Dropout----Dropout来源
一、简单介绍及公式
Dropout是深度学习中强大的正则化方法。过程很简单:在训练时候,随机的挑选一些节点参与预测和反向传播,当test时候,全部节点参与,但是权重要乘以留存概率p。数学实现是:
\]
其中,\(z_i^{l+1}\)表示l+1层的某个节点,\(z^{l}\)表示l层的一个整层。\(B(p)\)表示概率为p的二项式概率分布函数。\(W_i^{l}\)表示\(z_i^{l+1}\)的权重矩阵。\(b_i^{l}\)表示\(z_i^{l+1}\)的偏置向量。
与标准网络相比,只是多了一个二项式函数。
在traing阶段,与标准网络对比如下图,
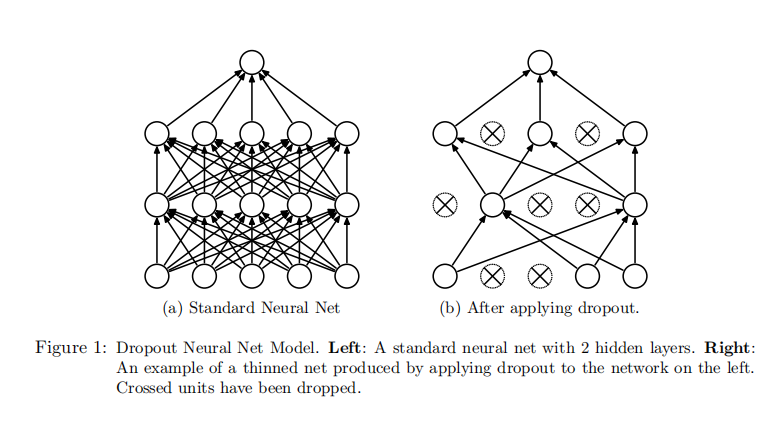
二、为什么dropout有效-原因定性分析
关于Dropout有效的原因,大多数都是在定性分析,并没有太多的定量分析,以下是一些观点。
首先是Nitish Srivastava的观点《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》。
2.1 ensemble论
2.1.1 ensemble
这个是Nitish Srivastava的《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》原文的观点。通常比较好的缓解过拟合的方法是ensemble(类似随机森林的方法),但是训练神经网络很费时间和金钱(这篇文章是14年前出来的,算力确实不怎么够),所以ensemble好像是不成。但是假如,退一步,如果我们在训练时候随机去掉部分节点,那么就好像我们每次都在训练一个个独立的新网络,网络训练好之后,就可以看做共享部分节点的N多个神经网络ensemble在一起了。这个观点有点牵强。
2.1.2 动机:联合适应(co-adapting)
试想,50个恐怖分子搞破坏,如果是50人一起去搞破坏,搞了一两次破坏后,容易被团灭。如果是5人一组,分成10组,搞得破坏次数就能增加很多。前者就是co-adapting,后者是相对来说集中性小,联合性弱,适应能力更加强。
自然界中,细菌病毒这类的,它们是无性繁殖,DNA或者RNA是自我复制的。另外一种是有性繁殖,每次都需要交叉母本和父本的DNA,生成子代的DNA。前者面对的环境简单,不求生存率,所以每次基本很少变异,遗传物质是大段大段的拷贝的,可以认为很多碱基对联合一起工作的。后者,面对的环境复杂,遗传物质多,所以将功能拆分到许许多多的小基因片段中,是相对小联合一起工作。
现在回到神经网络中,那么多的神经节点一起工作,那么不是就很容易就又大规模co-adapting的吗?而dropout后,肯定缩小co-adapting的规模。所以dropout减少了其co-adaping。
思考:
如果我们造一些很窄的网络,然后ensemble在一起如何,会不会以后dropout那么好?
猜想:应该不是的,1)神经网络更深更宽,能力更加强悍,窄网络可能会有泛化能力不足的问题。2)多个窄网络训练起来比较费时间。
2.1.3 推论和小技巧
dropout是正则的一种,用于治疗过拟合的。经过上面的介绍,应该有些简单的推论:
- 因为是ensemble,所以dropout=0.5的时候效果最好,因为这样随机性最大。调训的N个网络,最不一样。
- 可以用于治疗数据量不足引起的过拟合,但是对于其他类型的过拟合不适用。
- 治疗过拟合,数据集越大,dropout效果越好。(其他的正则化方法也存在这类)
- 与其他方法搭配更好:soft-weight sharing, max-norm regularization等
2.2 噪音派
dropout可以拿来做数据增强(Data Augmentation),而其之所以有效是因为在训练数据中加了噪音。
- 不明白点1:dropout后,样本空间变小了,样本数量不应该变少了吗?为什么还能达到数据增多的效果?
当样本集是非线性空间的时候,使用一系列的局部特征,会使预测更加稳定。dropout能够造成稀疏性。确实,因为他们在学习过程中,去掉了某些节点,也就是置0,那么结果是很多时候生产的向量具有一定的稀疏性。dropout能够帮助学习到更多的局部特征。
不明白点:当样本集是非线性空间的时候,使用一系列的局部特征,会使预测更加稳定。
不明白点:dropout由固定值变为一个区间,可以提高效果
dropout学习出来的特征向量具有稀疏性
待做实验:试验中,纯二值化的特征的效果也非常好,说明了稀疏表示在进行空间分区的假设是成立的,一个特征是否被激活表示该样本是否在一个子空间中。
四、缺点
- dropout后训练时间更长,2-3倍
Dropout----Dropout来源的更多相关文章
- 深度学习(dropout)
other_techniques_for_regularization 随手翻译,略作参考,禁止转载 www.cnblogs.com/santian/p/5457412.html Dropout: D ...
- [转]理解dropout
理解dropout 原文地址:http://blog.csdn.net/stdcoutzyx/article/details/49022443 理解dropout 注意:图片都在github上 ...
- tensorflow dropout函数应用
1.dropout dropout 是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络,这篇博客中讲的非常详细 2.tens ...
- 深度学习(一)cross-entropy softmax overfitting regularization dropout
一.Cross-entropy 我们理想情况是让神经网络学习更快 假设单模型: 只有一个输入,一个神经元,一个输出 简单模型: 输入为1时, 输出为0 神经网络的学习行为和人脑差的很多, 开始学习 ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- dropout 为何会有正则化作用
在神经网络中经常会用到dropout,大多对于其解释就是dropout可以起到正则化的作用. 一下是我总结的对于dropout的理解.花书上的解释主要还是从模型融合的角度来解释,末尾那一段从生物学角度 ...
- Dropout & Maxout
[ML] My Journal from Neural Network to Deep Learning: A Brief Introduction to Deep Learning. Part. E ...
- 理解dropout
理解dropout 注意:图片都在github上放着,如果刷不开的话,可以考虑FQ. 转载请注明:http://blog.csdn.net/stdcoutzyx/article/details/490 ...
- 深度学习面试题14:Dropout(随机失活)
目录 卷积层的dropout 全连接层的dropout Dropout的反向传播 Dropout的反向传播举例 参考资料 在训练过程中,Dropout会让输出中的每个值以概率keep_prob变为原来 ...
- TensorFlow——dropout和正则化的相关方法
1.dropout dropout是一种常用的手段,用来防止过拟合的,dropout的意思是在训练过程中每次都随机选择一部分节点不要去学习,减少神经元的数量来降低模型的复杂度,同时增加模型的泛化能力. ...
随机推荐
- 新型MPP的Doris数据库:数据模型和数据分区使用详解
Apache Doris是一个现代化的MPP分析性数据库产品.是一个由百度开源,在2018年贡献给Apache基金会,成为有顶级开源项目.仅需要亚秒级响应时间即可获得查询结果,可以有效地支持实时数据分 ...
- Postgres常用时间查询
如select extract(day from now());
- React报错之`value` prop on `input` should not be null
正文从这开始~ 总览 当我们把一个input的初始值设置为null或者覆盖初始值设置为null时,会产生"valueprop on input should not be null" ...
- 关于KeyFile的破解,含注册机源代码
程序来自于<加密与解密3>的第五章的PacMe.exe.书中并没有给出C语言实现的加密与解密代码,自己花了一些时间,把代码还原了,并且写了一个C语言的注册机. 加密原理:正如书中所说,此程 ...
- Vim基础用法,最常用、最实用的命令介绍(保姆级教程)
配置文件设置 set number (设置行号) set nocompatible (设置不兼容vi模式,不设置会导致许多vim特性被禁用) set clipboard=unnamed (设置普通的复 ...
- 《Python高手之路 第3版》这不是一本常规意义上Python的入门书!!
<Python高手之路 第3版>|免费下载地址 作者简介 · · · · · · Julien Danjou 具有12年从业经验的自由软件黑客.拥有多个开源社区的不同身份:Debian开 ...
- 图解OSI七层模型
七层模型,亦称OSI(Open System Interconnection)参考模型,是参考模型是国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系.它是一个七层的.抽象的模型体 ...
- 服务器时间同步架构与实现chrony
实验背景 模拟企业局域服务器时间同步,保障各服务器系统准确性和时间一致性. 时间服务器系统搭建 实验架构图 环境设备 设备IP规划 国内互联网NTP服务器 ntp.aliyun.com #阿里云NTP ...
- day24--Java集合07
Java集合07 14.HashMap底层机制 (k,v)是一个Node,实现了Map.Entry<K,V>,查看HashMap的源码可以看到 jdk7.0 的HashMap底层实现[数组 ...
- Markdown使用指南
1. Markdown是什么? Markdown是一种轻量级标记语言,它以纯文本形式(易读.易写.易更改)编写文档,并最终以HTML格式发布. Markdown也可以理解为将以MARKDOWN语法编写 ...