吴裕雄--天生自然 R语言开发学习:基本统计分析













#---------------------------------------------------------------------#
# R in Action (2nd ed): Chapter 7 #
# Basic statistics #
# requires packages npmc, ggm, gmodels, vcd, Hmisc, #
# pastecs, psych, doBy to be installed #
# install.packages(c("ggm", "gmodels", "vcd", "Hmisc", #
# "pastecs", "psych", "doBy")) #
#---------------------------------------------------------------------# mt <- mtcars[c("mpg", "hp", "wt", "am")]
head(mt) # Listing 7.1 - Descriptive stats via summary
mt <- mtcars[c("mpg", "hp", "wt", "am")]
summary(mt) # Listing 7.2 - descriptive stats via sapply
mystats <- function(x, na.omit=FALSE){
if (na.omit)
x <- x[!is.na(x)]
m <- mean(x)
n <- length(x)
s <- sd(x)
skew <- sum((x-m)^3/s^3)/n
kurt <- sum((x-m)^4/s^4)/n - 3
return(c(n=n, mean=m, stdev=s, skew=skew, kurtosis=kurt))
} myvars <- c("mpg", "hp", "wt")
sapply(mtcars[myvars], mystats) # Listing 7.3 - Descriptive stats via describe (Hmisc)
library(Hmisc)
myvars <- c("mpg", "hp", "wt")
describe(mtcars[myvars]) # Listing 7.,4 - Descriptive stats via stat.desc (pastecs)
library(pastecs)
myvars <- c("mpg", "hp", "wt")
stat.desc(mtcars[myvars]) # Listing 7.5 - Descriptive stats via describe (psych)
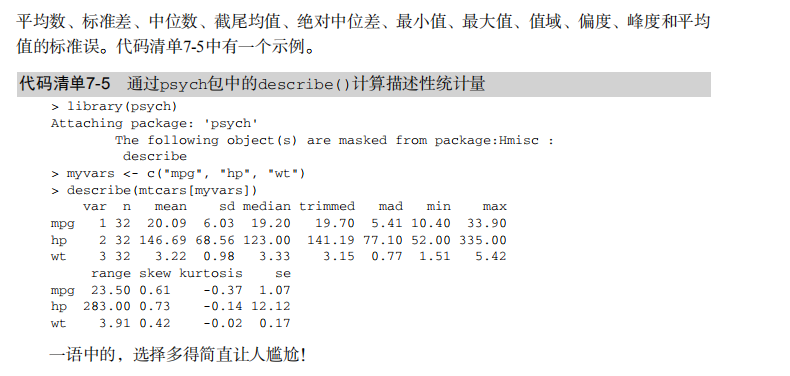
library(psych)
myvars <- c("mpg", "hp", "wt")
describe(mtcars[myvars]) # Listing 7.6 - Descriptive stats by group with aggregate
myvars <- c("mpg", "hp", "wt")
aggregate(mtcars[myvars], by=list(am=mtcars$am), mean)
aggregate(mtcars[myvars], by=list(am=mtcars$am), sd) # Listing 7.7 - Descriptive stats by group via by
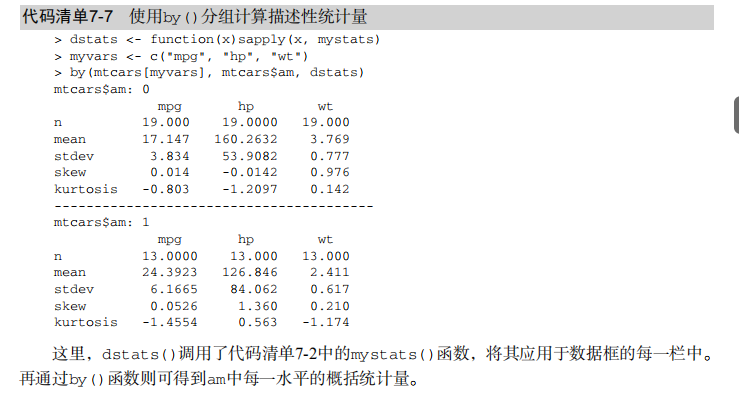
dstats <- function(x)sapply(x, mystats)
myvars <- c("mpg", "hp", "wt")
by(mtcars[myvars], mtcars$am, dstats) # Listing 7.8 - Descriptive stats by group via summaryBy
library(doBy)
summaryBy(mpg+hp+wt~am, data=mtcars, FUN=mystats) # Listing 7.9 - Descriptive stats by group via describe.by (psych)
library(psych)
myvars <- c("mpg", "hp", "wt")
describeBy(mtcars[myvars], list(am=mtcars$am)) # summary statistics by group via the reshape package
library(reshape)
dstats <- function(x)(c(n=length(x), mean=mean(x), sd=sd(x)))
dfm <- melt(mtcars, measure.vars=c("mpg", "hp", "wt"),
id.vars=c("am", "cyl"))
cast(dfm, am + cyl + variable ~ ., dstats) # frequency tables
library(vcd)
head(Arthritis) # one way table
mytable <- with(Arthritis, table(Improved))
mytable # frequencies
prop.table(mytable) # proportions
prop.table(mytable)*100 # percentages # two way table
mytable <- xtabs(~ Treatment+Improved, data=Arthritis)
mytable # frequencies
margin.table(mytable,1) #row sums
margin.table(mytable, 2) # column sums
prop.table(mytable) # cell proportions
prop.table(mytable, 1) # row proportions
prop.table(mytable, 2) # column proportions
addmargins(mytable) # add row and column sums to table # more complex tables
addmargins(prop.table(mytable))
addmargins(prop.table(mytable, 1), 2)
addmargins(prop.table(mytable, 2), 1) # Listing 7.10 - Two way table using CrossTable
library(gmodels)
CrossTable(Arthritis$Treatment, Arthritis$Improved) # Listing 7.11 - Three way table
mytable <- xtabs(~ Treatment+Sex+Improved, data=Arthritis)
mytable
ftable(mytable)
margin.table(mytable, 1)
margin.table(mytable, 2)
margin.table(mytable, 2)
margin.table(mytable, c(1,3))
ftable(prop.table(mytable, c(1,2)))
ftable(addmargins(prop.table(mytable, c(1, 2)), 3)) # Listing 7.12 - Chi-square test of independence
library(vcd)
mytable <- xtabs(~Treatment+Improved, data=Arthritis)
chisq.test(mytable)
mytable <- xtabs(~Improved+Sex, data=Arthritis)
chisq.test(mytable) # Fisher's exact test
mytable <- xtabs(~Treatment+Improved, data=Arthritis)
fisher.test(mytable) # Chochran-Mantel-Haenszel test
mytable <- xtabs(~Treatment+Improved+Sex, data=Arthritis)
mantelhaen.test(mytable) # Listing 7.13 - Measures of association for a two-way table
library(vcd)
mytable <- xtabs(~Treatment+Improved, data=Arthritis)
assocstats(mytable) # Listing 7.14 Covariances and correlations
states<- state.x77[,1:6]
cov(states)
cor(states)
cor(states, method="spearman") x <- states[,c("Population", "Income", "Illiteracy", "HS Grad")]
y <- states[,c("Life Exp", "Murder")]
cor(x,y) # partial correlations
library(ggm)
# partial correlation of population and murder rate, controlling
# for income, illiteracy rate, and HS graduation rate
pcor(c(1,5,2,3,6), cov(states)) # Listing 7.15 - Testing a correlation coefficient for significance
cor.test(states[,3], states[,5]) # Listing 7.16 - Correlation matrix and tests of significance via corr.test
library(psych)
corr.test(states, use="complete") # t test
library(MASS)
t.test(Prob ~ So, data=UScrime) # dependent t test
sapply(UScrime[c("U1","U2")], function(x)(c(mean=mean(x),sd=sd(x))))
with(UScrime, t.test(U1, U2, paired=TRUE)) # Wilcoxon two group comparison
with(UScrime, by(Prob, So, median))
wilcox.test(Prob ~ So, data=UScrime) sapply(UScrime[c("U1", "U2")], median)
with(UScrime, wilcox.test(U1, U2, paired=TRUE)) # Kruskal Wallis test
states <- data.frame(state.region, state.x77)
kruskal.test(Illiteracy ~ state.region, data=states) # Listing 7.17 - Nonparametric multiple comparisons
source("http://www.statmethods.net/RiA/wmc.txt")
states <- data.frame(state.region, state.x77)
wmc(Illiteracy ~ state.region, data=states, method="holm")
吴裕雄--天生自然 R语言开发学习:基本统计分析的更多相关文章
- 吴裕雄--天生自然 R语言开发学习:R语言的安装与配置
下载R语言和开发工具RStudio安装包 先安装R
- 吴裕雄--天生自然 R语言开发学习:数据集和数据结构
数据集的概念 数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量.表2-1提供了一个假想的病例数据集. 不同的行业对于数据集的行和列叫法不同.统计学家称它们为观测(observation)和 ...
- 吴裕雄--天生自然 R语言开发学习:导入数据
2.3.6 导入 SPSS 数据 IBM SPSS数据集可以通过foreign包中的函数read.spss()导入到R中,也可以使用Hmisc 包中的spss.get()函数.函数spss.get() ...
- 吴裕雄--天生自然 R语言开发学习:使用键盘、带分隔符的文本文件输入数据
R可从键盘.文本文件.Microsoft Excel和Access.流行的统计软件.特殊格 式的文件.多种关系型数据库管理系统.专业数据库.网站和在线服务中导入数据. 使用键盘了.有两种常见的方式:用 ...
- 吴裕雄--天生自然 R语言开发学习:R语言的简单介绍和使用
假设我们正在研究生理发育问 题,并收集了10名婴儿在出生后一年内的月龄和体重数据(见表1-).我们感兴趣的是体重的分 布及体重和月龄的关系. 可以使用函数c()以向量的形式输入月龄和体重数据,此函 数 ...
- 吴裕雄--天生自然 R语言开发学习:基础知识
1.基础数据结构 1.1 向量 # 创建向量a a <- c(1,2,3) print(a) 1.2 矩阵 #创建矩阵 mymat <- matrix(c(1:10), nrow=2, n ...
- 吴裕雄--天生自然 R语言开发学习:图形初阶(续二)
# ----------------------------------------------------# # R in Action (2nd ed): Chapter 3 # # Gettin ...
- 吴裕雄--天生自然 R语言开发学习:图形初阶(续一)
# ----------------------------------------------------# # R in Action (2nd ed): Chapter 3 # # Gettin ...
- 吴裕雄--天生自然 R语言开发学习:图形初阶
# ----------------------------------------------------# # R in Action (2nd ed): Chapter 3 # # Gettin ...
- 吴裕雄--天生自然 R语言开发学习:基本图形(续二)
#---------------------------------------------------------------# # R in Action (2nd ed): Chapter 6 ...
随机推荐
- 吴裕雄--天生自然ShellX学习笔记:Shell 流程控制
和Java.PHP等语言不一样,sh的流程控制不可为空,如(以下为PHP流程控制写法): <?php if (isset($_GET["q"])) { search(q); ...
- c# 之Enum--枚举
枚举 收藏的博文连接 枚举类型声明为一组相关的符号常数定义了一个类型名称.枚举用于“多项选择”场合,就是程序运行时从编译时已经设定的固定数目的“选择”中做出决定. 枚举类型(也称为枚举):该类型可以 ...
- Jenkin远程部署Tomcat8.5总结
tomcat8.5相比之前的tomcat进入manger管理界面需要多一些设置 1. 在 $tomcathome/conf/Catalina/localhost/下创建 manager.xml , 填 ...
- PAT Advanced 1089 Insert or Merge (25) [two pointers]
题目 According to Wikipedia: Insertion sort iterates, consuming one input element each repetition, and ...
- ZJNU 1205 - 侦探推理——高级
双层枚举嫌疑犯与当日是星期几,统计真话与假话是否满足题意 注意 fake<=N&&fake+neutral>=N 即假话数量不大于N,假话加上没用的废话数量不小于N (注意 ...
- Django的View(视图层)
目录 Django的View(视图层) 一.JsonResponse 二.后端接收前端的文件 三. FBV和CBV(源码分析) 四.settings.py配置文件源码分析 五. 请求对象(HttpRe ...
- 在Eclipse下远程调试Beagleboneblack
安装调试器 1. gdbserver 2. gdb-multiarch 建立工程 新建一个cpp工程,ToolChains选择Cross GCC 这里使用的是arm-linux-gnueabihf-的 ...
- python 3.6
安装了最新版anaconda3-4.3 发现jupyter-notebook 少了一些东西.需要手工安装 https://github.com/Anaconda-Platform/nbpresent
- Codeforces 1295D Same GCDs
题目链接 link Solution 这是一道结论题,有两个做法,分别用了欧拉函数或一点点莫比乌斯反演 (这里只放欧拉函数的做法) 设\(d=gcd(m,a)\) \[gcd(\frac{a}{d}, ...
- mysql_secure_installation 安全安装(用于生产环境设置)
编译安装完mysql5.6,如果用于生产环境,最好执行mysql_secure_installation来做一些常规化安全设置. 需要提前将~mysql/bin加入环境变量 /apps/mysql// ...