spark-shuffle分析
前言
shuffle是分布式计算系统中最重要的一部分,spark和mapreduce的shuffle的大体思路类似,在实现上有一些区分。Spark提供了插件式的接口,使用者可以通过继承ShuffleManager来自定义,并通过`spark.shuffle.manager`来声明自定义的ShuffleManager。
shuffle-write
shuffle-write在shuffle中是最重要的,数据存储包括内存和磁盘两部分,数据文件包括数据实体文件和索引文件。整体思路为数据优先存储在内存,如果数据量过大,那么spill到磁盘。spill到磁盘采用了单文件的方式,在一个文件里分为多个段,一个task的shuffle数据输出到文件的一个段,另外再写一个index文件,记录段在文件中的位置信息,所以spark的shuffle过程中在map阶段只会产出两个文件。参考图1,大致描绘出了文件的样子,整个流程可以拆解成3个步骤来看,下面结合代码进行详细分析。
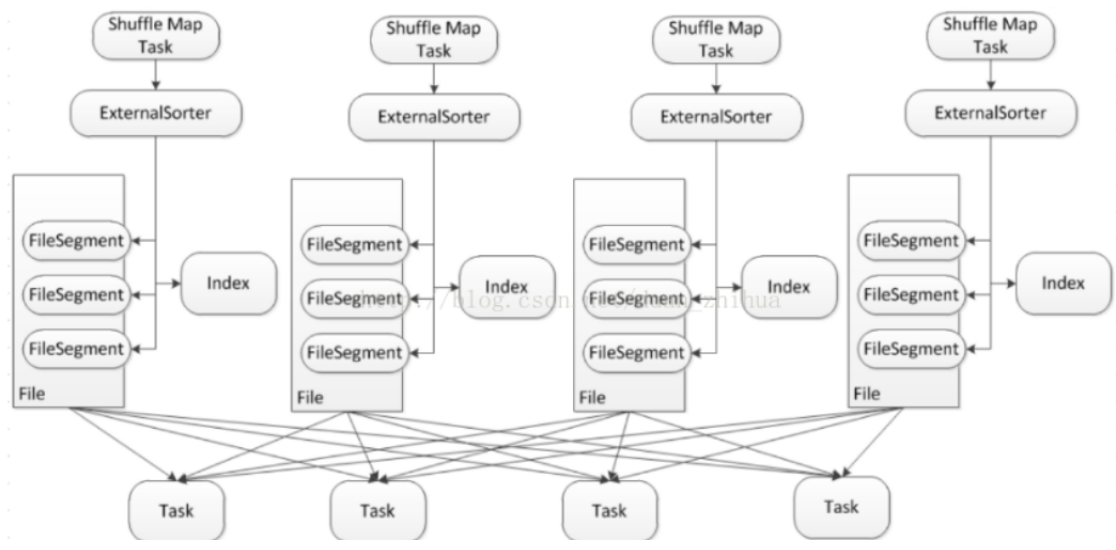
图1
接收shuffle数据
首先shuffleWrite的入口是SortShuffleWriter,这是spark默认的ShuffleWriter实例。每个spark的task都会调用write()方法将shuffle数据传入,其内部再通过委托的方式,代理给ExternalSorter进行真正的处理,这里需要注意的是每次调用都会创建一个新的ExternalSort对象,也就是说ExternalSort这个类在task层面来说是无状态的,所有的状态都存储在文件中,再通过ExternalSort.insertAll()方法将数据记录起来,这其中分为两步,1.首先将数据缓存在内存里;2.检查是否需要将内存中的数据spill到磁盘,这是通过继承Spillable类,调用maybeSpill()方法,思路是比较内存中的数据大小和还能申请到的内存大小。。
如果检查发现需要spill,那么就调用spillMemoryIteratorToDisk()方法,生成一个UUID作为该spill数据的blockId,再通过DiskBlockObjectWriter类将数据写到磁盘。这里对DiskBlockObjectWriter类做下分析,因为这个类很重要,所有spill的数据都是通过这个类落盘的。首先DiskBlockObjectWriter通过实现一套事务的机制来保证写数据没有问题,原理如下,1.定义3个position,分别追踪已经commit成功的数据position,已经度量过的数据position(这个重点是用于统计信息)和正在写的数据position。并通过FileChannel特性来进行position回滚,当写数据出现问题,就truncate到上一次commit成功的position。在落盘之前,spark还会对数据进行排序(如果需要的话),最后通过遍历所有的partition,将每个partition通过DiskBlockObjectWriter写入磁盘,返回一个FileSegment,包含了数据在文件中的position以及长度,partition和FileSegment是一一对应的。
如果不需要spill,那么数据会被临时缓存在内存中,下面分析一下在内存中的数据结构, spark采用了两个容器来分别对待是否需要在map端做合并的数据,如果需要在map端合并,那么使用类`PartitionedAppendOnlyMap`,如果不需要在map端合并,那么使用类`PartitionedPairBuffer`。PartitionedAppendOnlyMap和PartitionedPairBuffer底层都使用了hash表的概念,但是没有用java或者scala的map库,而是自己基于数组实现了一个简易的hash表,通过对key的hash(key由partition+数据的key组成)来决定在数组中的位置,合并后的value存储在key的后一位。这个两个容器的区别在于,需要在map端shuffle合并的value会经常发生更新,而key是固定不变的,这也是为什么没有复用代码的原因,通用的工具在效率上肯定是没有专用的高的。
到这里,SortShuffleWriter.write()中ExternalSorter.insertAll()分析结束。
写shuffle数据到磁盘
下一个重要的方法是SortShuffleWriter.write()中的ExternalSorter.writePartitionedFile(),如果之前有spill的文件,那么会进行合并,合并的对象是spill文件以及在内存中的数据,如果之前没有spill的文件,那么直接将内存中的数据写到文件,这样保证了一个exectuor永远只需要委会一份spill文件。数据文件名格式为shuffleId+MapId+reduceId。注意,这里除了合并数据之外,还会对需要aggregate的数据进行聚合,对需要排序的数据进行排序。合并过程是通过为每个partition生成一个迭代器,然后遍历所有与迭代器,写到新的spill文件中。
写index文件到磁盘
最后一步就是写index文件,参考类`IndexShuffleBlockResolver`,将每个partition的数据长度依次写到index临时文件中,然后进行校验,检查数据文件和index文件中的数据长度是否一致(这里涉及到一个多线程的问题,由于一个executor只维护一份index文件,所以可能有多个task操作同一个index文件,这里采用了synchronized,也就是独占锁)。如果校验成功,那么说明index文件已经被成功更新,那么放弃此次更新,如果不成功,那么说明这是第一次更新成功,把index的临时文件名改为正式的index文件名。临时文件名是在正式文件名加上.uuid后缀。
shuffle-read
说完了shuffle write过程,下面分析一下shuffle read过程。shuffle read从整体看可以分为2大部分,下面基于类`BlockStoreShuffleReader`详细分析。
数据拉取
数据拉取分为两个部分,一个是本地数据拉取,也就是shuffle spill的文件正好和读取的executor位于同一个节点,另一个是远程数据拉取,基于netty获取远程数据。整个过程也是优先内存,然后spill到磁盘的方式。参考`ShuffleBlockFecherIterator`,大致思路是,在初始化的时候先尝试拉一批数据,这样在迭代器遍历的时候(next操作)可以直接返回,如果数据遍历完了,那么再尝试拉一批数据,这种思路可以看做是lazy load的方式。
数据处理
这步的数据输入是上一步拉取到的数据,也就是说数据存在于内存和磁盘。然后和shuffle-write中的接收数据类似,spark通过实现一个容器`ExternalAppendOnlyMap`来缓存拉取到的数据,过程中会对聚合等操作做处理,如果内存空间不足也会spill到磁盘。所以在大数据量的情况下这里真的是瓶颈,需要两个磁盘IO。数据处理完后再通过`ExternalAppendOnlyMap.ExternalIterator`对外提供整合内存和磁盘数据的迭代器,让上层对数据的存储介质不敏感。
配置
|
key |
默认 |
解释 |
|
spark.reducer.maxSizeInFlight |
48m |
shuffle-read每次进行数据拉取的数据量上限,如果executor内存充足,可以调大 |
|
spark.reducer.maxReqsInFlight |
Int.MaxValue |
迭代器中触发next后最多可以请求的次数。一般不做限制 |
|
spark.reducer.maxBlocksInFlightPerAddress |
Long.MaxValue |
shuffle-read每次请求一个地址时获取最多的block数量。如果block数据很多,可能会导致提供block的exxcutor压力过大 |
|
spark.shuffle.file.buffer |
32k |
shuffle中所有涉及写文件时指定的outputStream中的buffer大小 |
总结
shuffle是分布式计算引擎的核心技术,也是最大的性能瓶颈。SortShuffle 相比HashShuffle极大的减少了中间文件的产生,但还是避免不了数据大量的写磁盘操作。了解了原理后,在用spark框架的时候需要尽量减少shuffle的数据量,优先做一些在map端的聚合。
参考资料
// spark 2.1.0代码
// 很详细的基于代码的分析
https://blog.csdn.net/duan_zhihua/article/details/71190682
spark-shuffle分析的更多相关文章
- Spark Shuffle Write阶段磁盘文件分析
这篇文章会详细介绍,Sort Based Shuffle Write 阶段是如何进行落磁盘的 流程分析 入口处: org.apache.spark.scheduler.ShuffleMapTask.r ...
- Spark Shuffle数据处理过程与部分调优(源码阅读七)
shuffle...相当重要,为什么咩,因为shuffle的性能优劣直接决定了整个计算引擎的性能和吞吐量.相比于Hadoop的MapReduce,可以看到Spark提供多种计算结果处理方式,对shuf ...
- Spark Shuffle实现
Apache Spark探秘:Spark Shuffle实现 http://dongxicheng.org/framework-on-yarn/apache-spark-shuffle-details ...
- Spark Shuffle模块——Suffle Read过程分析
在阅读本文之前.请先阅读Spark Sort Based Shuffle内存分析 Spark Shuffle Read调用栈例如以下: 1. org.apache.spark.rdd.Shuffled ...
- spark shuffle
Spark Shuffle 1. Shuffle相关 当Map的输出结果要被Reduce使用时,输出结果需要按key哈希,并且分发到每一个Reducer上去,这个过程就是shuffle.由于shuff ...
- spark shuffle过程分析
spark shuffle流程分析 回到ShuffleMapTask.runTask函数 如今回到ShuffleMapTask.runTask函数中: overridedef runTask(cont ...
- Spark Shuffle(ExternalSorter)
1.Shuffle流程 spark的shuffle过程如下图所示,和mapreduce中的类似,但在spark2.0及之后的版本中只存在SortShuffleManager而将原来的HashShuff ...
- Spark Shuffle之Sort Shuffle
源文件放在github,随着理解的深入,不断更新,如有谬误之处,欢迎指正.原文链接https://github.com/jacksu/utils4s/blob/master/spark-knowled ...
- Spark Shuffle 堆外内存溢出问题与解决(Shuffle通信原理)
Spark Shuffle 堆外内存溢出问题与解决(Shuffle通信原理) http://xiguada.org/spark-shuffle-direct-buffer-oom/ 问题描述 Spar ...
- Spark Shuffle的技术演进
在Spark或Hadoop MapReduce的分布式计算框架中,数据被按照key分成一块一块的分区,打散分布在集群中各个节点的物理存储或内存空间中,每个计算任务一次处理一个分区,但map端和re ...
随机推荐
- java读取resource目录下的配置文件
java读取resource目录下的配置文件 1:配置resource目录 下的文件 host: 127.0.0.1 port: 9300 2:读取 / 代表resource目录 InputSt ...
- 前端js如何生成一个对象,并转化为json字符串
https://www.cnblogs.com/May-day/p/6841958.html 一,直接上代码 <script src="../../Content/jquery-2.0 ...
- [django]form不清空问题解决
https://www.cnblogs.com/OldJack/p/7118396.html 有时候提交表单后,发现某个字段写错了,但是form的其他字段竟然被清空,这个万万不能接受.所有django ...
- python三步实现人脸识别
原文地址https://www.toutiao.com/a6475797999176417550 Face Recognition软件包 这是世界上最简单的人脸识别库了.你可以通过Python引用或者 ...
- linux两种类型服务管理
linux服务分成两个大类 一.rpm包安装 ---------独立的服务 和 基于xinetd服务 二.源代码安装 rpm包安装的服务,查看命令是 chkconfig --list rpm安装 ...
- UNIX历史
一.Multics计划 1965年,AT&T贝尔电话实验室.通用电气公司.麻省理工学院MAC课题组一起联合开发一个称为Multics的新操作系统. Multics 系统的目标是要向大的用户团体 ...
- OnClick,OnClientClick和OnServerClick的区别
OnClientClick是客户端事件处理方法,一般采用JavaScript来进行处理,也就是直接在IE端运行,一点击就运行 OnClick是服务器端事件处理方法,在服务器端也就是IIS中运行, ...
- 英语笔记-some words about description of girl
what did you learn from your last class?20:09:07abc360.Draven/PHH-HA04 ☠ 2018/4/9 20:09:07 poop20:1 ...
- MIPSsim使用说明
MIPSsim下载:https://files.cnblogs.com/files/jiangxinnju/MIPSsim.zip 启动模拟器 双击MIPSsim.exe,即可启动该模拟器.MIPSs ...
- 自动化持续集成Jenkins
自动化持续集成Jenkins 使用Jenkins配置自动化构建http://blog.csdn.net/littlechang/article/details/8642149 Jenkins入门总结h ...