c/c++连通图的遍历(深度遍历/广度遍历)
连通图的遍历(深度遍历/广度遍历)
概念:图中的所有节点都要遍历到,并且只能遍历一次。
- 深度遍历
- 广度遍历
深度遍历
概念:从一个给定的顶点开始,找到一条边,沿着这条边一直遍历。
广度遍历
概念:从一个给定的顶点开始,找到这个顶点下的所有子顶点后,再找下一层的子顶点。
深度遍历的实现思路
1,创建一个bool数组,用来识别哪个顶点已经被遍历过了。
2,递归
3,递归找给定顶点是否有下一个顶点(方法:get_first_neighbor),都找完后,
4,再递归找给定顶点之后的在3处找到的顶点后的下一个顶点(方法:get_next_neighbor)
光度遍历的实现思路
1,用队列实现,先入队给定顶点
2,出队
3,入队:与在2处出队的顶点有相连的顶点
代码
graph_link.h
#ifndef __graph_link__
#define __graph_link__
#include <stdio.h>
#include <malloc.h>
#include <assert.h>
#include <memory.h>
#include <stdbool.h>
#define default_vertex_size 10
#define T char
//边的结构
typedef struct Edge{
//顶点的下标
int idx;
//指向下一个边的指针
struct Edge* link;
}Edge;
//顶点的结构
typedef struct Vertex{
//顶点的值
T data;
//边
Edge* adj;
}Vertex;
//图的结构
typedef struct GraphLink{
int MaxVertices;
int NumVertices;
int NumEdges;
Vertex* nodeTable;
}GraphLink;
//初始化图
void init_graph_link(GraphLink* g);
//显示图
void show_graph_link(GraphLink* g);
//插入顶点
void insert_vertex(GraphLink* g, T v);
//插入边尾插
void insert_edge_tail(GraphLink* g, T v1, T v2);
//插入边头插
void insert_edge_head(GraphLink* g, T v1, T v2);
//删除边
void remove_edge(GraphLink* g, T v1, T v2);
//删除顶点
void remove_vertex(GraphLink* g, T v);
//销毁图
void destroy_graph_link(GraphLink* g);
//取得指定顶点的第一个后序顶点
int get_first_neighbor(GraphLink* g, T v);
//取得指定顶点v1的临街顶点v2的第一个后序顶点
int get_next_neighbor(GraphLink* g, T v1, T v2);
//深度遍历
void dfs_graph(GraphLink* g, T v);
//取得顶点的data值
T getVertexValue(GraphLink* g, int i);
//广度遍历
void cfs_graph(GraphLink* g, T v);
#endif
graph_link.c
#include "graph_link.h"
#include "nodequeue.h"
//初始化图
void init_graph_link(GraphLink* g){
g->MaxVertices = default_vertex_size;
g->NumVertices = g->NumEdges = 0;
g->nodeTable = (Vertex*)malloc(sizeof(Vertex) * g->MaxVertices);
assert(NULL != g->nodeTable);
for(int i = 0; i < g->MaxVertices; ++i){
g->nodeTable[i].adj = NULL;
}
}
//显示图
void show_graph_link(GraphLink* g){
if(NULL == g)return;
for(int i = 0; i < g->NumVertices; ++i){
printf("%d %c->", i, g->nodeTable[i].data);
Edge* p = g->nodeTable[i].adj;
while(NULL != p){
printf("%d->", p->idx);
p = p->link;
}
printf(" NULL\n");
}
}
//插入顶点
void insert_vertex(GraphLink* g, T v){
if(g->NumVertices >= g->MaxVertices)return;
g->nodeTable[g->NumVertices++].data = v;
}
//查找顶点的index
int getVertexIndex(GraphLink* g, T v){
for(int i = 0; i < g->NumVertices; ++i){
if(v == g->nodeTable[i].data)return i;
}
return -1;
}
//插入边(头插)
void insert_edge_head(GraphLink* g, T v1, T v2){
int p1 = getVertexIndex(g, v1);
int p2 = getVertexIndex(g, v2);
if(p1 == -1 || p2 == -1)return;
Edge* p = (Edge*)malloc(sizeof(Edge));
p->idx = p2;
p->link = g->nodeTable[p1].adj;
g->nodeTable[p1].adj = p;
p = (Edge*)malloc(sizeof(Edge));
p->idx = p1;
p->link = g->nodeTable[p2].adj;
g->nodeTable[p2].adj = p;
}
//取得指定顶点的第一个后序顶点
int get_first_neighbor(GraphLink* g, T v){
int i = getVertexIndex(g, v);
if (-1 == i)return -1;
Edge* p = g->nodeTable[i].adj;
if(NULL != p)
return p->idx;
else
return -1;
}
//取得指定顶点v1的临街顶点v2的第一个后序顶点
int get_next_neighbor(GraphLink* g, T ve1, T ve2){
int v1 = getVertexIndex(g, ve1);
int v2 = getVertexIndex(g, ve2);
if(v1 == -1 || v2 == -1)return -1;
Edge* t = g->nodeTable[v1].adj;
while(t != NULL && t->idx != v2){
t = t->link;
}
if(NULL != t && t->link != NULL){
return t->link->idx;
}
return -1;
}
//取得顶点的data值
T getVertexValue(GraphLink* g, int i){
if(i == -1)return 0;
return g->nodeTable[i].data;
}
//深度遍历
void dfs_graph_v(GraphLink* g, int v, bool* visited){
printf("%c->", getVertexValue(g,v));
visited[v] = true;
//取得相邻顶点的下标
int w = get_first_neighbor(g, getVertexValue(g, v));
while(w != -1){
if(!visited[w]){
dfs_graph_v(g, w, visited);
}
w = get_next_neighbor(g, getVertexValue(g, v), getVertexValue(g,w));
}
}
void dfs_graph(GraphLink* g, T v){
int cnt = g->NumVertices;
bool* visited = (bool*)malloc(sizeof(bool) * cnt);
assert(NULL != visited);
for(int i = 0; i < cnt; ++i){
visited[i] = false;
}
int index = getVertexIndex(g, v);
dfs_graph_v(g, index, visited);
free(visited);
}
//广度遍历
void cfs_graph(GraphLink* g, T v){
//创建一个辅助的bool数组,用来识别哪个顶点已经被遍历过了
int cnt = g->NumVertices;
bool* visited = (bool*)malloc(sizeof(bool) * cnt);
assert(NULL != visited);
for(int i = 0; i < cnt; ++i){
visited[i] = false;
}
//创建队列
NodeQueue q;
init(&q);
//入队
int tar = getVertexIndex(g, v);
enQueue(&q, tar);
//队列不为空就执行
while(length(&q) != 0){
//取得队列的第一个元素
int ve = getHead(&q)->data;
printf("%c->", getVertexValue(g, ve));
visited[ve] = true;
//出队
deQueue(&q);
Edge* e = g->nodeTable[ve].adj;
while(NULL != e){
//如果这个顶点没有被遍历过,入队
if(!visited[e->idx]){
visited[e->idx] = true;
enQueue(&q, e->idx);
}
e = e->link;
}
}
}
graph_linkmain.c
#include "graph_link.h"
int main(){
GraphLink gl;
//初始化图
init_graph_link(&gl);
//插入节点
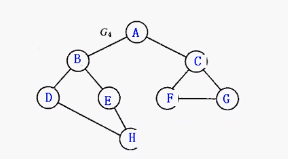
insert_vertex(&gl, 'A');
insert_vertex(&gl, 'B');
insert_vertex(&gl, 'C');
insert_vertex(&gl, 'D');
insert_vertex(&gl, 'E');
insert_vertex(&gl, 'F');
insert_vertex(&gl, 'G');
insert_vertex(&gl, 'H');
insert_edge_head(&gl, 'A', 'B');
insert_edge_head(&gl, 'A', 'C');
insert_edge_head(&gl, 'B', 'D');
insert_edge_head(&gl, 'B', 'E');
insert_edge_head(&gl, 'C', 'F');
insert_edge_head(&gl, 'C', 'G');
insert_edge_head(&gl, 'D', 'H');
insert_edge_head(&gl, 'E', 'H');
insert_edge_head(&gl, 'F', 'G');
//显示图
show_graph_link(&gl);
//深度遍历
dfs_graph(&gl, 'E');
printf("null\n");
//广度遍历
cfs_graph(&gl, 'F');
printf("null\n");
}
完整代码
编译方法:g++ -g nodequeue.c graph_link.c graph_linkmain.c
c/c++连通图的遍历(深度遍历/广度遍历)的更多相关文章
- Java多线程遍历文件夹,广度遍历加多线程加深度遍历结合
复习IO操作,突然想写一个小工具,统计一下电脑里面的Java代码量还有注释率,最开始随手写了一个递归算法,遍历文件夹,比较简单,而且代码层次清晰,相对易于理解,代码如下:(完整代码贴在最后面,前面是功 ...
- 图的存储及遍历 深度遍历和广度遍历 C++代码实现
/*图的存储及遍历*/ #include<iostream> using namespace std; //----------------------------------- //邻接 ...
- 记录JS如何使用广度遍历找到节点的所有父节点
我们在实际的工作业务场景中经常遇到这样的场景,求取树数据中某个节点的父亲节点以及所有的父亲节点,这样的场景下不建议使用深度遍历,使用广度遍历可以更快找到. 1.案例解说 比如树的长相是这样的: 树的数 ...
- java遍历树(深度遍历和广度遍历
java遍历树如现有以下一颗树:A B B1 B11 B2 B22 C C ...
- 多级树的深度遍历与广度遍历(Java实现)
目录 多级树的深度遍历与广度遍历 节点模型 深度优先遍历 广度优先遍历 多级树的深度遍历与广度遍历 深度优先遍历与广度优先遍历其实是属于图算法的一种,多级树可以看做是一种特殊的图,所以多级数的深/广遍 ...
- 重新整理数据结构与算法(c#)—— 图的深度遍历和广度遍历[十一]
参考网址:https://www.cnblogs.com/aoximin/p/13162635.html 前言 简介图: 在数据的逻辑结构D=(KR)中,如果K中结点对于关系R的前趋和后继的个数不加限 ...
- 采用邻接矩阵表示图的深度优先搜索遍历(与深度优先搜索遍历连通图的递归算法仅仅是DFS的遍历方式变了)
//采用邻接矩阵表示图的深度优先搜索遍历(与深度优先搜索遍历连通图的递归算法仅仅是DFS的遍历方式变了) #include <iostream> using namespace std; ...
- 【算法】【python实现】二叉树深度、广度优先遍历
二叉树的遍历,分为深度优先遍历,以及广度优先遍历. 在深度优先遍历中,具体分为如下三种: 先序遍历:先访问根节点,再遍历左子树,再遍历右子树: 中序遍历:先遍历左子树,再访问根节点,再遍历右子树: 后 ...
- C++编程练习(8)----“二叉树的建立以及二叉树的三种遍历方式“(前序遍历、中序遍历、后续遍历)
树 利用顺序存储和链式存储的特点,可以实现树的存储结构的表示,具体表示法有很多种. 1)双亲表示法:在每个结点中,附设一个指示器指示其双亲结点在数组中的位置. 2)孩子表示法:把每个结点的孩子排列起来 ...
随机推荐
- 简单说明CGI和动态请求是什么
1. CGI是什么 CGI是common gateway interface的缩写,大家都译作通用网关接口,但很不幸,我们无法见名知意. 我们知道,web服务器所处理的内容都是静态的,要想处理动态内容 ...
- 翻译:非递归CTE(已提交到MariaDB官方手册)
本文为mariadb官方手册:非递归CTE的译文. 原文:https://mariadb.com/kb/en/library/non-recursive-common-table-expression ...
- Ubuntu使用(一)——常用命令与软件安装配置
1.安装输入法 2.配置JDK 3.eclipse 3.1 eclipse启动错误 修改eclipse.init的配置,主要加-vm以及下面的jre路径,路径前别留空格 之前因为加了空格,一直找不到原 ...
- H5调取APP或跳转至下载
来源: 最近在配合移动端做几个详情页h5分享页面,需要调取App并跳转至app详情页, 如果没有安装App,需要判断引导至下载页面. 参考文档: https://juejin.im/post/5b7e ...
- 跨域学习笔记3--web.config设置之system.webServer 详细介绍,为网站设置默认文档
自己并不懂,在此先记录下来,留待以后学习... 如何:为 IIS 7.0 配置 <system.webServer> 节2008-06-14 22:26http://technet.mic ...
- 第一册:lesson seventy one.
原文: He is awful. A:What's Ron Marston like , Pauline? B:He is awful.He telephoned me four times yest ...
- 行为型---中介者模式(Mediator Pattern)
中介者模式的定义 中介者模式,定义了一个中介对象来封装一系列对象之间的交互关系.中介者使各个对象之间不需要显式地相互引用,从而使耦合性降低,而且可以独立地改变它们之间的交互行为. 中介者模式的结构 ...
- Jquery里的特定小技巧
jQuery 动态设置样式: https://blog.csdn.net/xiaoyuncc/article/details/70854925 jquery如 ...
- tomcat开启自启动
linux方式 #!/bin/bash #chkconfig: #description: Starts and Stops the Tomcat daemon. #by benjamin ##### ...
- Python_简单三级菜单制作
一:制作要求 1.三级菜单 2.可依次选择进入各子菜单 3.所需新知识点:字典,列表 *本文通过三种方法完成,第一种:只使用循环,第二种:使用列表,第三种:使用字典 二:FlowChart流程图 与上 ...