【Python爬虫学习笔记(2)】正则表达式(re模块)相关知识点总结
1. 正则表达式
正则表达式是可以匹配文本片段的模式。
1.1 通配符
正则表达式能够匹配对于一个的字符串,可以使用特殊字符创建这类模式。(图片来自cnblogs)
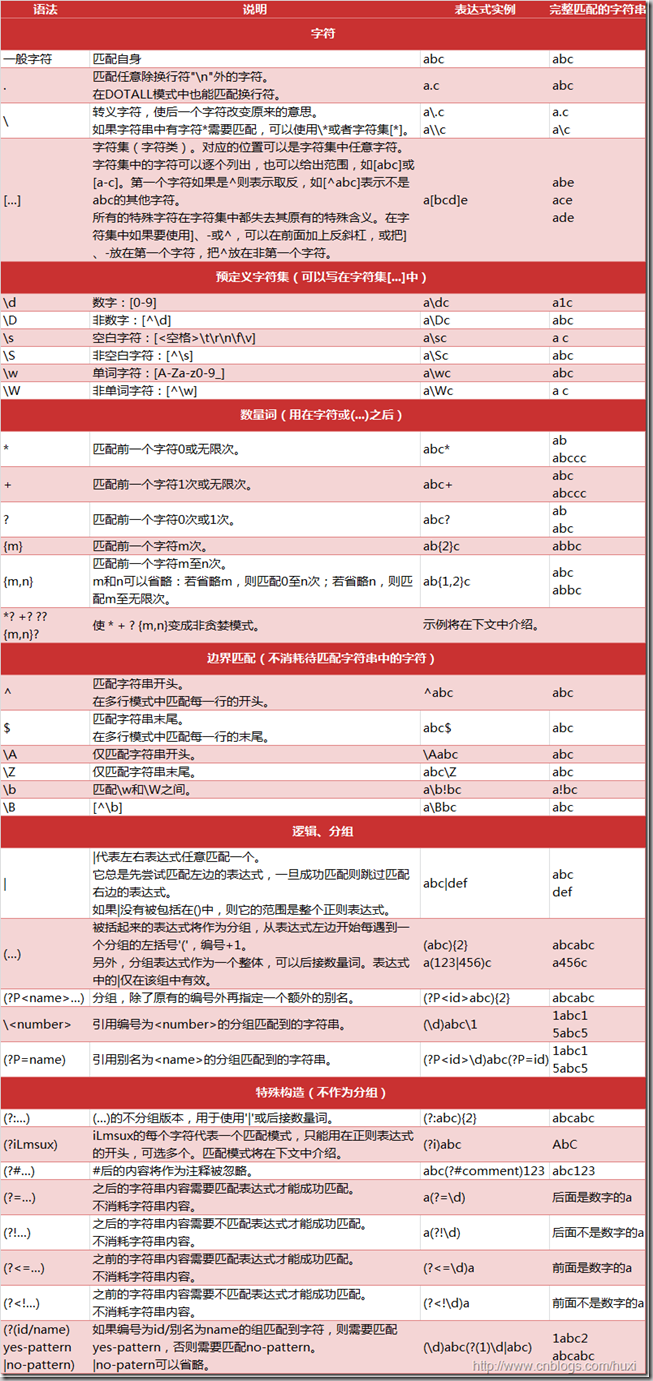
1.2 特殊字符的转义
由于在正则表达式中,有时需要将特殊字符作为普通字符处理,就需要用‘\’进行转义,例如‘python\\.org’就会匹配‘python.org’,那么为什么要用两个反斜杠呢,原因在于需要进行两层转义,首先是re模块表示正则表达式中需要转义一次,其次是python解释器即python的语法还要求再转义一次。也是因为这个原因,对于‘\’需要‘\\\\’来匹配。为了表示的简介性,可以使用原始字符串来处理,则上面两例分别可以写为r‘python\.org’和r‘\\’。
1.3 字符集
举例说明,例如‘[pj]python’可以匹配‘python’和‘jpython’,[a-zA-Z0-9]可以匹配任意一个大小写字母和数字(注意:是一个)。为了反转字符集,可以将‘^’放在字符串的开头,例如‘[^abc]’可以匹配除a,b,c以为的任意字符。
注意:如果希望‘.’,‘*’,‘?’这些特殊字符用作文本字符,则需‘\’进行转义,但是在字符集中无必要,尽管是合法的(因为可以调整顺序来解决)。记住以下两个规则:
a. 如果‘^’出现在字符集的开头则需要转义,除非希望用作字符集反转。
b. 右中括号‘]’和横线‘-’要么放在字符集开头,要么转义。
1.4 选择符和子模块
如果只想匹配‘python’和‘perl’,则可以用选择运算符管道符号‘|’,模式可写为‘python|perl’
如果不需要对整个模式使用选择运算符,而只需要一部分,可以用括号括起需要的部分,对于上例,表示为‘p(ython|erl)’。括号括起部分称为子模块(subpattren)。
1.5 可选项和重复子模块
在子模块后面加上问号,就变成了可选项。
(pattern)?:允许模式出现0次或者1次。
(pattern)+:允许模式出现1次或者多次。
(pattern)*:允许模式出现0次或者多次。
(pattern){m,n}:允许模式出现m~n次。
1.6 字符串的开始和结尾
举例说明,‘www.python.org’和‘python.www.org’中的子字符串‘www’能匹配模式‘w+’,但是只希望‘www.python.org’能匹配,则模式可用‘^w+’表示,如果希望‘python.org.www’中的子字符串‘www’能匹配‘w+’,则模式需写为‘$w+’。
2. re模块的函数
2.1 .compile
将正则表达式转换为模式对象,实现更有效率的匹配。
import re
pattern = re.compile('(^w+)\.python\.org')
2.2 .search(重要)
在给定字符串中寻找第一个匹配给定正则表达式的子字符串,如果找到会返回一个MatchObject对象,这个对象中的元素可以.group()得到(之后将会介绍group的概念),如果没找到就会返回None。
可以先判断是否找到再取元素,假设例子中的pattern有两个组,返回第一个组。
have_character = re.search(pattern,text)
if not have_character:
return have_character.group(1)
2.3 .match
在给定字符串的开始处匹配正则表达式,例如re.match(‘p’,‘python’)返回为对象MatchObject,即匹配成功,如果要匹配整个字符串,则可以在模式最后加上‘$’符号(代表结尾也匹配)。
2.4 .split
根据模式匹配项来分割字符串。类似于字符串的split方法,但是可用正则表达式来带起固定的分隔符字符串,例如允许用任意长度的逗号和空格序列来分割字符串。
text = 'a, b,,,,c d'
re.split('[, ]+', text)
#['a', 'b', 'c', 'd']
参数maxsplit可以设定最多的分割次数。
text = 'a, b,,,,c d'
re.split('[, ]+', text, maxsplit=2)
#['a', 'b', 'c d']
2.5 .findall(重要)
该方法以列表的形式返回所有的匹配项。
pattern = 'a(b+?)c(d+?)e'
items = re.findall(pattern, 'abbcddeabbbcddde')
print items
#items = [('bb', ‘dd’), ('bbb', 'ddd')]
2.6 .sub(pattern, repl, string[, count=0]) (重要)
将字符串中所有pattern的匹配项用repl代替。
pattern = re.compile(r'\*([^\*]+)\*')
re.sub(pattern, r'<em>\1</em>', 'Hello, *world*!')
#'Hello, <em>world</em>!'
在sub函数三个参数中,pattern代表模式,repl代表目标形式,string代表待匹配替换字符串。
替换步骤:
a. 用模式pattern套待匹配替换字符串string。
b. 按照目标形式repl对字符串进行重建(即用目标形式去代替string中与pattern匹配的子字符串)
sub函数强大功能最重要的体现在于可以在替代字符串中使用组号。(具体内容参考链接:http://stackoverflow.com/questions/5984633/python-re-sub-group-number-after-number, http://www.crifan.com/python_re_sub_detailed_introduction/)
re.sub(r'(foo)', r'\g<1>123', 'foobar')
#'foo123bar'
2.7 .escape
如果一个字符串很长且包含很多特殊字符,而不想输入一大堆反斜杠来转义,可以用这个函数对字符串中所有可能被解释为正则运算符的字符进行转义为普通文本字符。
3. 匹配对象和组
re模块的search,match函数在找到匹配项时都会返回一个MatchObject对象,对于这样一个对象m,可以用m.group()来取某组的信息,如果.group()默认组号为0,则返回整个字符串,.group(1)返回与第一个子模式匹配的单个字符串,.group(2)等等以此类推。
.start()方法得到对应组的开始索引,.end()得到对应组的结束索引,.span()以元组形式给出对应组的开始和结束位置,括号中填入组号,不填入组号时默认为0。
4. 贪婪和非贪婪模式
重复运算符在默认条件下是贪婪的。
pattern = r'\*(.+)\*'
re.sub(pattern, r'<em>\1</em>', '*This* is *it*!')
#'<em>This* is *it</em>'
可见贪婪模式匹配了开始星号到结束星号间的全部内容,包括中间两个星号。
用(.+?)代替(.+)得到非贪婪模式,它会匹配尽可能少的内容。
pattern = r'\*(.+?)\*'
re.sub(pattern, r'<em>\1</em>', '*This* is *it*!')
#'<em>This</em> is <em>it</em>'
参考资料:
《Beginning Python From Novice to Professional》
https://docs.python.org/2.7/library/re.html
转载请注明:
http://www.cnblogs.com/wuwenyan/p/4771422.html
【Python爬虫学习笔记(2)】正则表达式(re模块)相关知识点总结的更多相关文章
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- Python爬虫学习笔记(三)
Cookies: 以抓取https://www.yaozh.com/为例 Test1(不使用cookies): 代码: import urllib.request # 1.添加URL url = &q ...
- 【Python】学习笔记十二:模块
模块(module) 在Python中,一个.py文件就是一个模块.通过模块,你可以调用其它文件中的程序 引入模块 先写一个first.py文件,内容如下: def letter(): print(' ...
- (转)Python爬虫学习笔记(2):Python正则表达式指南
以下内容转自CNBLOG:http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html 1. 正则表达式基础 1.1. 简单介绍 正则表达式并 ...
- python爬虫学习笔记
爬虫的分类 1.通用爬虫:通用爬虫是搜索引擎(Baidu.Google.Yahoo等)“抓取系统”的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 简单来讲就是尽可 ...
- 一入爬虫深似海,从此游戏是路人!总结我的python爬虫学习笔记!
前言 还记得是大学2年级的时候,偶然之间看到了学长在学习python:我就坐在旁边看他敲着代码,感觉很好奇.感觉很酷,从那之后,我就想和学长一样的厉害,就想让学长教我,请他吃了一周的饭,他答应了.从此 ...
- Python、pip和scrapy的安装——Python爬虫学习笔记1
Python作为爬虫语言非常受欢迎,近期项目需要,很是学习了一番Python,在此记录学习过程:首先因为是初学,而且当时要求很快速的出demo,所以首先想到的是框架,一番查找选用了Python界大名鼎 ...
- Python爬虫学习笔记-1.Urllib库
urllib 是python内置的基本库,提供了一系列用于操作URL的功能,我们可以通过它来做一个简单的爬虫. 0X01 基本使用 简单的爬取一个页面: import urllib2 request ...
- 【Python爬虫学习笔记(3)】Beautiful Soup库相关知识点总结
1. Beautiful Soup简介 Beautiful Soup是将数据从HTML和XML文件中解析出来的一个python库,它能够提供一种符合习惯的方法去遍历搜索和修改解析树,这将大大减 ...
随机推荐
- mysql常见知识点总结
mysql常见知识点总结 参考: http://www.cnblogs.com/hongfei/archive/2012/10/20/2732516.html https://www.cnblogs. ...
- 【eclipse】Multiple annotations found at this line:——解决方法
问题截图: 就是eclipse的maven插件太旧了 用新插件新建的maven项目就没有报错 用软件对比了一下这两个pom文件 只有项目名有区别 所以就是插件的问题 一个简单安装离线maven插件的方 ...
- Outlook 配置qq邮箱账号
最近想用Outlook 2013管理QQ邮件,配置好久都没有成功,结果最后发现第三方登陆QQ邮箱不使用QQ密码,而是使用一个叫”授权码”的东西.(用户名自动生成的,授权码就填这,报错后填会测试不通过) ...
- 转 tensorflow模型保存 与 加载
使用tensorflow过程中,训练结束后我们需要用到模型文件.有时候,我们可能也需要用到别人训练好的模型,并在这个基础上再次训练.这时候我们需要掌握如何操作这些模型数据.看完本文,相信你一定会有收获 ...
- 最简js深浅拷贝说明
1.浅拷贝 浅拷贝是拷贝引用,拷贝后的引用都是指向同一个对象的实例,彼此之间的操作会互相影响. 浅拷贝分两种情况: 1.直接拷贝源对象的引用 2. 源对象拷贝实例,但其属性对象(类型为Object, ...
- filter-mapping中的dispatcher使用
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAABGAAAAEJCAIAAABUr8bLAAAgAElEQVR4nO3dX2/bVoL3cb4h+WYnwN
- Python flask网站部署总结
先开一贴,有空来总结下前段时间的网站部署情况.此次部署采用Gunicorn + Nginx + supervisor的组合在VPS环境中部署flask网站应用. Ubuntu环境准备 准备python ...
- my.cnf 参数说明
[mysql] prompt="\\u@\\h:\p \\R:\\m:\\s [\\d]>" The prompt command reconfigures the de ...
- 详解offset
offset offset 译为“偏移量”,是javascript很重要的一个概念.涉及到便宜量的主要有offsetLeft.offsetTop.offHeight.offsetWidth这四个属性还 ...
- 浅谈js数据类型识别方法
js有6种基本数据类型 Undefined , Null , Boolean , Number , String ,Symbol和一种引用类型Object,下面我们就来一一看穿,哦不,识别他们. t ...