RDD(二)——创建
RDD的创建
1)从内存中创建
从集合中创建RDD,Spark主要提供了两种函数:parallelize和makeRDD
val raw: RDD[Int] = sc.parallelize(1 to 16)
val raw: RDD[Int] = sc.makeRDD(1 to 16)
2)从外部文件中创建
val line: RDD[String] = sc.textFile("E:/idea/spark2/in/info.log")
RDD的分区数
从内存中创建RDD的分区,得到分区数的源码如下:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}
/*
如果没有指定分区数量这个参数,那么就采用默认的分区数量defaultParallelism,
那么这个参数如何得到的呢?
*/
override def defaultParallelism(): Int = {
conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))
}
def getInt(key: String, defaultValue: Int): Int = catchIllegalValue(key) {
getOption(key).map(_.toInt).getOrElse(defaultValue)
}
/*
它会拿着spark.default.parallelism这个配置文件中的参数,去配置文件中获取值;
如果这个值没有,也就是没配,那么就由:
math.max(totalCoreCount.get(), 2)来决定;
即核数和2中的最大值;
*/
从文件系统中宏创建分区,得到分区数的原码原码如下:
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
/*
同样的,如果分区数这个参数没有被指定,就由defaultMinPartitions这个参数决定;
*/ def defaultMinPartitions: Int = math.min(defaultParallelism, 2) /*
这个参数是由 math.min(defaultParallelism, 2)这个表达式来决定的;
defaultParallelism这个参数的计算方式同上;所以,如果没有指定分区数量,分区数量一般都是2;
*/
接下来验证对上述原码理解
从内存中创建:
def main(args: Array[String]): Unit = {
val sc: SparkContext = new SparkContext(new SparkConf()
.setMaster("local[*]").setAppName("spark")
.set("spark.default.parallelism","3"))
/*通过sparkconf对象的set方法来配置spark.default.parallelism这一参数*/
val raw: RDD[Int] = sc.makeRDD(Array[Int](1, 2, 3, 4, 5, 6))
raw.saveAsTextFile("E:/idea/spark2/out")
}
查看分区数,发现数据被分散在三个分区:
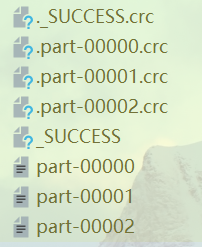
从文件系统创建:
def main(args: Array[String]): Unit = {
val sc: SparkContext = new SparkContext(new SparkConf()
.setMaster("local[*]").setAppName("spark")
.set("spark.default.parallelism","3"))
val raw: RDD[String] = sc.textFile("E:/idea/spark2/in/word.txt")
raw.saveAsTextFile("E:/idea/spark2/out/word")
}
但是这次的分区数只有两个:
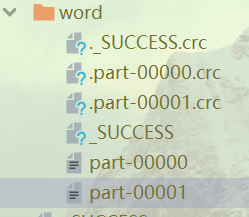
RDD(二)——创建的更多相关文章
- Spark-Core RDD的创建
一.RDD创建的3种方式: 1.从集合中创建RDD 2.从外部存储创建RDD 3.从其他RDD转换得到新的RDD 二.从集合中创建RDD 1.使用parallelize函数创建 scala> v ...
- 【Spark】快来学习RDD的创建以及操作方式吧!
目录 RDD的创建 三种方式 从一个集合中创建 从文件中创建 从其他的RDD转化而来 RDD编程常用API 算子分类 Transformation 概述 帮助文档 常用Transformation表 ...
- MVC5 网站开发之二 创建项目
昨天对项目的思路大致理了一下,今天先把解决方案建立起来.整个解决包含Ninesky.Web.Ninesky.Core,Ninesky.DataLibrary等3个项目.Ninesky.Web是web应 ...
- Spark RDD概念学习系列之RDD的创建(六)
RDD的创建 两种方式来创建RDD: 1)由一个已经存在的Scala集合创建 2)由外部存储系统的数据集创建,包括本地文件系统,还有所有Hadoop支持的数据集,比如HDFS.Cassandra.H ...
- DevExpress XtraReports 入门二 创建 data-aware(数据感知) 报表
原文:DevExpress XtraReports 入门二 创建 data-aware(数据感知) 报表 本文只是为了帮助初次接触或是需要DevExpress XtraReports报表的人群使用的, ...
- 从零开始学习 asp.net core 2.1 web api 后端api基础框架(二)-创建项目
原文:从零开始学习 asp.net core 2.1 web api 后端api基础框架(二)-创建项目 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.ne ...
- 爬虫(二)-创建项目&应用
一.回顾 上篇已经讲解了python-django的环境搭建,本次将继续上次的课程,开始创建项目及应用. 上篇的验证结果为: 本次将加上创建应用之后浏览器打开演示~ 二.创建项目 1)使用django ...
- AOP源码解析之二-创建AOP代理前传,获取AOP信息
AOP源码解析之二-创建AOP代理前传,获取AOP信息. 上篇文章对AOP的基本概念说清楚了,那么接下来的AOP还剩下两个大的步骤获取定义的AOP信息,生成代理对象扔到beanFactory中. 本篇 ...
- NET中的规范标准注释(二) -- 创建帮助文档入门篇
一.摘要 在本系列的第一篇文章介绍了.NET中XML注释的用途, 本篇文章将讲解如何使用XML注释生成与MSDN一样的帮助文件.主要介绍NDoc的继承者:SandCastle. 二.背景 要生成帮助文 ...
随机推荐
- Vulkan SDK 之 Device
Enumerate Physical Devices Vulkan instance创建完成之后,vulkan loader是知道你有几个物理设备(显卡),但是程序不知道,需要通过 相关接口获取设备 ...
- spring+springMVC+mybatis , 项目启动遇坑
github上找的框架组合例子 结合自己的数据库作为新项目开发. 但是项目启动时,tomcat启动失败: 检查不出错误. 于是改换maven引入jetty插件来启动项目, 结果在未改动的任何代码的情况 ...
- spring boot 接口返回值封装
Spring Boot 集成教程 Spring Boot 介绍 Spring Boot 开发环境搭建(Eclipse) Spring Boot Hello World (restful接口)例子 sp ...
- Tensorflow学习教程------简单练一波,线性模型
#coding:utf-8 import tensorflow as tf import numpy as np #使用numpy 生成100个随机点 x_data = np.random.rand( ...
- C#调用C++系列一:简单传值
因为去实习的时候有一个小任务是C#想调用C++ opencv实现的一些处理,那我主要的想法就是将C++实现的OpenCV处理封装成dll库供C#调用,这里面还会涉及到一些托管和非托管的概念,我暂时的做 ...
- (day 1)创建项目--1
1.利用cmd(命令行)创建项目myblog 确定好项目要放在哪个directory. dir一下创建好的项目看下有什么 django自带有一个小型的服务器可通过 runserver 启动它 可取浏 ...
- share团队冲刺10
团队冲刺第十天 昨天:完善代码,美化界面 今天:整合全部代码,基本完成作品 问题:无
- ZOJ 1454 dp
Employment Planning Time Limit:2000MS Memory Limit:65536KB 64bit IO Format:%lld & %llu S ...
- .net core excel导入导出
做的上一个项目用的是vs2013,传统的 Mvc模式开发的,excel报表的导入导出都是那几段代码,已经习惯了. 导入:string filename = ExcelFileUpload.FileNa ...
- 2)将普通工程变成动态库dll
1)打开那个工程: 2)然后 看属性里面的控制平台: