python pandas库总结-数据分析和操作工具
Input/output相关函数
pandas.read_excel—将Excel文件读入pandas数据框
支持读取xls, xlsx, xlsm, xlsb, odf, ods和odt文件扩展名,支持单个sheet或sheet列表
语法格式
pandas.read_excel(io, sheet_name=0, *, header=0, names=None, index_col=None, usecols=None, squeeze=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, decimal='.', comment=None, skipfooter=0, convert_float=None, mangle_dupe_cols=True, storage_options=None)
常用的几个参数解释:
- io: 文件路径,也可以是URL。
- sheet_name: 接受字符串、整数、列表、None。默认为0,代表加载第一个sheet;输入
"sheet1"加载名字为"sheet1"的表;[1, 2, "sheet3"]表示加载第1、2个和名字为"sheet3"的sheet;None表示加载所有。 - header: 接受整数及整数列表。默认为0,表示第一行作为列标签。[1, 3]则表示第2和4行被组合为列标签。如果没有列标签则使用
None。 - names: 作用是给数据框添加列名。默认为
None。 - usecols: 接受str, list-like, or callable。默认为
None,表示解析所有列;"A,C,D:F"表示解析A,C,D,E,F列;[1,2,4]表示解析第2,3和5列;["name", "age"]表示解析列名为name, age的列。 - index_col: 接受整数及整数列表,添加行标签。默认为
None,表示无行标签。[1, 3]则表示第2和4列被组合为行标签。 - comment: 接受字符,默认为
None。注释字符串和当前行结束之间的任何数据都将被忽略。
代码示例
准备如下图所示的test.xlsx文件
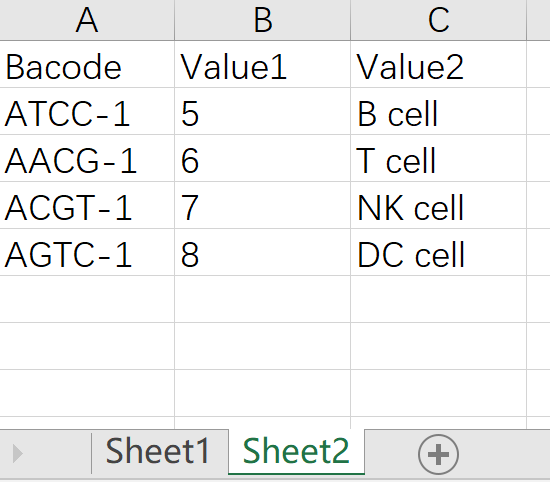
编写脚本
import pandas as pd
df = pd.read_excel("./input/test.xlsx", sheet_name="Sheet2")
print(df, "\n")
df1 = pd.read_excel(open("./input/test.xlsx", "rb"), sheet_name="Sheet2")
print(df1, "\n")
df2 = pd.read_excel("./input/test.xlsx", sheet_name="Sheet2", usecols="A:B") #usecols="A:B"等同于usecols="A,B"等同于usecols=[0,1],但usecol不能写成[0:1],会报错
print(df2, "\n")
df3 = pd.read_excel("./input/test.xlsx", sheet_name="Sheet2", usecols=[0,1], names=["index","Value"])
print(df3)输出结果
Bacode Value1 Value2
0 ATCC-1 5 B cell
1 AACG-1 6 T cell
2 ACGT-1 7 NK cell
3 AGTC-1 8 DC cell
Bacode Value1 Value2
0 ATCC-1 5 B cell
1 AACG-1 6 T cell
2 ACGT-1 7 NK cell
3 AGTC-1 8 DC cell
Bacode Value1
0 ATCC-1 5
1 AACG-1 6
2 ACGT-1 7
3 AGTC-1 8
index Value
0 ATCC-1 5
1 AACG-1 6
2 ACGT-1 7
3 AGTC-1 8pandas.DataFrame.to_excel—将对象写入Excel表
语法格式
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=_NoDefault.no_default, inf_rep='inf', verbose=_NoDefault.no_default, freeze_panes=None, storage_options=None)
常用的几个参数解释:
- excel_writer:文件路径或ExcelWriter(适用于写入多个sheet表)。
- sheet_name: 包含数据框的sheet,默认为"Sheet1"。
- na_rep: 缺失值处理方式。默认为“”。
- float_name: 为浮点数格式化字符串。
float_format="%.2f"表示保留两位小数点。 - columns: 可选项,接受序列或字符串列表,指出要写入的列。
- header: 添加列名。默认值为True。如果给出一个字符串列表,则假定它是列名的别名。
- index: 写行名,接受字符串列表和布尔值。默认为True,表示写入行名。
- engine: 可选项,常用的模式有'openpyxl'和'xlsxwriter'。其中xlsxwriter不支持append操作。
代码示例
import pandas as pd
df = pd.read_excel("./input/test.xlsx", sheet_name="Sheet2")
print(df, "\n")
#将单个对象写入一个.xlsx文件,只需要指定目标文件名
df.to_excel("./newfile/output.xlsx", index=False, sheet_name="expression")运行后会输出一个./newfile/output.xlsx文件,内容如下:
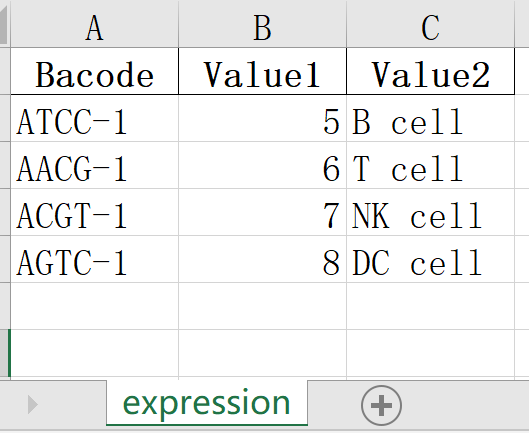
import pandas as pd
df = pd.read_excel("./input/test.xlsx", sheet_name="Sheet2")
print(df, "\n")
#写入多个sheet,必须创建一个ExcelWriter对象和目标文件名,并在文件中指定要写入的工作表。
#使用已经存在的文件名创建ExcelWriter对象将导致现有文件的内容被擦除。
df1 = df.copy()
with pd.ExcelWriter("./newfile/output.xlsx") as writer:
df.to_excel(writer, sheet_name="value1")
df1.to_excel(writer, sheet_name="value2")运行后会覆盖上一步生成的output.xlsx内容,并重新生成如下内容:
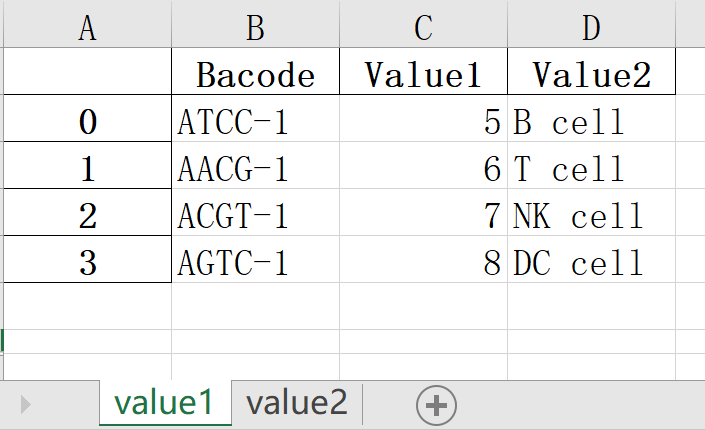
import pandas as pd
df = pd.read_excel("./input/test.xlsx", sheet_name="Sheet2")
print(df, "\n")
#ExcelWriter也可以被用来扩展已存在的文件
with pd.ExcelWriter("./newfile/output.xlsx", mode="a", engine='openpyxl') as writer:
df.to_excel(writer, sheet_name="value3")运行后会在上方excel基础上再添加一个名为value3的sheet。
pandas.read_csv—将csv文件读入pandas数据框,与pandas.read_excel类似
pandas.DataFrame.to_csv—将对象写入csv文件,与pandas.DataFrame.to_excel类似
DataFrame相关函数
pandas.DataFrame—构建二维、尺寸可变的表格数据结构
语法格式
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)
常用的几个参数解释:
- data: 一系列数据,包括多种类型;
- index: 索引值,行标签,默认值为RangeIndex(0, 1, 2, …, n);
- columns: 列标签,默认值为RangeIndex(0, 1, 2, …, n);
- dtype: 设置数据类型;
- copy: 布尔值或None,表示是否拷贝数据。
代码示例
pandas.DataFrame.groupby—使用映射器或通过一系列列对数据框进行分组
语法格式
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=_NoDefault.no_default, squeeze=_NoDefault.no_default, observed=False, dropna=True)
常用的几个参数解释:
- by: 可接受映射、函数、标签或标签列表。用于确定分组。
- axis: 接受0(index)或1(columns),表示按行分或按列分。默认按行分。
- level: 接受整数、level名,或序列,默认为None。不能与by选项同时使用。
- as_index: 接受布尔值。默认值为True,表示整合输出时返回以group标签为索引的对象。
- dropna: 布尔值。默认为True,表示删除NA
import pandas as pd
import numpy as np
# import matplotlib.pyplot as plt
#利用列表创建DataFrame
d1 = [[3,"negative",2],[4,"negative",6],[11,"positive",0],[12,"positive",2]]
df1 = pd.DataFrame(d1, columns=["xuhao","result","value"])
print(df1)
print(df1.dtypes)
#利用字典创建DataFrame
d2 = {'xuhao': [3,4,11,12], 'result': ["negative","negative","positive",\
"positive"],"value":[2,6,0,2]}
df2 = pd.DataFrame(d2, dtype=np.int8)
print (df2)
print(df2.dtypes)
#利用包含Series的字典创建DataFrame
d3 = {'xuhao': [3,4,11,12], 'result': ["negative","negative","positive",\
"positive"],"value": pd.Series([2,3], index=[2,3])}
df3 = pd.DataFrame(d3,index=[0, 1, 2, 3])
print (df3)
#利用numpy ndarray创建DataFrame
df4 = pd.DataFrame(np.array([[3,"negative",2],[4,"negative",6],[11,"positive",0],\
[12,"positive",2]]), columns=["xuhao","result","value"])
print(df4)
#利用包含标签列的numpy ndarray创建DataFrame
d5 = np.array([(1,3,2),(2,4,6),(3,1,0),(4,3,2)],\
dtype=[("xuhao", "i4"), ("result", "i4"), ("value", "i4")])
df5 = pd.DataFrame(d5)
df6 = pd.DataFrame(d5, columns=["result","value"])
print(df5)
print(df6)
#利用dataclass创建DataFramepython pandas库总结-数据分析和操作工具的更多相关文章
- python pandas库——pivot使用心得
python pandas库——pivot使用心得 2017年12月14日 17:07:06 阅读数:364 最近在做基于python的数据分析工作,引用第三方数据分析库——pandas(versio ...
- Python Pandas库的学习(二)
今天我们继续讲下Python中一款数据分析很好的库.Pandas的学习 接着上回讲到的,如果有人听不懂,麻烦去翻阅一下我前面讲到的Pandas学习(一) 如果我们在数据中,想去3,4,5这几行数据,那 ...
- Python pandas库159个常用方法使用说明
Pandas库专为数据分析而设计,它是使Python成为强大而高效的数据分析环境的重要因素. 一.Pandas数据结构 1.import pandas as pd import numpy as np ...
- Python Pandas库的学习(三)
今天我们来继续讲解Python中的Pandas库的基本用法 那么我们如何使用pandas对数据进行排序操作呢? food.sort_values("Sodium_(mg)",inp ...
- Python——Pandas库入门
一.Pandas库介绍 Pandas是Python第三方库,提供高性能易用数据类型和分析工具 import pandas as pd Pandas基于NumPy实现,常与NumPy和Matplotli ...
- Python Pandas库 初步使用
用pandas+numpy读取UCI iris数据集中鸢尾花的萼片.花瓣长度数据,进行数据清理,去重,排序,并求出和.累积和.均值.标准差.方差.最大值.最小值
- Python Pandas库的学习(一)
今天我们来学习一下Pandas库,前面我们讲了Numpy库的学习 接下来我们学习一下比较重要的库Pandas库,这个库比Numpy库还重要 Pandas库是在Numpy库上进行了封装,相当于高级Num ...
- Python Pandas 库的使用例子
主要在jupyter notebook里面熟悉这个库的使用,它的安装方法与实现,可自行搜索. Pandas是一个优秀的数据分析工具,官网:http://pandas.pydata.org/ 相关的库使 ...
- python pandas库的基本内容
pandas主要为数据预处理 DataFrame import pandas food_info = pandas.read_csv("路径") #绝对路径和相对路径都可以 ty ...
- Python Pyinstaller打包含pandas库的py文件遇到的坑
今天的主角依然是pyinstaller打包工具,为了让pyinstaller打包后exe文件不至过大,我们的py脚本文件引用库时尽可能只引用需要的部分,不要引用整个库,多使用“from *** imp ...
随机推荐
- JavaScript垃圾回收机制的了解
对于js种的任意长度字符串,对象,数组是没有固定大小的,只有在分配存储时,解释器就会分配内存来存储这些数据.当js的解释器消耗完系统所有可用内存时,就会造成系统崩溃.因此js有着自己的一套垃圾回收机制 ...
- hadoop克隆三台虚拟机安装JDK和hadoop并配置环境变量
首先将模板虚拟机关机,进行对模板虚拟机的克隆. 选择完整克隆 克隆三台虚拟机. 注意虚拟机的移除与删除 打开hadoop102,修改ip地址与hostname 切换至root用户,或以root用户登录 ...
- ant design vue的tooltip的宽度修改不生效
// 注意,vue 项目,style 标签不能加 scoped 选项,否则样式不生效 <a-tooltip placement="top" :overlayClassName ...
- 1.3 C语言--指针与结构体
指针 指针概念的引入 关于内存 程序有数据和指令组成,数据和指令在执行过程中存放在内存中.变量是程序数据中的一种,因此变量也存储在内存中:内存中的每个字节都有一个唯一的编码,即内存地址.32位机的内存 ...
- Git、GitHub、GitLab三者之间的区别
1.Git Git是一个版本控制系统. 版本控制是一种用于记录一个或多个文件内容变化,方便我们查阅特定版本修订情况的系统. 总结: (1)分布式版本控制系统下的本地仓库包含代码库还有历史库,在本地就可 ...
- vue搭建项目iview+axios+less
项目地址:https://github.com/CinderellaStory/vue-iview-project vue搭建项目壳子已安装:iview.axios.less 已有界面:登录.左侧菜单 ...
- cp 备份文件命令
cp -p system.sh ./bak2022/systecm.sh.bak_`date '+%Y%m%d'` (备份system.sh文件后缀以bak_年月日命令)cp -rf old copy ...
- PTA1002 写出这个数 (20 分)
1002 写出这个数 (20 分) 读入一个正整数 n,计算其各位数字之和,用汉语拼音写出和的每一位数字. 输入格式: 每个测试输入包含 1 个测试用例,即给出自然数 n 的值.这里保证 n 小于 1 ...
- thymeleaf基础学习
Thymeleaf 1.标准表达式 ${...}:变量表达式 *{...}: 选择表达式 #{...} : 消息表达式 @{...}: 连接表达式 <img th:src="@{url ...
- XML_DTD_20200415
<!-- xml的注释写法 --> 格式良好的xml语言必须具备的几个条件 1.必须有xml声明语句,声明版本号与编码字符集 2.必须有且仅有一个根元素 3.标签大小写敏感 4.属性值 ...