nodejs eggjs框架 爬虫 readhub.me
最近做了一款 高仿ReadHub小程序 微信小程序 canvas 自动适配 自动换行,保存图片分享到朋友圈 https://gitee.com/richard1015/News
具体代码已被开源,后续我会继续更新,欢迎指正
https://github.com/richard1015/egg-example
https://gitee.com/richard1015/egg-example
你可能会像我一样,平常对科技圈发生的热点新闻很感兴趣。每天利用刚打开电脑的时候,又或者是工作间隙,浏览几个更新及时的科技资讯网站。但是,科技圈每天发生的热点新闻就那么几件。看来看去,新闻的重复度高,硬广软文还看了不少。不仅浪费时间,还抓不住重点。
ReadHub 通过爬虫各种科技新闻 大数据过滤筛选 (个人猜想,大概是这一个意思),所以自己写个爬虫把数据爬到自己mysql数据库中
代码思路:
通过网上各种调用 动态网站数据 爬虫分为两种解决方案
1.模拟浏览器请求 使用 相应框架 比如:Selenium、PhantomJs。
2.精准分析页面,找到对应请求接口,直接获取api数据。
- 优点:性能高,使用方便。我们直接获取原数据接口(换句话说就是直接拿取网页这一块动态数据的API接口),肯定会使用方便,并且改变的可能性也比较小。
- 缺点:缺点也是明显的,如何获取接口API?有些网站可能会考虑到数据的安全性,做各种限制、混淆等。这就需要看开发者个人的基本功了,进行各种分析了。
- 我个人在爬取ReadHub时,发现《热门话题》 列表是 无混淆,所以找到请求规律,爬取成功 ,剩下 开发者资讯、科技动态、区块链快讯、招聘行情 请求index被混淆,所以暂无成功。
我在本次采用第二种解决方案 chrome浏览器分析
1.使用chrome 调试工具 Mac 按 alt + cmd+ i Windows 按 F12 或者 右键检查 或 审查元素 找到Network 选中 xhr模块

可通过图片中看到 每次滚动加载数据时 都会有api请求数据, 我们发现 下次触发滚动加载时,的lastCursor的值 为 上次请求的 数组中最后一个对象中的order值
所以我们发现 只是的请求 url地址为 https://api.readhub.me/topic?lastCursor=53058&pageSize=20 中 的lastCursor 动态设置,即可完成抓取数据
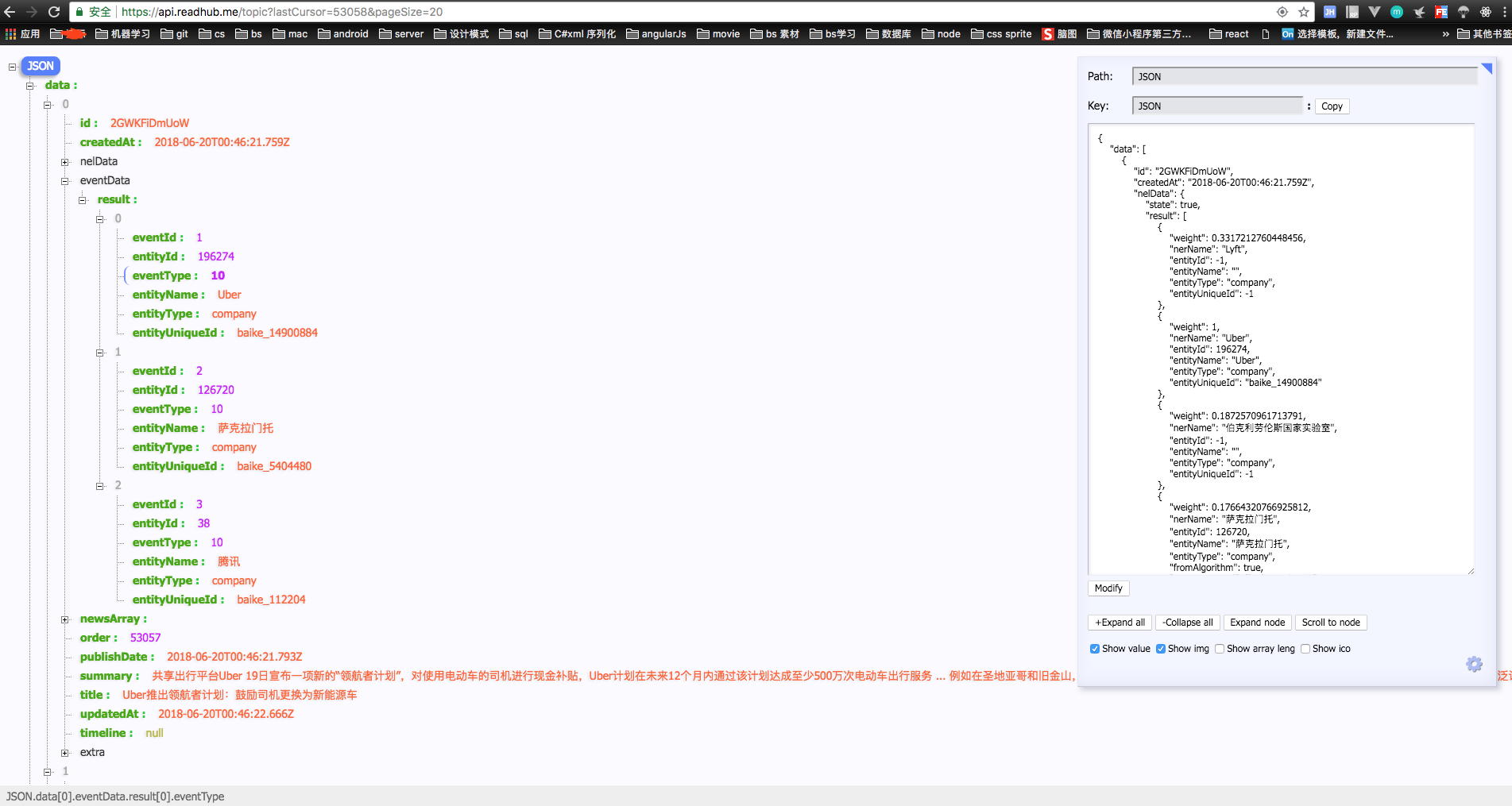
那么接下来 我们需要 建立mysql数据库
CREATE DATABASE `news` /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_bin */;
CREATE TABLE `news` (
`id` varchar(11) COLLATE utf8_bin NOT NULL,
`order` double NOT NULL,
`title` varchar(200) COLLATE utf8_bin NOT NULL,
`jsonstr` json DEFAULT NULL,
`createdAt` varchar(255) COLLATE utf8_bin DEFAULT NULL,
`updatedAt` varchar(255) COLLATE utf8_bin DEFAULT NULL,
`insertTime` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
然后就是编写 nodejs 中代码逻辑 我在下面的抓取冲采用 eggjs 框架中的 egg-mysql 进行连接数据库 https://eggjs.org/zh-cn/tutorials/mysql.html#egg-mysql
使用定时任务来 执行爬取数据
1.news.service 中代码实现
// app/service/news.js
const Service = require('egg').Service; class NewsService extends Service {
async list(pageIndex = '', pageSize = '20') {
try {
// read config
const { serverUrl } = this.config.readhub;
// 热门话题
const topic = `${serverUrl}topic?lastCursor=${pageIndex}&pageSize=${pageSize}`;
// use build-in http client to GET hacker-news api
const result = await this.ctx.curl(topic,
{
dataType: 'json',
}
);
if (result.status === 200) {
return result.data;
}
return [];
} catch (error) {
this.logger.error(error);
return [];
}
}
async saveDB(list) {
try {
const newsClient = this.app.mysql.get("news");
list.data.forEach(item => {
// 插入
newsClient.insert('news', {
id: item.id,
order: item.order,
title: item.title,
jsonstr: JSON.stringify(item),
createdAt: new Date(item.createdAt).getTime(),
updatedAt: new Date(item.updatedAt).getTime(),
}).then(result => {
// 判断更新成功
const updateSuccess = result.affectedRows === 1;
this.logger.info(item.id + " > " + updateSuccess);
}).catch(error => {
//入库失败错误机制触发
this.app.cache.errorNum += 1;
})
});
} catch (error) {
this.logger.error(error);
}
}
} module.exports = NewsService;
2.定时任务代码实现
update_cache.js
const Subscription = require('egg').Subscription;
class UpdateCache extends Subscription {
// 通过 schedule 属性来设置定时任务的执行间隔等配置
static get schedule() {
return {
interval: '5s', // 隔单位 m 分 、 s 秒、 ms 毫秒
type: 'all', // 指定所有的 worker 都需要执行
immediate: true, //配置了该参数为 true 时,这个定时任务会在应用启动并 ready 后立刻执行一次这个定时任务。
disable: false//配置该参数为 true 时,这个定时任务不会被启动。
};
}
// subscribe 是真正定时任务执行时被运行的函数
async subscribe() {
let ctx = this.ctx;
ctx.logger.info('update cache errorNum = ' + ctx.app.cache.errorNum);
// errorNum 当错误数量 > 50时 停止抓取数据
if (ctx.app.cache.errorNum > 50) {
ctx.logger.info('errorNum > 50 stop ');
return;
}
ctx.logger.info('update cache begin ! currentLastCursor = ' + ctx.app.cache.lastCursor);
const pageIndex = ctx.app.cache.lastCursor || '';
const pageSize = '20';
const newsList = await ctx.service.news.list(pageIndex == 1 ? '' : pageIndex, pageSize);
if (newsList.data.length == 0) {
//没有数据时错误机制触发
this.app.cache.errorNum += 1;
ctx.logger.info('no data stop ! currentLastCursor = ' + ctx.app.cache.lastCursor);
} else {
ctx.service.news.saveDB(newsList)
ctx.app.cache.lastCursor = newsList.data[newsList.data.length - 1].order;
ctx.logger.info('update cache end ! currentLastCursor set = ' + ctx.app.cache.lastCursor);
}
}
}
module.exports = UpdateCache;
update_cache_init.js
const Subscription = require('egg').Subscription;
class UpdateCacheInit extends Subscription {
// 通过 schedule 属性来设置定时任务的执行间隔等配置
static get schedule() {
return {
interval: 60 * 24 + 'm', // 隔单位 m 分 、 s 秒、 ms 毫秒
type: 'all', // 指定所有的 worker 都需要执行
immediate: true, //配置了该参数为 true 时,这个定时任务会在应用启动并 ready 后立刻执行一次这个定时任务。
disable: false//配置该参数为 true 时,这个定时任务不会被启动。
};
}
// subscribe 是真正定时任务执行时被运行的函数
async subscribe() {
let ctx = this.ctx;
ctx.logger.info('update cache init');
if (ctx.app.cache.errorNum > 50) {
//初始化内置缓存
ctx.app.cache = {
lastCursor: '',
errorNum: 0 //错误数量
};
}
}
}
module.exports = UpdateCacheInit;
项目运行图

具体代码已被开源,后续我会继续更新,欢迎指正
https://github.com/richard1015/egg-example
https://gitee.com/richard1015/egg-example
nodejs eggjs框架 爬虫 readhub.me的更多相关文章
- 一次使用NodeJS实现网页爬虫记
前言 几个月之前,有同事找我要PHP CI框架写的OA系统.他跟我说,他需要学习PHP CI框架,我建议他学习大牛写的国产优秀框架QeePHP. 我上QeePHP官网,发现官方网站打不开了,GOOGL ...
- (转)windows下安装nodejs及框架express
转自:http://jingyan.baidu.com/article/456c463b60fb380a583144a9.html windows下安装nodejs及框架express nodejs从 ...
- nodejs的简单爬虫
闲聊 好久没写博客了,前几天小颖在朋友的博客里看到了用nodejs的简单爬虫.所以小颖就自己试着做了个爬博客园数据的demo.嘻嘻...... 小颖最近养了条泰日天,自从养了我家 ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录 模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于star ...
- 第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用
第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用 xpath表达式 //x 表示向下查找n层指定标签,如://div 表示查找所有div标签 /x 表示向下查找一层指定的标签 ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
随机推荐
- jquery()后续版本中,live()取消后使用on()实现功能写法
今天做项目想用live()功能,写完打开浏览器发现报错 然后查了查发现自己用的是jquery是jquery-2.1.1.min.js,而jquery早就取消了live()方法,在后续版本里都已经没有使 ...
- AGC004F Namori 树形DP、解方程(?)
传送门 因为不会列方程然后只会树上的,被吊打了QAQ 不难想到从叶子节点往上计算答案.可以考虑到可能树上存在一个点,在它的儿子做完之后接着若干颜色为白色的儿子,而当前点为白色,只能帮助一个儿子变成黑色 ...
- UI 前端参考
:http://amazeui.org/ :http://www.dcloud.io/index.html :https://weui.io/ :http://m.sui.taobao.org/get ...
- 支持异步同步的分布式CommandBus MSMQ实现 - 支持Session传递、多实例处理
先上一张本文所描述的适用场景图 分布式场景,共3台server: 前端Server Order App Server Warehouse App Server 功能: 前端Server可以不停的发送C ...
- ML.NET 示例:回归之销售预测
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
- 在Linux的Windows子系统上(WSL)使用Docker(Ubuntu)
背景 平时开发大部人都是在提供了高效GUI的window下工作,但是真正部署环境普遍都是在Linux中,所以为了让开发环境和部署环境统一,我们需要在windows模拟LInux环境,以前我们可能通过虚 ...
- 剑指Offer-- 二叉搜索树中和为某一值的路径
输入一颗二叉树和一个整数,打印出二叉树中结点值的和为输入整数的所有路径.路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径. 本身题目不是很难,但是因为刚接触pyhon,对一些对象的传 ...
- 3proxy.cfg 配置文件解析
最新配置文件的man文档所在位置: /程序目录/doc/html/man3/3proxy.cfg.3.html 官网: https://3proxy.ru/ Download 3proxy tiny ...
- PHP中对象的深拷贝与浅拷贝
先说一下深拷贝和浅拷贝通俗理解 深拷贝:赋值时值完全复制,完全的copy,对其中一个作出改变,不会影响另一个 浅拷贝:赋值时,引用赋值,相当于取了一个别名.对其中一个修改,会影响另一个 PHP中, = ...
- CIFS 与 SMB 有什么区别?
CIFS 与 SMB 有什么区别? https://www.getnas.com/2018/11/30/cifs-vs-smb/ 网络协议 一知半解 学习一下挺好的.. 记得 win2019 已经废弃 ...