强化学习(六):n-step Bootstrapping
n-step Bootstrapping
n-step 方法将Monte Carlo 与 one-step TD统一起来。 n-step 方法作为 eligibility traces 的引入,eligibility traces 可以同时的在很多时间间隔进行bootstrapping.
n-step TD Prediction
one-step TD 方法只是基于下一步的奖励,通过下一步状态的价值进行bootstrapping,而MC方法则是基于某个episode的整个奖励序列。n-step 方法则是基于两者之间。使用n 步更新的方法被称作n-step TD 方法。
对于MC方法,估计\(v_{\pi}(S_t)\), 使用的是完全收益(complete return)是:
\]
而在one-step TD方法中,则是一步收益(one-step return):
\]
那么n-step return:
\]
其中 \(n\ge 1, 0\le t< T-n\)。
因为在t+n 时刻才可知道 \(R_{t+n}, V_{t+n-1}\) ,故可定义:
\]
# n-step TD for estimating V = v_pi
Input: a policy pi
Algorithm parameters: step size alpha in (0,1], a positive integer n
Initialize V(s) arbitrarily, s in S
All store and access operations (for S_t and R_t) can take their index mod n+1
Loop for each episode:
Initialize and store S_0 != terminal
T = infty
Loop for t = 0,1,2,...
if t < T, then:
Take an action according to pi(.|S_t)
Observe and store the next reward as R_{t+1} and the next state as S_{t+1}
If S_{t+1} is terminal, then T = t + 1
tau = t - n + 1 (tau is the time whose state's estimate is being updated)
if tau >= 0:
G = sum_{i = tau +1}^{min(tau+n,T)} gamma^{i-tau-1} R_i
if tau + n < T, then G = G + gamma^n V(S_{tau+n})
V(S_{tau}) = V(S_{tau} + alpha [G - V(S_tau)])
Until tau = T - 1
n-step Sarsa
与n-step TD方法类似,只不过n-step Sarsa 使用的state-action对,而不是state:
\]
自然地:
\]
# n-step Sarsa for estimating Q = q* or q_pi
Initialize Q(s,a) arbitrarily, for all s in S, a in A
Initialize pi to be e-greedy with respect to Q, or to a fixed given policy
Algorithm parameters: step size alpha in (0,1], small e >0, a positive integer n
All store and access operations (for S_t, A_t and R_t) can take their index mod n+1
Loop for each episode:
Initialize and store S_o != terminal
Select and store an action A_o from pi(.|S_0)
T = infty
Loop for t = 0,1,2,...:
if t < T, then:
Take action A_t
Observe and store the next reward as R_{t+1} and the next state as S_{t+1}
If S_{t+1} is terminal, then:
T = t + 1
else:
Select and store an action A_{t+1} from pi(.|S_{t+1})
tau = t - n + 1 (tau is the time whose estimate is being updated)
if tau >= 0:
G = sum_{i = tau+1}^{min(tau+n,T)} gamma^{i-tau-1}R_i
if tau + n < T, then G = G + gamma^nQ(S_{tau +n}, A_{tau+n})
Q(S_tau,A_tau) = Q(S_{tau},A_{tau}) + alpha [ G - Q(S_{tau},A_{tau})]
至于 Expected Sarsa:
\]
\]
n-step Off-policy Learning by Importance Sampling
一个简单off-policy 版的 n-step TD:
\]
其中 \(\rho_{t:t+n-1}\) 是 importance sampling ratio:
\]
off-policy n-step Sarsa更新形式:
\]
# Off-policy n-step Sarsa for estimating Q = q* or q_pi
Input: an arbitrary behavior policy b such that b(a|s) > 0, for all s in S, a in A
Initialize pi to be greedy with respect to Q, or as a fixed given policy
Algorithm parameters: step size alpha in (0,1], a positive integer n
All store and access operations (for S_t, A_t, and R_t) can take their index mod n + 1
Loop for each episode:
Initialize and store S_0 != terminal
Select and store an action A_0 from b(.|S0)
T = infty
Loop for t = 0,1,2,...:
if t<T, then:
take action At
Observe and store the next reward as R_{t+1} and the next state as S_{t+1}
if S_{t+1} is terminal, then:
T = t+1
else:
select and store an action A_{t+1} from b(.|S_{t+1})
tau = t - n + 1 (tau is the time whose estimate is being updated)
if tau >=0:
rho = \pi_{i = tau+1}^min(tau+n-1, T-1) pi(A_i|S_i)/b(A_i|S_i)
G = sum_{i = tau +1}^min(tau+n, T) gamma^{i-tau-1}R_i
if tau + n < T, then: G = G + gamma^n Q(S_{tau+n}, A_{tau+n})
Q(S_tau,A_tau) = Q(S_tau, A_tau) + alpha rho [G-Q(s_tau, A_tau)]
if pi is being learned, then ensure that pi(.|S_tau) is greedy wrt Q
Until tau = T - 1
Per-decision Off-policy Methods with Control Variates
pass
Off-policy Learning without Importance Sampling: The n-step Tree Backup Algorithm
tree-backup 算法是一种可以不借助importance sampling的off-policy n-step 方法。 tree-backup 的更新基于整个估计行动价值树,或者说,更新是基于树中叶结点(未被选中的行动)的估计的行动价值。树的内部的行动结点(即实际被选择的行动)不参加更新。
\]
G_{t:t+2} &\dot =& R_{t+1} + \gamma\sum_{a \ne A_{t+1}} \pi(a|S_{t+1})Q_{t+1}(S_{t+1},a)+ \gamma \pi(A_{t+1}|S_{t+1})(R_{t+2}+\gamma \sum_{a}\pi(a|S_{t+2},a)) \\
& = & R_{t+1} + \gamma\sum_{a\ne A_{t+1}}\pi(a|S_{t+1})Q_{t+1}(S_{t+1},a) + \gamma\pi(A_{t+1}|S_{t+1})G_{t+1:t+2}
\end{array}
\]
于是
\]
算法更新规则:
\]
# n-step Tree Backup for estimating Q = q* or q_pi
Initialize Q(s,a) arbitrarily, for all s in S, a in A
Initialize pi to be greedy with respect to Q, or as a fixed given policy
Algorithm parameters: step size alpha in (0,1], a positive integer n
All store and access operations can take their index mod n+1
Loop for each episode:
Initialize and store S_0 != terminal
Choose an action A_0 arbitrarily as a function of S_0; Store A_0
T = infty
Loop for t = 0,1,2,...:
If t < T:
Take action A_t; observe and store the next reward and state as R_{t+1}, S_{t+1}
if S_{t+1} is terminal:
T = t + 1
else:
Choose an action A_{t+1} arbitrarily as a function of S_{t+1}; Store A_{t+1}
tau = t+1 - n (tau is the time whose estimate is being updated)
if tau >= 0:
if t + 1 >= T:
G = R_T
else:
G = R_{t+1} + gamma sum_{a} pi(a|S_{t+1})Q(S_{t+1},a)
Loop for k = min(t, T - 1) down through tau + 1:
G = R_k + gamma sum_{a != A_k}pi(a|S_k)Q(S_k,a) + gamma pi(A_k|S_k) G
Q(S_tau,A_tau) = Q(S_tau,A_tau) + alpha [G - Q(S_tau,A_tau)]
if pi is being learned, then ensure that pi(.|S_tau) is greedy wrt Q
Until tau = T - 1
*A Unifying Algorithm: n-step Q(\(\sigma\))
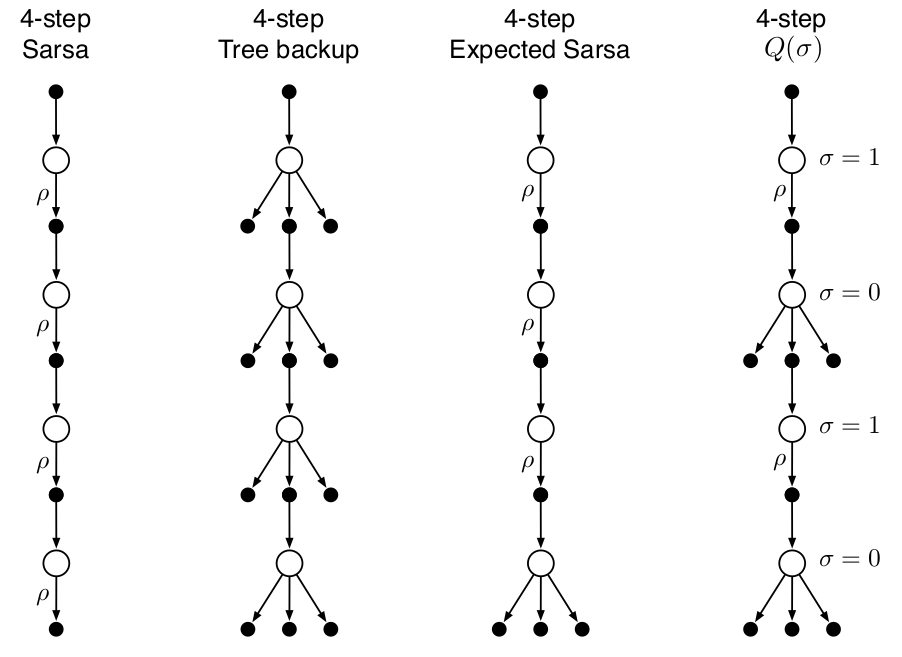
在n-step Sarsa方法中,使用所有抽样转换(transitions), 在tree-backup 方法中,使用state-to-action所有分支的转换,而非抽样,而在期望 n-step 方法中,除了最后一步不使用抽样而使用所有分支的转换外,其他所有都进行抽样转换。
为统一以上三种算法,有一种思路是引入一个随机变量抽样率:\(\sigma\in [0,1]\),当其取1时,表示完全抽样,当取0时表示使用期望而不抽样。
根据tree-backup n-step return (h = t + n)以及\(\bar V\):
G_{t:h} &\dot =& R_{t+1} + \gamma\sum_{a\ne A_{t+1}}\pi(a|S_{t+1})Q_{t+1}(S_{t+1},a) + \gamma\pi(A_{t+1}|S_{t+1})G_{t+1:h}\\
& = & R_{t+1} +\gamma \bar V_{h-1} (S_{t+1}) - \gamma\pi(A_{t+1}|S_{t+1})Q_{h-1}(S_{t+1},A_{t+1}) + \gamma\pi(A_{t+1}| S_{t+1})G_{t+1:h}\\
& =& R_{t+1} +\gamma\pi(A_{t+1}|S_{t+1})(G_{t+1:h} - Q_{h-1}(S_{t+1},A_{t+1})) + \gamma \bar V_{h-1}(S_{t+1})\\
\\
&& (\text{引入}, \sigma)\\
\\
& = & R_{t+1} + \gamma(\sigma_{t+1}\rho_{t+1} + (1 - \sigma_{t+1})\pi(A_{t+1}|S_{t+1}))(G_{t+1:h} - Q_{h-1}(S_{t+1}, A_{t+1})) + \gamma \bar V_{h-1}(S_{t+1})
\end{array}
\]
# n-step Tree Backup for estimating Q = q* or q_pi
Initialize Q(s,a) arbitrarily, for all s in S, a in A
Initialize pi to be greedy with respect to Q, or as a fixed given policy
Algorithm parameters: step size alpha in (0,1], a positive integer n
All store and access operations can take their index mod n+1
Loop for each episode:
Initialize and store S_0 != terminal
Choose an action A_0 arbitrarily as a function of S_0; Store A_0
T = infty
Loop for t = 0,1,2,...:
If t < T:
Take action A_t; observe and store the next reward and state as R_{t+1}, S_{t+1}
if S_{t+1} is terminal:
T = t + 1
else:
Choose an action A_{t+1} arbitrarily as a function of S_{t+1}; Store A_{t+1}
Select and store sigma_{t+1}
Store rho_{t+1} = pi(A_{t+1}|S_{t+1})/b(A_{t+1}|S_{t+1})
tau = t+1 - n (tau is the time whose estimate is being updated)
if tau >= 0:
G = 0
Loop for k = min(t, T - 1) down through tau + 1:
if k = T:
G = R_t
else:
V_bar = sum_{a} pi(a|S_k) Q(S_k,a)
G = R_k + gamma(simga_k rho_k + (1-simga_k)pi(A_k|S_k))(G - Q(S_k,A_k)) + gamma V_bar
Q(S_tau,A_tau) = Q(S_tau,A_tau) + alpha [G - Q(S_tau,A_tau)]
if pi is being learned, then ensure that pi(.|S_tau) is greedy wrt Q
Until tau = T - 1
强化学习(六):n-step Bootstrapping的更多相关文章
- 强化学习(六)时序差分在线控制算法SARSA
在强化学习(五)用时序差分法(TD)求解中,我们讨论了用时序差分来求解强化学习预测问题的方法,但是对控制算法的求解过程没有深入,本文我们就对时序差分的在线控制算法SARSA做详细的讨论. SARSA这 ...
- 【转载】 强化学习(六)时序差分在线控制算法SARSA
原文地址: https://www.cnblogs.com/pinard/p/9614290.html ------------------------------------------------ ...
- 强化学习(十六) 深度确定性策略梯度(DDPG)
在强化学习(十五) A3C中,我们讨论了使用多线程的方法来解决Actor-Critic难收敛的问题,今天我们不使用多线程,而是使用和DDQN类似的方法:即经验回放和双网络的方法来改进Actor-Cri ...
- 强化学习(五)用时序差分法(TD)求解
在强化学习(四)用蒙特卡罗法(MC)求解中,我们讲到了使用蒙特卡罗法来求解强化学习问题的方法,虽然蒙特卡罗法很灵活,不需要环境的状态转化概率模型,但是它需要所有的采样序列都是经历完整的状态序列.如果我 ...
- 强化学习(八)价值函数的近似表示与Deep Q-Learning
在强化学习系列的前七篇里,我们主要讨论的都是规模比较小的强化学习问题求解算法.今天开始我们步入深度强化学习.这一篇关注于价值函数的近似表示和Deep Q-Learning算法. Deep Q-Lear ...
- 强化学习(七)时序差分离线控制算法Q-Learning
在强化学习(六)时序差分在线控制算法SARSA中我们讨论了时序差分的在线控制算法SARSA,而另一类时序差分的离线控制算法还没有讨论,因此本文我们关注于时序差分离线控制算法,主要是经典的Q-Learn ...
- 【转载】 强化学习(八)价值函数的近似表示与Deep Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9714655.html ------------------------------------------------ ...
- 【转载】 强化学习(七)时序差分离线控制算法Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9669263.html ------------------------------------------------ ...
- 强化学习中的无模型 基于值函数的 Q-Learning 和 Sarsa 学习
强化学习基础: 注: 在强化学习中 奖励函数和状态转移函数都是未知的,之所以有已知模型的强化学习解法是指使用采样估计的方式估计出奖励函数和状态转移函数,然后将强化学习问题转换为可以使用动态规划求解的 ...
- DRL强化学习:
IT博客网 热点推荐 推荐博客 编程语言 数据库 前端 IT博客网 > 域名隐私保护 免费 DRL前沿之:Hierarchical Deep Reinforcement Learning 来源: ...
随机推荐
- mysql 5.7 配置文件说明
1.配置文件样例 [client] #password= socket=/data/var/mysql/mysql.sock [mysqld_safe] pid-file=/data/var/mysq ...
- 我的python思考
1.因为例如线性代数之类的数学题较难解决,会耽误我很长时间,所以我希望课程涉及关于数学的库的使用:因为各种考试,例如英语四六级甚至研究生考试各种单词或者关键词都会有使用频率,所以我希望涉及爬虫的应用. ...
- 外网访问内网Docker容器
外网访问内网Docker容器 本地安装了Docker容器,只能在局域网内访问,怎样从外网也能访问本地Docker容器? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Docker容器 ...
- poj3984迷宫问题(DFS广搜)
迷宫问题 Time Limit: 1000MSMemory Limit: 65536K Description 定义一个二维数组: int maze[5][5] = { 0, 1, 0, 0, 0, ...
- [Python数据挖掘]第8章、中医证型关联规则挖掘
一.背景和挖掘目标 二.分析方法与过程 1.数据获取 2.数据预处理 1.筛选有效问卷(根据表8-6的标准) 共发放1253份问卷,其中有效问卷数为930 2.属性规约 3.数据变换 ''' 聚类 ...
- Overture小课堂之如何演绎钢琴滑音
在我们学习钢琴和学习使用Overture时,要学习如何弹奏和使用滑音.那么我们先来看看什么是滑音,如何使用钢琴演绎,在Overture里滑音又在哪里呢? 滑音,在音乐术语中通常指一种装饰音和演奏指法. ...
- 20171017数据处理sql
SELECT LEFT(RIGHT(进场时间,8),2), 车牌号,进场时间,支付时间 FROM 停车收费详情$;1是周日,7是周六SELECT COUNT(*),周几 FROM date_parts ...
- Cent OS6下SS+BBR+改SSH端口
SS+BBR+改SSH端口 (一)搭建SS wget --no-check-certificate -O shadowsocks-libev.sh https://raw.githubusercont ...
- Android ANR(应用无响应)解决分析【转】
本文转载自:https://blog.csdn.net/u014630142/article/details/81709459 来自: http://blog.csdn.net/tjy1985/art ...
- DRF认证组件流程分析
视图函数中加上认证功能,流程见下图 import hashlib import time def get_random(name): md = hashlib.md5() md.update(byte ...