吴裕雄 python 机器学习——核化PCAKernelPCA模型
# -*- coding: utf-8 -*- import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets,decomposition def load_data():
'''
加载用于降维的数据
'''
# 使用 scikit-learn 自带的 iris 数据集
iris=datasets.load_iris()
return iris.data,iris.target #核化PCAKernelPCA模型
def test_KPCA(*data):
X,y=data
kernels=['linear','poly','rbf','sigmoid']
# 依次测试四种核函数
for kernel in kernels:
kpca=decomposition.KernelPCA(n_components=None,kernel=kernel)
kpca.fit(X)
print('kernel=%s --> lambdas: %s'% (kernel,kpca.lambdas_)) # 产生用于降维的数据集
X,y=load_data()
# 调用 test_KPCA
test_KPCA(X,y)

...................

....................
def plot_KPCA(*data):
'''
绘制经过 KernelPCA 降维到二维之后的样本点
'''
X,y=data
kernels=['linear','poly','rbf','sigmoid']
fig=plt.figure()
# 颜色集合,不同标记的样本染不同的颜色
colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2)) for i,kernel in enumerate(kernels):
kpca=decomposition.KernelPCA(n_components=2,kernel=kernel)
kpca.fit(X)
# 原始数据集转换到二维
X_r=kpca.transform(X)
## 两行两列,每个单元显示一种核函数的 KernelPCA 的效果图
ax=fig.add_subplot(2,2,i+1)
for label ,color in zip( np.unique(y),colors):
position=y==label
ax.scatter(X_r[position,0],X_r[position,1],label="target= %d"%label,
color=color)
ax.set_xlabel("X[0]")
ax.set_ylabel("X[1]")
ax.legend(loc="best")
ax.set_title("kernel=%s"%kernel)
plt.suptitle("KPCA")
plt.show() # 调用 plot_KPCA
plot_KPCA(X,y)

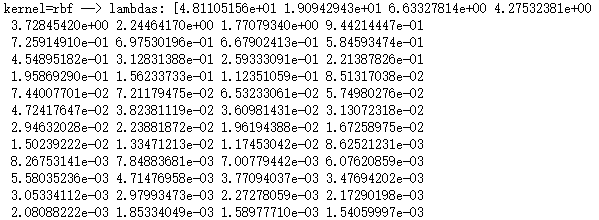
def plot_KPCA_poly(*data):
'''
绘制经过 使用 poly 核的KernelPCA 降维到二维之后的样本点
'''
X,y=data
fig=plt.figure()
# 颜色集合,不同标记的样本染不同的颜色
colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2))
# poly 核的参数组成的列表。
# 每个元素是个元组,代表一组参数(依次为:p 值, gamma 值, r 值)
# p 取值为:3,10
# gamma 取值为 :1,10
# r 取值为:1,10
# 排列组合一共 8 种组合
Params=[(3,1,1),(3,10,1),(3,1,10),(3,10,10),(10,1,1),(10,10,1),(10,1,10),(10,10,10)]
for i,(p,gamma,r) in enumerate(Params):
# poly 核,目标为2维
kpca=decomposition.KernelPCA(n_components=2,kernel='poly',gamma=gamma,degree=p,coef0=r)
kpca.fit(X)
# 原始数据集转换到二维
X_r=kpca.transform(X)
## 两行四列,每个单元显示核函数为 poly 的 KernelPCA 一组参数的效果图
ax=fig.add_subplot(2,4,i+1)
for label ,color in zip( np.unique(y),colors):
position=y==label
ax.scatter(X_r[position,0],X_r[position,1],label="target= %d"%label,
color=color)
ax.set_xlabel("X[0]")
# 隐藏 x 轴刻度
ax.set_xticks([])
# 隐藏 y 轴刻度
ax.set_yticks([])
ax.set_ylabel("X[1]")
ax.legend(loc="best")
ax.set_title(r"$ (%s (x \cdot z+1)+%s)^{%s}$"%(gamma,r,p))
plt.suptitle("KPCA-Poly")
plt.show() # 调用 plot_KPCA_poly
plot_KPCA_poly(X,y)
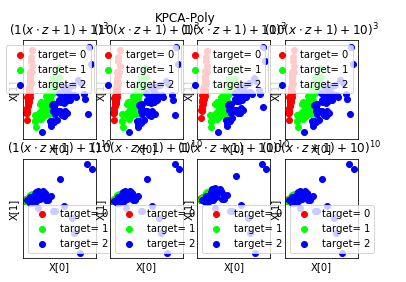
def plot_KPCA_rbf(*data):
'''
绘制经过 使用 rbf 核的KernelPCA 降维到二维之后的样本点
'''
X,y=data
fig=plt.figure()
# 颜色集合,不同标记的样本染不同的颜色
colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2))
# rbf 核的参数组成的列表。每个参数就是 gamma值
Gammas=[0.5,1,4,10]
for i,gamma in enumerate(Gammas):
kpca=decomposition.KernelPCA(n_components=2,kernel='rbf',gamma=gamma)
kpca.fit(X)
# 原始数据集转换到二维
X_r=kpca.transform(X)
## 两行两列,每个单元显示核函数为 rbf 的 KernelPCA 一组参数的效果图
ax=fig.add_subplot(2,2,i+1)
for label ,color in zip( np.unique(y),colors):
position=y==label
ax.scatter(X_r[position,0],X_r[position,1],label="target= %d"%label,
color=color)
ax.set_xlabel("X[0]")
# 隐藏 x 轴刻度
ax.set_xticks([])
# 隐藏 y 轴刻度
ax.set_yticks([])
ax.set_ylabel("X[1]")
ax.legend(loc="best")
ax.set_title(r"$\exp(-%s||x-z||^2)$"%gamma)
plt.suptitle("KPCA-rbf")
plt.show() # 调用 plot_KPCA_rbf
plot_KPCA_rbf(X,y)
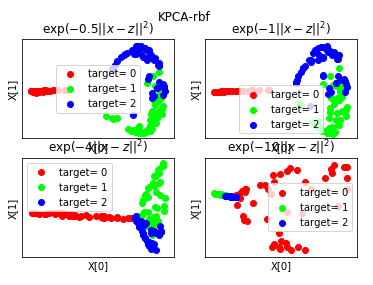
def plot_KPCA_sigmoid(*data):
'''
绘制经过 使用 sigmoid 核的KernelPCA 降维到二维之后的样本点
'''
X,y=data
fig=plt.figure()
# 颜色集合,不同标记的样本染不同的颜色
colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2))
# sigmoid 核的参数组成的列表。
Params=[(0.01,0.1),(0.01,0.2),(0.1,0.1),(0.1,0.2),(0.2,0.1),(0.2,0.2)]
# 每个元素就是一种参数组合(依次为 gamma,coef0)
# gamma 取值为: 0.01,0.1,0.2
# coef0 取值为: 0.1,0.2
# 排列组合一共有 6 种组合
for i,(gamma,r) in enumerate(Params):
kpca=decomposition.KernelPCA(n_components=2,kernel='sigmoid',gamma=gamma,coef0=r)
kpca.fit(X)
# 原始数据集转换到二维
X_r=kpca.transform(X)
## 三行两列,每个单元显示核函数为 sigmoid 的 KernelPCA 一组参数的效果图
ax=fig.add_subplot(3,2,i+1)
for label ,color in zip( np.unique(y),colors):
position=y==label
ax.scatter(X_r[position,0],X_r[position,1],label="target= %d"%label,
color=color)
ax.set_xlabel("X[0]")
# 隐藏 x 轴刻度
ax.set_xticks([])
# 隐藏 y 轴刻度
ax.set_yticks([])
ax.set_ylabel("X[1]")
ax.legend(loc="best")
ax.set_title(r"$\tanh(%s(x\cdot z)+%s)$"%(gamma,r))
plt.suptitle("KPCA-sigmoid")
plt.show() # 调用 plot_KPCA_sigmoid
plot_KPCA_sigmoid(X,y)
吴裕雄 python 机器学习——核化PCAKernelPCA模型的更多相关文章
- 吴裕雄 python 机器学习——分类决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——回归决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——线性回归模型
import numpy as np from sklearn import datasets,linear_model from sklearn.model_selection import tra ...
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——混合高斯聚类GMM模型
import numpy as np import matplotlib.pyplot as plt from sklearn import mixture from sklearn.metrics ...
- 吴裕雄 python 机器学习——层次聚类AgglomerativeClustering模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——密度聚类DBSCAN模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——等度量映射Isomap降维模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——支持向量机非线性回归SVR模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
随机推荐
- 初识XXE漏洞
本文是参照本人觉得特别仔细又好懂的一位大佬的文章所做的学习笔记 大佬的链接:https://www.cnblogs.com/zhaijiahui/p/9147595.html#autoid-0-0-0 ...
- Linux下用Bash语言实现判断素数的功能
题目链接: 题目描述 写一个判断素数的函数,在主函数输入一个整数,输出是否是素数的消息. 输入 一个数 输出 如果是素数输出prime 如果不是输出not prime 样例输入 97 样例输出 pri ...
- Python-Django学习笔记(一)-MTV设计模式
Django是开源的.大而且全的Web应用框架. 它独具特色,采用了MTV设计模式. MTV框架包括:Model(模型).Template(模板)和View(视图) Model(模型):负责业务对象与 ...
- [Arc068D/At2299] Card Eater - 结论
[Arc068D/At2299] 有一堆牌,每张牌上有一个数字. 每次可以取出其中 \(3\) 张,丢掉数字最大的和数字最小的牌,把中间那张再放回牌堆. 要求最后所有剩余牌上的数字互不相同,求最多能剩 ...
- main中的argv和argc
int main(int argc,char* argv[]) 给程序传递命令行参数:第一个参数的值是第二个参数的数组元素个数,即统计运行程序时送给main函数的命令行参数个数. 第二个参数总是cha ...
- JS代码的位置
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- js前端模块化的前世今生
前言: <!DOCTYPE html> <html> <head> <title></title> </head> <sc ...
- python面试的100题(20)
76.递归函数停止的条件? 递归的终止条件一般定义在递归函数内部,在递归调用前要做一个条件判断,根据判断的结果选择是继续调用自身,还是return:返回终止递归.终止的条件:1.判断递归的次数是否达到 ...
- Codeforces Round #601 (Div. 2) A Changing Volume
好吧,其实我拿到这个题的时候,首先想到了bfs,写完之后,开开森森的去交代码,却在第二个数据就TEL,然后优化半天,还是不行. 最终,我盯着1,2,5发呆半天,wc,然后直接贪心 #include&l ...
- 题解 【洛谷P1115】最大子段和
这是一道枚举经典题. 本题有三种做法,各位需要根据每个题的数据范围来决定自己用哪种方法. 本题解中统一设最大和为Max. 方法一. 枚举子序列,从起点到终点求和.时间复杂度:O(n^3) 我们可以枚举 ...