迁移学习《Efficient and Robust Pseudo-Labeling for Unsupervised Domain Adaptation》
论文信息
论文标题:Efficient and Robust Pseudo-Labeling for Unsupervised Domain Adaptation
论文作者:Hochang Rhee、Nam Ik Cho
论文来源:2019——ICML
论文地址:download
论文代码:download
视屏讲解:click
1 摘要
问题:无监督域适应传统方法将超过一定置信度阈值的数据视为目标域的伪标记数据,因此选择合适的阈值会影响目标性能。
在本文中,提出了一种新的基于置信度的加权方案来获得伪标签,并提出了一种自适应阈值调整策略,以在整个训练过程中提供足够和准确的伪标签。 准确地说,基于置信度的加权方案根据置信度生成伪标签具有不同的贡献,这使得性能对阈值不太敏感。 此外,所提出的自适应阈值调整方法根据网络对目标域的适应程度来选择阈值,从而避免了对适当阈值的穷举搜索的需要。
2 介绍
背景
伪标记[21] 是对未标记数据进行人工标记,将无监督学习转化为半监督学习的过程。 本文遵循的前提,即具有高置信度输出的样本可以用作准确的标签 [22]、[23]。 具体来说,置信度超过某个阈值的未标记样本被视为真实标签,称之为伪标签。 伪标记技术的性能在很大程度上依赖于阈值,其中选择合适的阈值对于实现高性能至关重要。 高阈值会导致更准确的伪标签,从而获得高性能,但也会导致标签不足。 另一方面,低阈值会导致大量伪标签,但也会因伪标签不准确而导致性能不佳。 因此,找到合适的阈值以实现高性能是伪标记中的一个主要问题。
此外,传统方法不是在整个训练过程中固定阈值,而是随着训练的进行不断增加阈值 [18]-[20]。 随着训练的进行,网络会适应目标域,这意味着与训练的早期阶段相比,将生成更多具有高置信度的伪标签。 当训练进行到一定程度时,即使阈值很高,网络也能够提供足够的伪标签。 因此,网络专注于通过在整个训练过程中增加阈值来生成准确的伪标签。然而,上述关于阈值选择的方法具有局限性。
首先,性能对阈值极其敏感,阈值的微小差异会产生巨大的负面影响。 进行详尽搜索以找到正确的阈值,这很耗时并且需要针对不同的数据集单独完成。其次,先前的工作根据源域训练的进度或网络的准确性调整阈值。尽管伪标签是从目标域样本生成的,但阈值对目标域没有依赖性。
为了克服传统方法的上述局限性,我们提出了一种基于置信度的加权方案来构建伪标签和一种自适应阈值调整方法。 我们基于置信度的加权方案限制了高阈值和低阈值的缺点。 我们为具有高置信度的伪标签赋予高权重,为低置信度赋予低权重。 因此,性能对阈值变得不那么敏感,从而避免了对适当阈值进行详尽搜索的需要。 此外,所提出的自适应阈值调整方法根据网络对目标域的适应程度来选择阈值。 阈值变得依赖于目标域,奖励目标域以在整个训练过程中生成足够和准确的伪标签。 通过所提出的方法,网络能够以自适应方式调整阈值,而无需穷举搜索。
3 方法
整体框架:
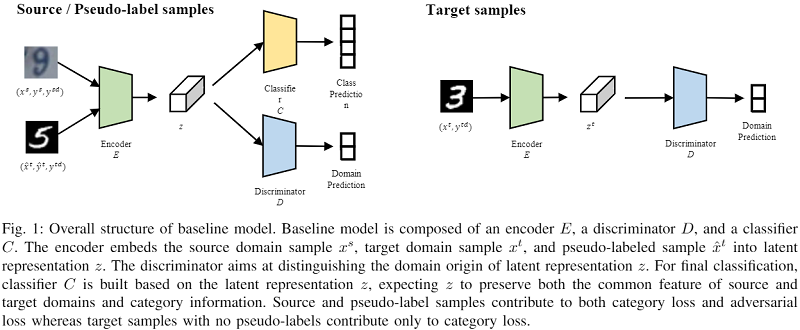
判别器的目标函数:
$\begin{array}{l}L_{D}= \underset{W^{D}}{\text{min}}\left(\sum_{x^{s} \in X_{s}} H\left(D\left(z^{s}\right), y^{s d}\right)\right.\left.+\sum_{x^{t} \in X_{t}} H\left(D\left(z^{t}\right), y^{t d}\right)\right) \\\end{array} \quad\quad(1)$
其中,$y^{sd}$ 和 $y^{td}$ 是二分类域标签;
编码器的目标函数:
$L_{G}=\min _{W^{E}}\left(\sum_{x^{t} \in X_{t}} H\left(D\left(z^{t}\right), y^{s d}\right)\right) \quad\quad(2)$
编码器 $\text{E}$ 和分类器 $\text{C}$ 的目标函数:
$\begin{array}{c}L_{C}=\underset{W^{E}, W^{C}}{\text{min}} \left(\sum_{x^{s} \in X^{s}} H\left(C\left(z^{s}\right), y^{s}\right)\right.\left.+\sum_{\hat{x}^{t} \in \hat{X}_{t}} H\left(C\left(\hat{z}^{t}\right), \hat{y}^{t}\right)\right)\end{array}\quad\quad(3)$
4.1 基于置信度的加权方案
当通过类别损失训练分类器时,先前的工作 [18]-[20] 对每个伪标记样本的类别损失给出了相同的贡献,即使样本的置信度不同。 在高度置信度伪标签大多正确的前提下[22],[23],具有不同置信度的伪标签对类别损失的贡献应该不同。 具有高置信度的伪标签意味着匹配真实标签的概率很高,这应该对类别损失有很大贡献。 相反,低置信度的伪标签有被错误标记的风险,这意味着应该对类别损失给予低贡献以抑制风险。 因此,我们建议赋予伪标签与其置信度成正比的权重。
本文将完全置信的伪标签(置信度为 1.0 的标签)设置为 1.0 的权重,而根据经验将置信度为阈值的伪标签设置为与完全置信的伪标签相比具有一半的贡献。 也就是说,为伪标签分配权重为 0.5 的阈值置信度。 本文将伪标签的权重设置为与伪标签的置信度成线性比例:
$w\left(x^{t}\right)=\frac{0.5}{1-t h} \operatorname{con} f\left(x^{t}\right)+\frac{0.5-t h}{1-t h}\quad\quad(4)$
其中 $\operatorname{con} f\left(x^{t}\right)$ 表示从分类器导出的目标样本 $x_t$ 的置信度,$th$ 表示阈值。
考虑到伪标签的置信度,我们可以通过应用 $\text{Eq.4}$ 来修改等式 $\text{Eq.3}$ 以重新制定新的类别损失:
$\begin{aligned}L_{C}= \min _{W^{E}, W^{C}}\left(\sum_{x^{s} \in X^{s}} H\left(C\left(z^{s}\right), y^{s}\right)\right. \left.+\sum_{\hat{x}^{t} \in \hat{X}_{t}} w\left(\hat{x}^{t}\right) H\left(C\left(\hat{z}^{t}\right), \hat{y}^{t}\right)\right)\end{aligned} \quad\quad(5)$
通过伪标签的基于置信度的加权方案,我们能够减少低阈值和高阈值的缺点。 由低阈值生成的不准确的伪标签被赋予较小的权重,因此分类器受到的不准确性影响较小。 高阈值经历了伪标签的不足,由低阈值提供的伪标签补偿。 结果,网络的性能不会因伪标签的不准确和不足而显着下降,这意味着性能对阈值变得不那么敏感。
4.2 自适应阈值调整
为了关注训练早期伪标签的缺乏和后期伪标签的准确性,许多研究根据训练的进展增加阈值[19],[20]。 训练的进度由当前纪元或网络在源域样本上的准确性决定。 然而,这些术语不依赖于目标域,因此不能完全反映训练的进度。 因此,我们提出自适应阈值调整策略,根据模型对目标域的适应程度来设置阈值。 对目标域适应性低的模型不能对目标样本进行分类,这会导致输出置信度低,而适应性好的模型则输出置信度高。 因此,我们将模型对目标域的适应程度视为目标样本的平均置信度输出。 基于模型对目标域的置信度的修改阈值表示为:
$t h=\max \left(\frac{\sum_{x^{t} \in X_{t}} \operatorname{con} f\left(x^{t}\right)}{n_{t}}, \alpha\right) \quad\quad(6)$
其中 $n_t$ 表示目标样本的数量,$\alpha = 0.7$ 表示最小阈值。 确定一个最小阈值,以防止在训练初期模型对目标域没有适应性时阈值过低。 太低的阈值会产生许多不准确的伪标签,这会阻止网络学习目标区分表示。 通过所提出的方法,网络可以自适应地选择合适的阈值,以在整个训练过程中保持伪标签的充分性和准确性。 结果,模型可以对各种数据集和模型容量具有鲁棒性。
4.3 总体目标函数
总体目标函数可以表示为
$L= \underset{W^{E}, W^{D}, W^{C}}{\text{min}} \left(L_{E}+L_{D}+\beta L_{C}\right) \quad\quad(7)$
其中 β 是平衡参数。 编码器和鉴别器以对抗方式进行优化,将源样本和目标样本映射到公共域表示中。 编码器和分类器使用源和伪标记样本进行优化,以实现高分类性能。 详细的优化过程如算法 1 所示。
算法总结:

5 实验
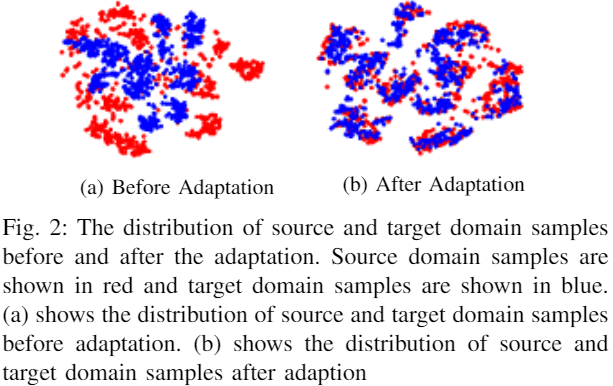
可视化:
6 总结
略
迁移学习《Efficient and Robust Pseudo-Labeling for Unsupervised Domain Adaptation》的更多相关文章
- 迁移学习(IIMT)——《Improve Unsupervised Domain Adaptation with Mixup Training》
论文信息 论文标题:Improve Unsupervised Domain Adaptation with Mixup Training论文作者:Shen Yan, Huan Song, Nanxia ...
- 迁移学习(JDDA) 《Joint domain alignment and discriminative feature learning for unsupervised deep domain adaptation》
论文信息 论文标题:Joint domain alignment and discriminative feature learning for unsupervised deep domain ad ...
- 论文解读(CDCL)《Cross-domain Contrastive Learning for Unsupervised Domain Adaptation》
论文信息 论文标题:Cross-domain Contrastive Learning for Unsupervised Domain Adaptation论文作者:Rui Wang, Zuxuan ...
- 论文解读(CDTrans)《CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation》
论文信息 论文标题:CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation论文作者:Tongkun Xu, Weihu ...
- 虚假新闻检测(CADM)《Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup》
论文信息 论文标题:Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversari ...
- 论文解读(CAN)《Contrastive Adaptation Network for Unsupervised Domain Adaptation》
论文信息 论文标题:Contrastive Adaptation Network for Unsupervised Domain Adaptation论文作者:Guoliang Kang, Lu Ji ...
- Unsupervised Domain Adaptation by Backpropagation
目录 概 主要内容 代码 Ganin Y. and Lempitsky V. Unsupervised Domain Adaptation by Backpropagation. ICML 2015. ...
- Deep Transfer Network: Unsupervised Domain Adaptation
转自:http://blog.csdn.net/mao_xiao_feng/article/details/54426101 一.Domain adaptation 在开始介绍之前,首先我们需要知道D ...
- Unsupervised Domain Adaptation Via Domain Adversarial Training For Speaker Recognition
年域适应挑战(DAC)数据集的实验表明,所提出的方法不仅有效解决了数据集不匹配问题,而且还优于上述无监督域自适应方法.
- 论文笔记:Unsupervised Domain Adaptation by Backpropagation
14年9月份挂出来的文章,基本思想就是用对抗训练的方法来学习domain invariant的特征表示.方法也很只管,在网络的某一层特征之后接一个判别网络,负责预测特征所属的domain,而后特征提取 ...
随机推荐
- CentOS 8.x系统安装配置图解教程
说明:截止目前CentOS-8.x最新版本为CentOS-8.4.2105,下面介绍CentOS-8.4.2105的具体安装配置过程 服务器相关设置如下: 操作系统:CentOS-8.4.2105 I ...
- Derivative of the Sigmoid function
一个详细介绍怎么推导Derivative of the Sigmoid function的文章- https://towardsdatascience.com/derivative-of-the-si ...
- vue下载图片
async works(obj) { await this.axios({ method: 'get', url: `entryFormControll ...
- 使用idea从零编写SpringCloud项目-Ribbo
git:https://github.com/bmdcheng/product_server git:https://github.com/bmdcheng/order_server 1.需要创建两个 ...
- 使用Jquery的.css('border')在火狐不兼容
改成如下就可以兼容火狐.IE.谷歌(border-left-color.border-left-width等)
- VS中多字节字符集和UNICODE字符集的使用说明
两者的核心区别: 1.在制作多国语言软件时,使用Unicode(UTF-16,16bits,两个字节).无特殊要求时,还是使用多字节字符集比较好. 2.如果要兼容C编程,只能使用多字节字符集.这里的兼 ...
- git练习网站(图形化版)
https://learngitbranching.js.org/?locale=zh_CN
- centos虚拟机yum update报错Another app is currently holding the yum lock; waiting for it to exit...
1.运行yum update报错 [root@localhost ~]# yum update已加载插件:fastestmirror, langpacks/var/run/yum.pid 已被锁定,P ...
- 数据库结构差异比较-SqlServer
/****** Object: StoredProcedure [dbo].[p_comparestructure_2005] Script Date: 2022/10/8 10:00:20 **** ...
- Linux部署JDK教程
上一次说了windows下的jdk部署,这一次记录下Linux下的jdk部署,恰巧遇到一篇写的很清楚的教程,我就直接转过来啦,哈哈.. 一. 解压安装jdk 在shell终端下进入jdk-6u14-l ...