关于LSTM的输入和训练过程的理解
1.训练的话一般一批一批训练,即让batch_size 个样本同时训练;
2.每个样本又包含从该样本往后的连续seq_len个样本(如seq_len=15),seq_len也就是LSTM中cell的个数;
3.每个样本又包含inpute_dim个维度的特征(如input_dim=7)
因此,输入层的输入数据通常先要reshape:
x= np.reshape(x, (batch_size , seq_len, input_dim))
(友情提示:每个cell共享参数!!!)
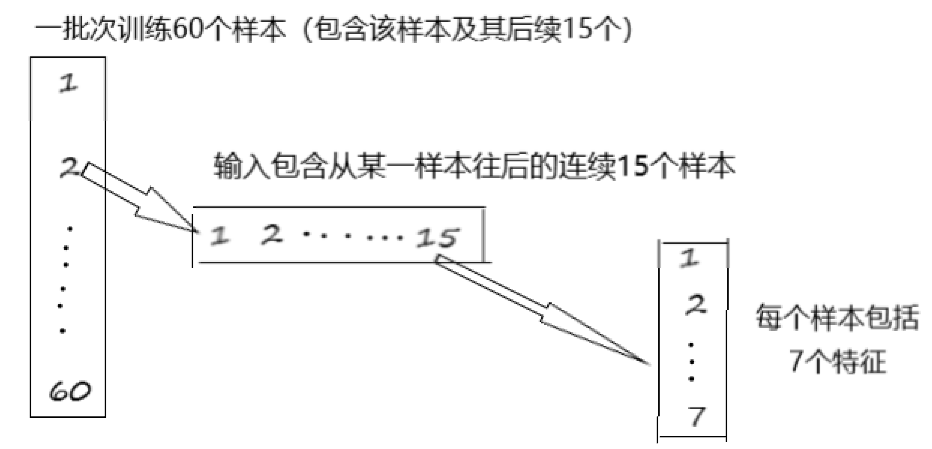
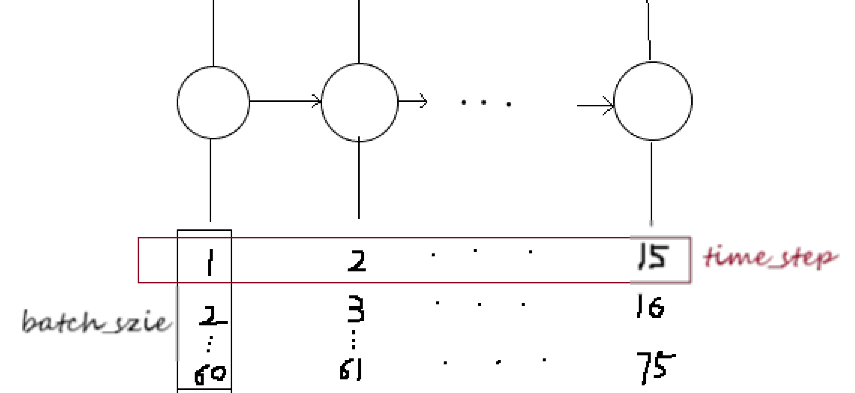
举个例子:
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
import numpy as np
#在这里做数据加载,还是使用那个MNIST的数据,以one_hot的方式加载数据,记得目录可以改成之前已经下载完成的目录
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True) '''
MNIST的数据是一个28*28的图像,这里RNN测试,把他看成一行行的序列(28维度(28长的sequence)*28行)
''' # RNN学习时使用的参数
learning_rate = 0.001
training_iters = 100000
batch_size = 128
display_step = 10 # 神经网络的参数
n_input = 28 # 输入层的n
n_steps = 28 # 28长度
n_hidden = 128 # 隐含层的特征数
n_classes = 10 # 输出的数量,因为是分类问题,0~9个数字,这里一共有10个 # 构建tensorflow的输入X的placeholder
x = tf.placeholder("float", [None, n_steps, n_input])
# tensorflow里的LSTM需要两倍于n_hidden的长度的状态,一个state和一个cell
# Tensorflow LSTM cell requires 2x n_hidden length (state & cell)
istate = tf.placeholder("float", [None, 2 * n_hidden])
# 输出Y
y = tf.placeholder("float", [None, n_classes]) # 随机初始化每一层的权值和偏置
weights = {
'hidden': tf.Variable(tf.random_normal([n_input, n_hidden])), # Hidden layer weights
'out': tf.Variable(tf.random_normal([n_hidden, n_classes]))
}
biases = {
'hidden': tf.Variable(tf.random_normal([n_hidden])),
'out': tf.Variable(tf.random_normal([n_classes]))
} '''
构建RNN
'''
def RNN(_X, _istate, _weights, _biases):
# 规整输入的数据
_X = tf.transpose(_X, [1, 0, 2]) # permute n_steps and batch_size _X = tf.reshape(_X, [-1, n_input]) # (n_steps*batch_size, n_input)
# 输入层到隐含层,第一次是直接运算
_X = tf.matmul(_X, _weights['hidden']) + _biases['hidden']
# 之后使用LSTM
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(n_hidden, forget_bias=1.0)
# 28长度的sequence,所以是需要分解位28次
_X = tf.split(0, n_steps, _X) # n_steps * (batch_size, n_hidden)
# 开始跑RNN那部分
outputs, states = tf.nn.rnn(lstm_cell, _X, initial_state=_istate) # 输出层
return tf.matmul(outputs[-1], _weights['out']) + _biases['out'] pred = RNN(x, istate, weights, biases) # 定义损失和优化方法,其中算是为softmax交叉熵,优化方法为Adam
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y)) # Softmax loss
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) # Adam Optimizer # 进行模型的评估,argmax是取出取值最大的那一个的标签作为输出
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) # 初始化
init = tf.initialize_all_variables() # 开始运行
with tf.Session() as sess:
sess.run(init)
step = 1
# 持续迭代
while step * batch_size < training_iters:
# 随机抽出这一次迭代训练时用的数据
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# 对数据进行处理,使得其符合输入
batch_xs = batch_xs.reshape((batch_size, n_steps, n_input))
# 迭代
sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys,
istate: np.zeros((batch_size, 2 * n_hidden))})
# 在特定的迭代回合进行数据的输出
if step % display_step == 0:
# Calculate batch accuracy
acc = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys,
istate: np.zeros((batch_size, 2 * n_hidden))})
# Calculate batch loss
loss = sess.run(cost, feed_dict={x: batch_xs, y: batch_ys,
istate: np.zeros((batch_size, 2 * n_hidden))})
print "Iter " + str(step * batch_size) + ", Minibatch Loss= " + "{:.6f}".format(loss) + \
", Training Accuracy= " + "{:.5f}".format(acc)
step += 1
print "Optimization Finished!"
# 载入测试集进行测试
test_len = 256
test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input))
test_label = mnist.test.labels[:test_len]
print "Testing Accuracy:", sess.run(accuracy, feed_dict={x: test_data, y: test_label,
istate: np.zeros((test_len, 2 * n_hidden))}
关于LSTM的输入和训练过程的理解的更多相关文章
- (原)torch的训练过程
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/6221622.html 参考网址: http://ju.outofmemory.cn/entry/284 ...
- 深度残差网(deep residual networks)的训练过程
这里介绍一种深度残差网(deep residual networks)的训练过程: 1.通过下面的地址下载基于python的训练代码: https://github.com/dnlcrl/deep-r ...
- mxnet的训练过程——从python到C++
mxnet的训练过程--从python到C++ mxnet(github-mxnet)的python接口相当完善,我们可以完全不看C++的代码就能直接训练模型,如果我们要学习它的C++的代码,从pyt ...
- 09 使用Tensorboard查看训练过程
打开Python Shell,执行以下代码: import tensorflow as tf import numpy as np #输入数据 x_data = np.linspace(-1,1,30 ...
- 深度学习基础(CNN详解以及训练过程1)
深度学习是一个框架,包含多个重要算法: Convolutional Neural Networks(CNN)卷积神经网络 AutoEncoder自动编码器 Sparse Coding稀疏编码 Rest ...
- 如何打开tensorboard观测训练过程
TensorBoard是TensorFlow下的一个可视化的工具,能够帮助研究者们可视化训练大规模神经网络过程中出现的复杂且不好理解的运算,展示训练过程中绘制的图像.网络结构等. 最近本人在学习这方面 ...
- TensorFlow之tf.nn.dropout():防止模型训练过程中的过拟合问题
一:适用范围: tf.nn.dropout是TensorFlow里面为了防止或减轻过拟合而使用的函数,它一般用在全连接层 二:原理: dropout就是在不同的训练过程中随机扔掉一部分神经元.也就是让 ...
- tensorflow笔记:模型的保存与训练过程可视化
tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) tensorflow笔记:多层CNN代码分析 (三) tensorflow笔记:多层LSTM代码分析 ...
- 深度学习笔记之关于基本思想、浅层学习、Neural Network和训练过程(三)
不多说,直接上干货! 五.Deep Learning的基本思想 假设我们有一个系统S,它有n层(S1,…Sn),它的输入是I,输出是O,形象地表示为: I =>S1=>S2=>….. ...
随机推荐
- postgresql sql查询结果添加序号列与每组第一个序号应用
1.postgresql 查询每组第一个 ROW_NUMBER () OVER (partition by 字段 ORDER BY 字段 DESC) 写法:SELECT ROW_NUMBER ( ...
- Luogu 4751 动态DP 模板
题面 动态求最大独立集 题解 树剖后用矩阵转移. 具体见Tweetuzki的洛谷博客 CODE #include <bits/stdc++.h> using namespace std; ...
- Connecting Graph
Given n nodes in a graph labeled from 1 to n. There is no edges in the graph at beginning. You need ...
- python 操作excle 之第三方库 openpyxl学习
目录 python 操作excle 之第三方库 openpyxl学习 安装 pip install openpyxl 英文文档链接 : 点击这里~ 1,定位excel 2,读取excle中的内容 3, ...
- webstorm中不能识别react、vue alias 路径别名符号
https://blog.csdn.net/weixin_37939942/article/details/89388466 因为我平时比较喜欢使用ws做开发,所以在使用vue或react的时候只要使 ...
- 学到了林海峰,武沛齐讲的Day23-完
10月11号生了儿子,很高心..不好的是孩子住院了,14号出院,晚上外公去世了,15号赶回老家.....20号回贵阳,21号回公司办事....我要坚定的学习下去...以前几乎是卡在这里就学不下去了.加 ...
- chrome 截取整个网页
- @ControllerAdvice 和 @ExceptionHandler
@ExceptionHandler的作用是把对不同异常处理抽取到不同的方法中. @ControllerAdvice的作用是把控制器中 @ExceptionHandler.@InitBinder.@Mo ...
- FLUENT导入CHEMKIN机理的单位问题【转载】
转载自:http://blog.sina.com.cn/s/blog_4a0a8b5d0101pj3c.html CHEMKIN机理导入后,发现速率常数全变了,那么他们是怎样变化的呢? FLUENT中 ...
- [插件式开发][C#]
Demo 下载 参考文章:https://www.cnblogs.com/hippieZhou/p/9398354.html 技术方面要使用到 依赖注入,可以参考此示例逐步学习:https://git ...