入门大数据---HDFS-API
第一步:创建一个新的项目 并导入需要的jar包
公共核心包
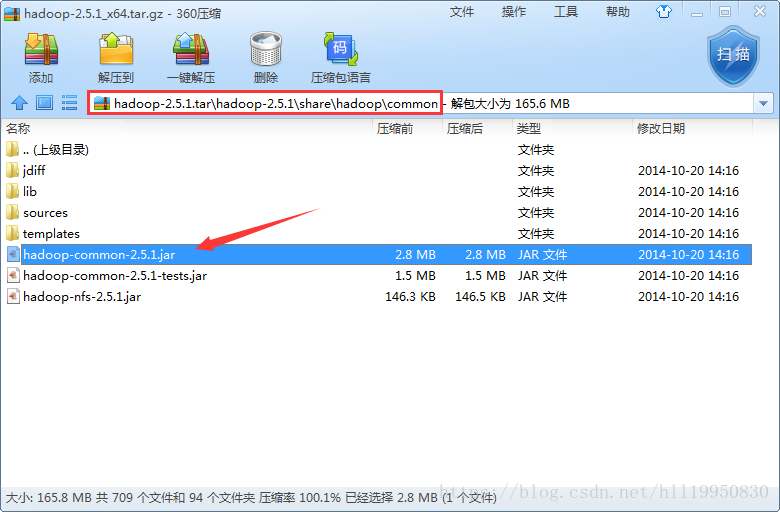
公共依赖包

hdfs核心包

hdfs依赖包
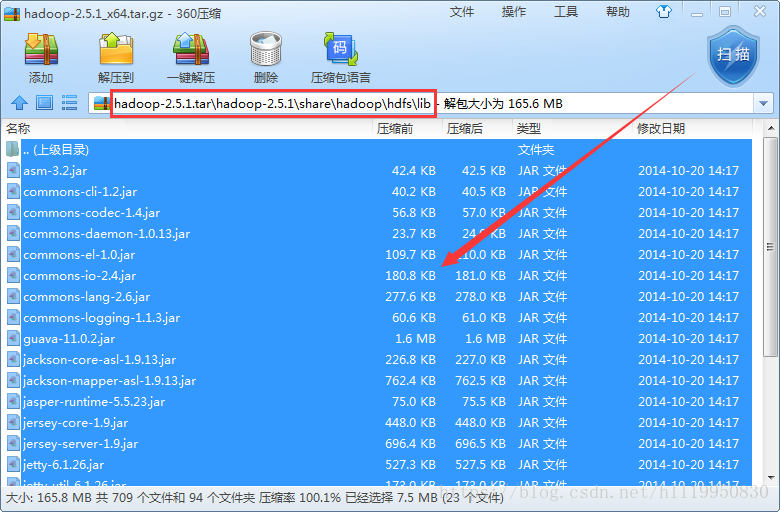
第二步:将Linux中hadoop的配置文件拷贝到项目的src目录下

第三步:配置windows本地的hadoop环境变量(HADOOP_HOME:hadoop的安装目录 Path:在后面添加hadoop下的bin目录)
第四步:使用windows下编译好的hadoop替换hadoop的bin目录和lib目录
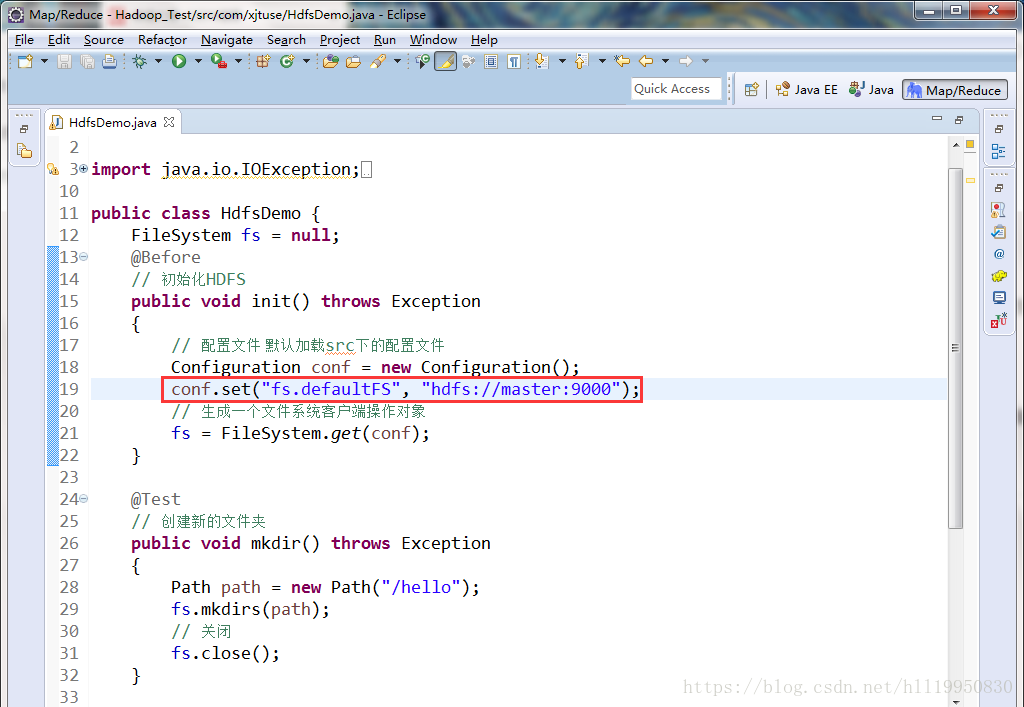
第五步:使用FileSystem对象对hdfs进行操作(注意:FileSystem默认是本地文件系统 因此要通过Configuration对象配置为hdfs系统)
第六步:在运行之前 需要保证本地的用户名和hadoop的用户名一致 在不修改windows用户名的情况下 可以配置Eclipse的参数实现:右击项目->Run As ->Run Configurations
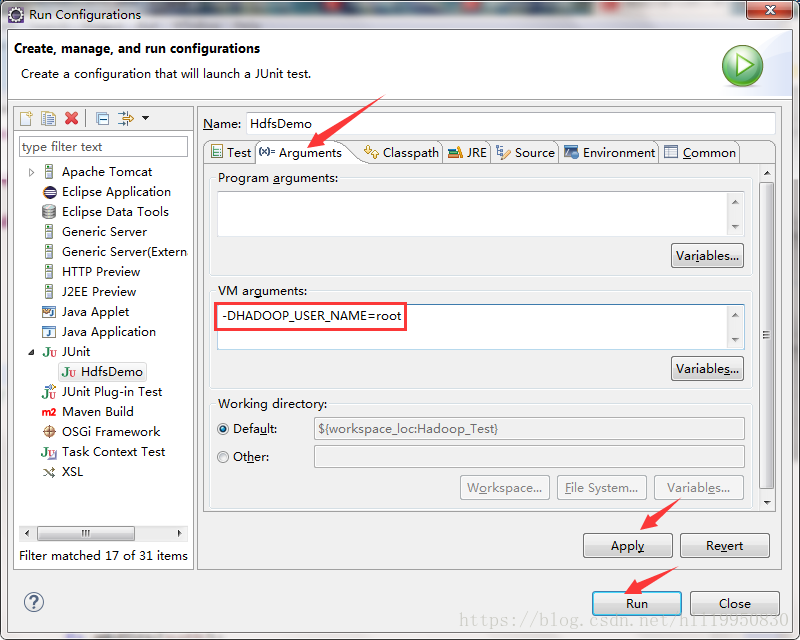
运行即可成功上传本地文件到hdfs
代码如下:
package com.xjtuse;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Before;
import org.junit.Test;
public class HdfsDemo {
FileSystem fs = null;
@Before
// 初始化HDFS
public void init() throws Exception
{
// 配置文件 默认加载src下的配置文件
Configuration conf = new Configuration();
// conf.set("fs.defaultFS", "hdfs://master:9000");
// 生成一个文件系统客户端操作对象
// fs = FileSystem.get(conf);
// 第一个参数是URI指明了是hdfs文件系统 第二个参数是配置文件 第三个参数是指定用户名 需要与hadoop用户名保持一致
fs = FileSystem.get(new URI("hdfs://master:9000"), conf, "root");
}
@Test
// 创建新的文件夹
public void mkdir() throws Exception
{
Path path = new Path("/hello");
fs.mkdirs(path);
// 关闭
fs.close();
}
@Test
// 上传文件
public void upload() throws Exception
{
// 第一个参数是本地windows下的文件路径 第二个参数是hdfs的文件路径
fs.copyFromLocalFile(new Path("F:/Files/data/README.txt"), new Path("/"));
// 关闭
fs.close();
}
}
转自: https://blog.csdn.net/hll19950830/article/details/79824928
补充:最后我们运行可能报如下异常。

这个时候在项目根目录下创建一个文件命名为log4j.properties并填写如下内容,然后重新运行就好了。
hadoop.root.logger=DEBUG, console
log4j.rootLogger = DEBUG, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
有的时候我们新建文件的时候选择File->New没有选择文件这个选项,这个时候不用着急,它给隐藏了,找到Window->Perspective->Customize Perspective 勾选上File即可。
更多内容参阅官方API文档。
入门大数据---HDFS-API的更多相关文章
- 入门大数据---HDFS,Zookeeper,ZookeeperFailOverController(简称:ZKFC),JournalNode是什么?
HDFS介绍: 简述: Hadoop Distributed File System(HDFS)是一种分布式文件系统,设计用于在商用硬件上运行.它与现有的分布式文件系统有许多相似之处.但是,与其他分布 ...
- 入门大数据---Spark_Structured API的基本使用
一.创建DataFrame和Dataset 1.1 创建DataFrame Spark 中所有功能的入口点是 SparkSession,可以使用 SparkSession.builder() 创建.创 ...
- 入门大数据---Spark整体复习
一. Spark简介 1.1 前言 Apache Spark是一个基于内存的计算框架,它是Scala语言开发的,而且提供了一站式解决方案,提供了包括内存计算(Spark Core),流式计算(Spar ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
- 入门大数据---Kylin是什么?
一.Kylin是什么? Apache Kylin是一个开源的.分布式的分析型数据仓库,提供Hadoop/Spark 上的SQL查询接口及多维度分析(OLAP)能力以支持超大规模的数据,最初由eBay开 ...
- 大数据-hdfs技术
hadoop 理论基础:GFS----HDFS:MapReduce---MapReduce:BigTable----HBase 项目网址:http://hadoop.apache.org/ 下载路径: ...
- 入门大数据---MapReduce-API操作
一.环境 Hadoop部署环境: Centos3.10.0-327.el7.x86_64 Hadoop2.6.5 Java1.8.0_221 代码运行环境: Windows 10 Hadoop 2.6 ...
- 入门大数据---安装ClouderaManager,CDH和Impala,Hue,oozie等服务
1.要求和支持的版本 (PS:我使用的环境,都用加粗标识了.) 1.1 支持的操作系统版本 操作系统 版本 RHEL/CentOS/OL with RHCK kernel 7.6, 7.5, 7.4, ...
随机推荐
- cpprestsdk同时使用boost.asio,acceptor就一直报Invalid argument。
本文目录,首先总结问题,然后案例还原. 总结: 问题的根本在于boost.asio作为header-only库,运行程序与动态库之间容易因为版本错配而产生运行期莫名其妙的问题. cpprestsdk使 ...
- Rocket - diplomacy - 模块结构信息
https://mp.weixin.qq.com/s/cTRxXwWNEeb4-XX_t4bRcg 讨论模块结构信息的来源及使用方式. 1. diplomacy diplom ...
- Rocket - decode - Inst Decode
https://mp.weixin.qq.com/s/WvepB3yAzjMbQalO3Z82pQ 介绍RocketChip Instruction解码逻辑的实现. 1. RISC-V R ...
- chrome和Firefox浏览器渲染页面的不同
一直很好奇chrome和firefox这两大浏览器的页面渲染有什么不同,今天自己写了些html代码来做了下检验. 先做html编码,代码如下: <!DOCTYPE html><htm ...
- 【Linux】yum库的配置
链接–>CentOS7之yum仓库配置
- URL与URI的联系与区别
作者:daixinye链接:https://www.zhihu.com/question/21950864/answer/154309494来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商 ...
- Java实现算法提高十进制数转八进制数
算法提高 十进制数转八进制数 时间限制:1.0s 内存限制:512.0MB 编写函数,其功能为把一个十进制数转换为其对应的八进制数.程序读入一个十进制数,调用该函数实现数制转换后,输出对应的八进制数. ...
- Java实现【USACO】1.1.2 贪婪的礼物送礼者 Greedy Gift Givers
[USACO]1.1.2 贪婪的礼物送礼者 Greedy Gift Givers 题目描述 对于一群要互送礼物的朋友,你要确定每个人送出的礼物比收到的多多少(and vice versa for th ...
- Java实现 蓝桥杯VIP 算法训练 入学考试
问题描述 辰辰是个天资聪颖的孩子,他的梦想是成为世界上最伟大的医师.为此,他想拜附近最有威望的医师为师.医师为了判断他的资质,给他出了一个难题.医师把他带到一个到处都是草药的山洞里对他说:" ...
- Java实现第八届蓝桥杯包子凑数
包子凑数 题目描述 小明几乎每天早晨都会在一家包子铺吃早餐.他发现这家包子铺有N种蒸笼,其中第i种蒸笼恰好能放Ai个包子.每种蒸笼都有非常多笼,可以认为是无限笼. 每当有顾客想买X个包子,卖包子的大叔 ...