集群,Kafka集群将这些消息提供给消费者,如下图:

客户端与服务器之间的通信通过一个简单的、高性能的、语言无关的TCP protocol. Kafka有Java 客户端,但这客户端在很多语言many languages也是有效的.
主题(Topics)、日志(Logs)
一个主题就是消息的类别或名称。对每个主题,Kafka集群都管理着一个被分区的日志,如下:
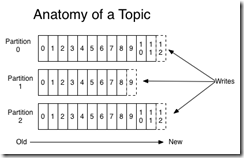
每个分区就是一个提交日志:每个分区上保存着不断被追加的消息,这些消息是有序的且顺序不可改变;分区上的每个消息都被分配了一个序列号offset,offset唯一标识了分区上的消息。
Kafka集群保留所有发布的消息,不管这些消息是否被消费了,直到消息达到了它的存活周期,这个存活周期是可以被配置的。例如,日志被设置保留2天,消息被消费后还将继续存活,直到2天以后它才被删除释放。 数据的大小不会影响Kafka的性能,保留大量数据是没问题的(Kafka's performance is effectively constant with respect to data size so retaining lots of data is not a problem)
事实上,在每个消费者上保留的元数据只有offset,它是消费者在日志上的位置。这个offset受消费者控制:正常情况下,随着消费者读取消息offset是线性增长的,但是消费者可以控制offset,消费者可以以任何顺序消费消息。例如,一个消费者可以重置到老的offset来从新执行。
这些特性表明,Kafka的消费者是非常廉价的,一个消费者的创建、销毁不会对集群或其他消费者产生多大的影响。
对日志进行分区有几个目的:
1、扩容,一个主题可以有多个分区,这使得可以保存比一个机器保存的多的多的数据。
2、并行。
分布式(Distribution)
日志的分区分布在Kafka集群的多台机器上,每个机器管理数据和响应分区请求。每个分区冗余存储来保证容错,冗余数可以配置。
每个分区都有一个机器作为leader,零个或多个机器作为follower。leader处理这个分区的读写请求,follower执行leader的指令。如果leader宕机了,followers中的一个将自动成为新的leader。每个机器都是它的分区的leader和其他分区的follower,follower角色用来负载均衡。
生产者(Producers)
生产者发布数据到它们选择的主题上。生产者负责将某条消息分配到某个主题的某个分区上。这可以通过简单的循环的方式来实现,或者使用一些分区方法(比如根据消息的key来分区)
消费者(Consumers)
传统的消息传递有两种方式: 队列(queuing)、发布-订阅(publish-subscribe). 队列方式,一组消费者从机器上读消息,每个消息只传递给这组消费者中的一个;分布-订阅方式,消息被广播到所有的消费者。 Kafka提供了一个消费组(consumer group)的说法来概括这两种方式。
消费者都有一个消费组,主题的每个消息被传递到订阅这个主题的消费组中的一个消费者实例,消费者实例可以是一个单独的进程或一个单独的机器。
如果所有的消费者在同一个组里,这就相当于队列方式,在消费者上的负载均衡。(If all the consumer instances have the same consumer group, then this works just like a traditional queue balancing load over the consumers.)
如果消费者在不同的组里,这就相当于发布-订阅方式,所有的消息将被广播到所有的消费者。(If all the consumer instances have different consumer groups, then this works like publish-subscribe and all messages are broadcast to all consumers.)
一般的情况是,主题有少量的消费组,每个消费组就是一个逻辑上的订阅者。每个消费组由很多消费者组成,有很好的扩展性和容错。. This is nothing more than publish-subscribe semantics where the subscriber is cluster of consumers instead of a single process.
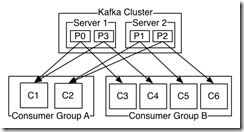
A two server Kafka cluster hosting four partitions (P0-P3) with two consumer groups. Consumer group A has two consumer instances and group B has four.
Kafka比传统的消息传递系统有更好的顺序行保证。
A traditional queue retains messages in-order on the server, and if multiple consumers consume from the queue then the server hands out messages in the order they are stored. However, although the server hands out messages in order, the messages are delivered asynchronously to consumers, so they may arrive out of order on different consumers. This effectively means the ordering of the messages is lost in the presence of parallel consumption. Messaging systems often work around this by having a notion of "exclusive consumer" that allows only one process to consume from a queue, but of course this means that there is no parallelism in processing.
Kafka does it better. By having a notion of parallelism—the partition—within the topics, Kafka is able to provide both ordering guarantees and load balancing over a pool of consumer processes. Kafka将主题下的分区分配给消费组里的消费者,每个分区被一个消费者消费,This is achieved by assigning the partitions in the topic to the consumers in the consumer group so that each partition is consumed by exactly one consumer in the group. By doing this we ensure that the consumer is the only reader of that partition and consumes the data in order. Since there are many partitions this still balances the load over many consumer instances. 消费者的数量不能超过分区数Note however that there cannot be more consumer instances than partitions.
Kafka只能保证分区内的消息是有序的 only provides a total order over messages within a partition, not between different partitions in a topic. Per-partition ordering combined with the ability to partition data by key is sufficient for most applications.如果你想要消息是全局有序的,你可以设置主题只有一个分区,同时这意味着只能有一个消费者。 However, if you require a total order over messages this can be achieved with a topic that has only one partition, though this will mean only one consumer process.
保证(Guarantees)
At a high-level Kafka gives the following guarantees:
- 生产者发送的消息安装它们发送的顺序追加到主题
- 消费者看到消息的顺序就是消息在日志中存储的顺序
- For a topic with replication factor N, we will tolerate up to N-1 server failures without losing any messages committed to the log.
More details on these guarantees are given in the design section of the documentation.
来源: <http://kafka.apache.org/documentation.html#introduction>
kafka介绍 - 官网的更多相关文章
- 3 kafka介绍
本博文的主要内容有 .kafka的官网介绍 http://kafka.apache.org/ 来,用官网上的教程,快速入门. http://kafka.apache.org/documentatio ...
- 【工利其器】必会工具之(二)Android开发者官网篇
前言 当刚开始踏入Android程序员这个行业的时候,想必绝大多数的人都和笔者一样,热血沸腾,激情四射,买了很多讲解Android开发的书籍.当开发某个功能需要学习某方面知识的时候,大家又成了“面向百 ...
- Spring官网阅读(八)容器的扩展点(三)(BeanPostProcessor)
在前面两篇关于容器扩展点的文章中,我们已经完成了对BeanFactoryPostProcessor很FactoryBean的学习,对于BeanFactoryPostProcessor而言,它能让我们对 ...
- hadoop官网介绍及如何下载hadoop(2.4)各个版本与查看hadoop API介绍
1.如何访问hadoop官网?2.如何下载hadoop各个版本?3.如何查看hadoop API? 很多同学开发都没有二手资料,原因很简单觉得不会英语,但是其实作为软件行业,多多少少大家会英语的,但是 ...
- dubbo系列一:dubbo介绍、dubbo架构、dubbo的官网入门使用demo
一.dubbo介绍 Dubbo是阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的RPC实现服务的输出和输入功能,可以和Spring框架无缝集成.简单地说,dubbo是一个基于Spri ...
- Nordic官方网络资源介绍(官网/devzone/GitHub)
本文将介绍Nordic官方网络资源,包括Nordic官网,开发者论坛(devzone),以及Nordic在GitHub上的共享资源. 1. Nordic官网(产品/SDK/工具/文档库) Nordic ...
- springmvc系列一 之配置介绍(包含官网doc)
1.springmvc 官网参考地址: https://docs.spring.io/spring/docs/current/spring-framework-reference/web.html 2 ...
- 1.3 Quick Start中 Step 8: Use Kafka Streams to process data官网剖析(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Step 8: Use Kafka Streams to process data ...
- 1.3 Quick Start中 Step 7: Use Kafka Connect to import/export data官网剖析(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Step 7: Use Kafka Connect to import/export ...
随机推荐
- ThreadLocal的实现机制
TLS(Thread Local Storage)通过分配更多内存来解决多线程对临界资源访问的互斥问题,即每个线程均自己的临界资源对象, 这样也就不会发生访问冲突,也不需要锁机制控制,比较典型的以空间 ...
- 漫谈NIO(2)之Java的NIO
1.前言 上章提到过Java的NIO采取的是多路IO复用模式,其衍生出来的模型就是Reactor模型.多路IO复用有两种方式,一种是select/poll,另一种是epoll.在windows系统上使 ...
- Java之集合(十三)WeakHashMap
转载请注明源出处:http://www.cnblogs.com/lighten/p/7423818.html 1.前言 本章介绍一下WeakHashMap,这个类也很重要.要想明白此类的作用,先要明白 ...
- java泛型---通配符,泛型嵌套
package generic; import java.util.ArrayList; import java.util.List; /** * ? -->通配符,类型不确定,用于声明 变量| ...
- elasticsearch(一) 之 elasticsearch初识
目录 一 .elasticsearch 二 . elasticsearch 名词解释 集群(cluster) 节点(node) 索引(index) type(类型) Document(文档) shar ...
- elasticsearch插件安装之--linux下安装及head插件
/** * 系统环境: vm12 下的centos 7.2 * 当前安装版本: elasticsearch-2.4.0.tar.gz */ 安装和学习可参照官方文档: 1, 安装 # 下载, 获取不成 ...
- Spring4.x所有Maven依赖
Spring4.x所有Maven依赖 定义Spring版本号 1 <properties> 2 <org.springframework.version>4.3.7.RELEA ...
- 基于json-lib-2.2.2-jdk15.jar的JSON解析工具类大集合
json解析之前的必备工作:导入json解析必须的六个包 资源链接:百度云:链接:https://pan.baidu.com/s/1dAEQQy 密码:1v1z 代码示例: package com.s ...
- 浅析人脸检测之Haar分类器方法:Haar特征、积分图、 AdaBoost 、级联
浅析人脸检测之Haar分类器方法 一.Haar分类器的前世今生 人脸检测属于计算机视觉的范畴,早期人们的主要研究方向是人脸识别,即根据人脸来识别人物的身份,后来在复杂背景下的人脸检测需求越来越大,人脸 ...
- 关于SVN提交注释的问题
如果客户端是TortoiseSVN的话,在客户端要设置的版本库上点右键,选择菜单TortoiseSVN--属性,新建属性,选择属性tsvn:logminsize,设置log的最短长度,然后提交.然后如 ...