Redis计算地理位置距离-GeoHash
Redis 在 3.2 版本以后增加了地理位置 GEO 模块,意味着我们可以使用 Redis 来实现摩拜单车「附近的 Mobike」、美团和饿了么「附近的餐馆」这样的功能了。
地图元素的位置数据使用二维的经纬度表示,经度范围 (-180, 180],纬度范围 (-90, 90],纬度正负以赤道为界,北正南负,经度正负以本初子午线 (英国格林尼治天文台) 为 界,东正西负。比如掘金办公室在望京 SOHO,它的经纬度坐标是 (116.48105,39.996794), 都是正数,因为中国位于东北半球。
当两个元素的距离不是很远时,可以直接使用勾股定理就能算得元素之间的距离。我们 平时使用的「附近的人」的功能,元素距离都不是很大,勾股定理算距离足矣。不过需要注 意的是,经纬度坐标的密度不一样 (经度总共 360 度,纬度总共 180 度)
效经度为-180至180度。
有效纬度为-85.05112878至85.05112878度。
勾股定律计算平 方差时之后再求和时,需要按一定的系数比加权求和。
现在,如果要计算「附近的人」,也就是给定一个元素的坐标,然后计算这个坐标附近的其它元素,按照距离进行排序,该如何下手?
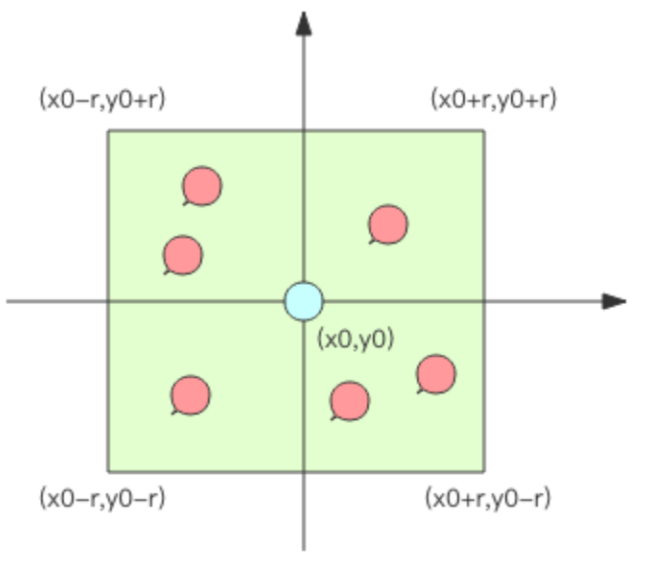
如果现在元素的经纬度坐标使用关系数据库 (元素 id, 经度 x, 纬度 y) 存储,你该如何 计算?
GeoHash 算法
Redis 的 GEO 特性将在 Redis 3.2 版本释出, 这个功能可以将用户给定的地理位置信息储存起来, 并对这些信息进行操作
将指定的地理空间项目(纬度,经度,名称)添加到指定的键。数据作为排序集存储到密钥中,使得可以使用GEORADIUS或GEORADIUSBYMEMBER命令使用半径查询稍后检索项目。
注意:没有GEODEL命令,可以使用ZREM来删除元素。地理索引结构只是一个排序集。
zrem company juejin //company相当于一个地理存储空间, juejin是一个地名
Redis GEO实现主要包含了以下两项技术:
1、使用geohash保存地理位置的坐标。
2、使用有序集合(zset)保存地理位置的集合。
简单操作
添加
geoadd 指令携带集合名称以及多个经纬度名称三元组,注意这里可以加入多个三元组
127.0.0.1:> geoadd company 116.48105 39.996794 juejin (integer)
127.0.0.1:> geoadd company 116.514203 39.905409 ireader (integer)
127.0.0.1:> geoadd company 116.489033 40.007669 meituan
(integer)
127.0.0.1:> geoadd company 116.562108 39.787602 jd 116.334255 40.027400 xiaomi (integer)
计算距离
geodist 指令可以用来计算两个元素之间的距离,携带集合名称、 个名称和距离单位。
127.0.0.1:> geodist company juejin ireader km "10.5501"
127.0.0.1:> geodist company juejin meituan km "1.3878"
127.0.0.1:> geodist company juejin jd km "24.2739"
127.0.0.1:> geodist company juejin xiaomi km "12.9606"
127.0.0.1:> geodist company juejin juejin km "0.0000"
我们可以看到掘金离美团最近,因为它们都在望京。距离单位可以是 m、km、ml、ft, 分别代表米、千米、英里和尺。
获取元素位置
127.0.0.1:> geopos company juejin
) ) "116.48104995489120483"
) "39.99679348858259686"
127.0.0.1:> geopos company ireader
) ) "116.5142020583152771"
) "39.90540918662494363"
127.0.0.1:> geopos company juejin ireader
) ) "116.48104995489120483"
) "39.99679348858259686"
) ) "116.5142020583152771"
) "39.90540918662494363"
我们观察到获取的经纬度坐标和 geoadd 进去的坐标有轻微的误差,原因是 geohash 对 二维坐标进行的一维映射是有损的,通过映射再还原回来的值会出现较小的差别。对于「附 近的人」这种功能来说,这点误差根本不是事。
获取元素的 hash 值
geohash 可以获取元素的经纬度编码字符串,上面已经提到,它是 base32 编码。 你可 以使用这个编码值去 http://geohash.org/${hash}中进行直接定位,它是 geohash 的标准编码 值。
127.0.0.1:> geohash company ireader
) "wx4g52e1ce0"
127.0.0.1:> geohash company juejin
) "wx4gd94yjn0"
geohash的思想是将二维的经纬度转换成一维的字符串,geohash有以下三个特点:
1、字符串越长,表示的范围越精确。编码长度为8时,精度在19米左右,而当编码长度为9时,精度在2米左右。
2、字符串相似的表示距离相近,利用字符串的前缀匹配,可以查询附近的地理位置。这样就实现了快速查询某个坐标附近的地理位置。
3、geohash计算的字符串,可以反向解码出原来的经纬度。
可以打开网站查看地理位置是否正确 http://geohash.org/wx4g52e1ce0
附近的公司
georadiusbymember 指令是最为关键的指令,它可以用来查询指定元素附近的其它元 素,它的参数非常复杂。
# 范围 公里以内最多 个元素按距离正排,它不会排除自身
127.0.0.1:> georadiusbymember company ireader km count asc
) "ireader"
) "juejin"
) "meituan"
# 范围 公里以内最多 个元素按距离倒排
127.0.0.1:> georadiusbymember company ireader km count desc
) "jd"
) "meituan"
) "juejin"
# 三个可选参数 withcoord withdist withhash 用来携带附加参数
# withdist 很有用,它可以用来显示距离
127.0.0.1:> georadiusbymember company ireader km withcoord withdist withhash count asc
) ) "ireader"
) "0.0000"
) (integer)
) ) "116.5142020583152771"
) "39.90540918662494363"
) ) "ireaderexit"
) "0.0000"
) (integer)
) ) "116.5142020583152771"
) "39.90540918662494363"
) ) "meituan"
) "11.5748"
) (integer)
) ) "116.48903220891952515"
) "40.00766997707732031"
除了 georadiusbymember 指令根据元素查询附近的元素,Redis 还提供了根据坐标值来 查询附近的元素,这个指令更加有用,它可以根据用户的定位来计算「附近的车」,「附近 的餐馆」等。它的参数和 georadiusbymember 基本一致,除了将目标元素改成经纬度坐标 值。
127.0.0.1:> georadius company 116.514202 39.905409 km withdist count asc
) ) "ireader"
) "0.0000"
) ) "ireaderexit"
) "0.0000"
) ) "meituan"
) "11.5748"
在一个地图应用中,车的数据、餐馆的数据、人的数据可能会有百万千万条,如果使用Redis 的 Geo 数据结构,它们将全部放在一个 zset 集合中。在 Redis 的集群环境中,集合 可能会从一个节点迁移到另一个节点,如果单个 key 的数据过大,会对集群的迁移工作造成 较大的影响,在集群环境中单个 key 对应的数据量不宜超过 1M,否则会导致集群迁移出现 卡顿现象,影响线上服务的正常运行。
所以,这里建议 Geo 的数据使用单独的 Redis 实例部署,不使用集群环境。
如果数据量过亿甚至更大,就需要对 Geo 数据进行拆分,按国家拆分、按省拆分,按 市拆分,在人口特大城市甚至可以按区拆分。这样就可以显著降低单个 zset 集合的大小。
不错的文章
https://blog.csdn.net/weixin_36135773/article/details/78800215
Redis计算地理位置距离-GeoHash的更多相关文章
- LBS地理位置距离计算方法之geohash算法
随着移动终端的普及,很多应用都基于LBS功能,附近的某某(餐馆.银行.妹纸等等).基础数据中,一般保存了目标位置的经纬度:利用用户提供的经纬度,进行对比,从而获得是否在附近.这里需要在设置出一个字段, ...
- redis GEO地理位置命令介绍
GEOADD keylongitude latitude member [longitude latitude member ...] Available since 3.2.0. Time comp ...
- 计算两点距离 ios
//计算两点距离 -(float)distanceBetweenTwoPoint:(CGPoint)point1 point2:(CGPoint)point2 { ) + powf(point1.y ...
- 【百度地图API】如何根据摩卡托坐标进行POI查询,和计算两点距离
原文:[百度地图API]如何根据摩卡托坐标进行POI查询,和计算两点距离 摘要: 百度地图API有两种坐标系,一种是百度经纬度,一种是摩卡托坐标系.在本章你将学会: 1.如何相互转换这两种坐标: 2. ...
- js计算元素距离顶部的高度及元素是否在可视区判断
前言: 在业务当中,我们经常要计算元素的大小和元素在页面的位置信息.比如说,在一个滚动区域内,我要知道元素A是在可视区内,还是在隐藏内容区(滚动到外边看不到了).有时还要进一步知道,元素是全部都显示在 ...
- Spark Java API 计算 Levenshtein 距离
Spark Java API 计算 Levenshtein 距离 在上一篇文章中,完成了Spark开发环境的搭建,最终的目标是对用户昵称信息做聚类分析,找出违规的昵称.聚类分析需要一个距离,用来衡量两 ...
- 微信小程序计算经纬距离
微信小程序计算经纬距离 微信小程序计算两点间的距离 getDistance: function (lat1, lng1, lat2, lng2) { lat1 = lat1 || 0; lng1 = ...
- C#实现根据地图上的两点坐标,计算直线距离
根据地图上的两点坐标,计算直线距离,在网上找到javascript的写法,用C#实现一下 /// <summary> /// 根据地图上的两点坐标,计算直线距离 /// </summ ...
- numpy计算路线距离
numpy计算路线距离 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 enumerate遍历数组 np.diff函数 numpy适用数组作为索引 标记路线上的点 \[X={X1,X ...
随机推荐
- Java 构造函数(抽象类中的构造函数) 和 加载
博客分类: 面向对象设计的原则 与 概念 1. Java 的构造函数 与初始化块: a. 抽象类的构造函数 若果在父类中(也就是抽象类)中显示的写了有参数的构造函数,在子类是就必须写一个构造函数来 ...
- POJ-1958 Strange Towers of Hanoi(线性动规)
Strange Towers of Hanoi Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 2677 Accepted: 17 ...
- TOP100summit:【分享实录】链家网大数据平台体系构建历程
本篇文章内容来自2016年TOP100summit 链家网大数据部资深研发架构师李小龙的案例分享. 编辑:Cynthia 李小龙:链家网大数据部资深研发架构师,负责大数据工具平台化相关的工作.专注于数 ...
- HDU 1565 - 方格取数(1) - [状压DP][网络流 - 最大点权独立集和最小点权覆盖集]
题目链接:https://cn.vjudge.net/problem/HDU-1565 Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 32 ...
- JavaScript学习11.30
window.history:包含浏览器的历史,可以不时用window这个前缀history.back():加载历史列表的前一个URLhistory.forward():加载历史列表的后一个URLwi ...
- HashMap 的工作原理及代码实现,什么时候用到红黑树
HashMap工作原理及什么时候用到的红黑树: 在jdk 1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里.但是当位于一个桶中的元素较多,即has ...
- 如何控制dedecms描述的长度?
我们都知道调用dedecms的标题长度可以用titlelen='字符数',{dede:arclist titlelen='10'},表示标题长度为10个字符,也即是5个汉字.如果想要控制描述的调用长度 ...
- JavaScript中通过arguments对象实现对象的重载
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- android 数据存储<一>----android短信发送器之文件的读写(手机+SD卡)
本文实践知识点有有三: 1.布局文件,android布局有相对布局.线性布局,绝对布局.表格布局.标签布局等,各个布局能够嵌套的. 本文的布局文件就是线性布局的嵌套 <LinearLayout ...
- JS DOM节点
html代码: <body onload ="loaded12()"> <form name="form1" action="htt ...