spring-cloud-sleuth+zipkin追踪服务实现(二)
1. 简述
在上一节《spring-cloud-sleuth+zipkin追踪服务实现(一)》中,我们使用microservice-zipkin-server、microservice-zipkin-client、microservice-zipkin-client-backend 三个程序实现了使用http方式进行通信,数据持久化到内存中的服务调用链路追踪实现。
在这里我们做两点改动,首先是数据从保存在内存中改为持久化到数据库,其次是将http通信改为mq异步方式通信。
我们还是使用之前上一节中的三个程序做修改,方便大家看到对比不同点。这里每个项目名都加了一个stream,用来表示区别。
2、microservice-zipkin-stream-server
要将http方式改为通过MQ通信,我们要将依赖的原来依赖的io.zipkin.java:zipkin-server换成spring-cloud-sleuth-zipkin-stream和spring-cloud-starter-stream-rabbit
同时要使用mysql持久化,我们需要添加mysql相关依赖。
全部maven依赖如下:
```
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--zipkin依赖-->
<!--此依赖会自动引入spring-cloud-sleuth-stream并且引入zipkin的依赖包-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<scope>runtime</scope>
</dependency>
<!--保存到数据库需要如下依赖-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
```
添加以上maven依赖后,我们将启动类ZipkinServer中@EnableZipkinServer注解替换成@EnableZipkinStreamServer,
具体如下:
package com.yangyang.cloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer;
/**
* Created by chenshunyang on 2017/5/24.
*/
@EnableZipkinStreamServer// //使用Stream方式启动ZipkinServer
@SpringBootApplication
public class ZipkinStreamServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinStreamServerApplication.class,args);
}
}
点击@EnableZipkinStreamServer注解的源码我们可以看到它也引入了@EnableZipkinServer注解,同时还创建了一个rabbit-mq的消息队列监听器。
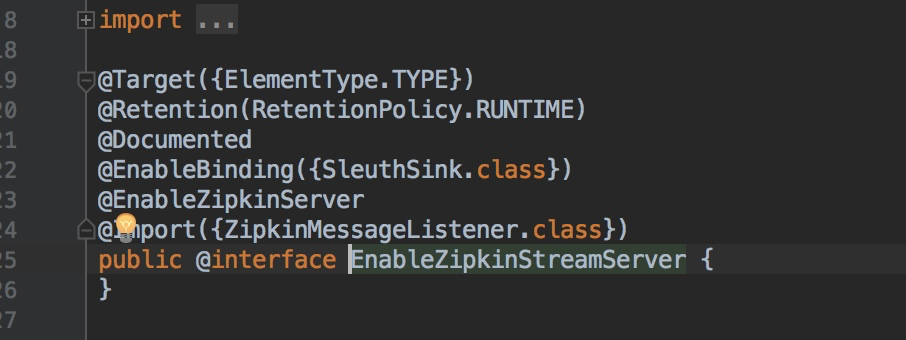
以方便接收从消息客户端收集发过来的mq消息。
由于使用了消息中间件rabbit mq以及mysql,所以我们还需要在配置文件application.properties加入相关的配置:
server.port=11020
spring.application.name=microservice-zipkin-stream-server
#zipkin数据保存到数据库中需要进行如下配置
#表示当前程序不使用sleuth
spring.sleuth.enabled=false
#表示zipkin数据存储方式是mysql
zipkin.storage.type=mysql
#数据库脚本创建地址,当有多个是可使用[x]表示集合第几个元素
spring.datasource.schema[0]=classpath:/zipkin.sql
#spring boot数据源配置
spring.datasource.url=jdbc:mysql://localhost:3306/zipkin?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.initialize=true
spring.datasource.continue-on-error=true
#rabbitmq配置
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
其中zipkin.sql直接到官网去拷贝,也可以从本demo中拷贝
为了避免http通信的干扰,我们将原来的监听端口有11008更改为11020,启动程序,未报错且能够看到rabbit连接日志,说明程序启动成功。
3.microservice-zipkin-stream-client、microservice-zipkin-client-stream-backend
与上一节中的配置一样,客户端的配置也非常简单,maven依赖只需要将原来的spring-cloud-starter-zipkin替换为如下两个依赖即可
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
此外,在配置文件中也加上连接MQ的配置
server:
port: 11021
spring:
application:
name: microservice-zipkin-stream-client
#rabbitmq配置
rabbitmq:
host: 127.0.0.1
port : 5672
username: guest
password: guest
当然为了以示区别,端口也做了相应的调整
4.测试
按照上一节的方式访问:http://localhost:11021/call/1,我们可以上一节,说明rabbit-mq方式通信的sleuth功能已经生效了。
我们多次访问consumer的地址可以看到日志中,请求的耗时时间不会再次出现突然耗时特长的情况。
为了体验MQ通信给我们带来的数据不丢失的特点,我们将数据库中的数据清空,然后刷新zipkin server的界面,可以看到不再有数据
然后我们将zipkin-server程序想关闭,然后再多次访问consumer的地址,之后,我们重启zipkin server程序,启动成功后访问UI界面
很快看到Span Name选项有数据可以选择了,同时数据库中的记录条数也不再是之前的0条了
如此说明我们的zipkin重启后,从MQ中成功获取出了在关闭这段时间里provider和consumer产生的信息数据。这样我们使用spring-cloud-sleuth-stream+zipkin方式的rest服务调用追踪功能就OK了。
5.项目源码:
https://git.oschina.net/shunyang/spring-cloud-microservice-study.git
https://github.com/shunyang/spring-cloud-microservice-study.git
6.参考文档:
spring cloud 官方文档:https://github.com/spring-cloud/spring-cloud-sleuth
spring-cloud-sleuth+zipkin追踪服务实现(二)的更多相关文章
- Spring Cloud Sleuth+ZipKin+ELK服务链路追踪(七)
序言 sleuth是spring cloud的分布式跟踪工具,主要记录链路调用数据,本身只支持内存存储,在业务量大的场景下,为拉提升系统性能也可通过http传输数据,也可换做rabbit或者kafka ...
- 分布式链路追踪之Spring Cloud Sleuth+Zipkin最全教程!
大家好,我是不才陈某~ 这是<Spring Cloud 进阶>第九篇文章,往期文章如下: 五十五张图告诉你微服务的灵魂摆渡者Nacos究竟有多强? openFeign夺命连环9问,这谁受得 ...
- Spring Cloud Alibaba学习笔记(23) - 调用链监控工具Spring Cloud Sleuth + Zipkin
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求陷入性能瓶颈或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何 ...
- Spring Cloud Sleuth + Zipkin 链路监控
原文:https://blog.csdn.net/hubo_88/article/details/80878632 在微服务系统中,随着业务的发展,系统会变得越来越大,那么各个服务之间的调用关系也就变 ...
- Spring Cloud 微服务六:调用链跟踪Spring cloud sleuth +zipkin
前言:随着微服务系统的增加,服务之间的调用关系变得会非常复杂,这给运维以及排查问题带来了很大的麻烦,这时服务调用监控就显得非常重要了.spring cloud sleuth实现了对分布式服务的监控解决 ...
- Spring Cloud Sleuth Zipkin - (2)
在上一节<spring-cloud-sleuth+zipkin追踪服务实现(一)>中,我们使用zipkin-server.provider.consumer三个程序实现了使用http方式进 ...
- 【Spring Cloud】Spring Cloud之Spring Cloud Sleuth,分布式服务跟踪(1)
一.Spring Cloud Sleuth组件的作用 为微服务架构增加分布式服务跟踪的能力,对于每个请求,进行全链路调用的跟踪,可以帮助我们快速发现错误根源以及监控分析每条请求链路上的性能瓶颈等. 二 ...
- 阿里高级架构师教你使用Spring Cloud Sleuth跟踪微服务
随着微服务数量不断增长,需要跟踪一个请求从一个微服务到下一个微服务的传播过程,Spring Cloud Sleuth 正是解决这个问题,它在日志中引入唯一ID,以保证微服务调用之间的一致性,这样你就能 ...
- Spring Cloud Sleuth Zipkin - (1)
最近在学习spring cloud构建微服务,很多大牛都提供很多入门的例子帮助我们学习,对于我们这种英语不好的码农来说,效率着实提高不少.这两天学习到追踪微服务rest服务调用链路的问题,接触到zip ...
随机推荐
- oracle中 trunc(),round(),ceil(),floor的使用
oracle中 trunc(),round(),ceil(),floor的使用 原文: http://www.2cto.com/database/201310/248336.html 1.round函 ...
- Spring MVC @RequestParam
案例来说明 @RequestMapping("user/add") public String add(@RequestParam("name") String ...
- linux sort中文失效问题的解决
http://note.youdao.com/noteshare?id=745488efb61a69fb56475e291863c94e
- kendalltau肯德尔和谐系数
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005269003&a ...
- 查看MySQL日志数据binlog文件
binlog介绍 binlog,即二进制日志,它记录了数据库上的所有改变. 改变数据库的SQL语句执行结束时,将在binlog的末尾写入一条记录,同时通知语句解析器,语句执行完毕. binlog格式 ...
- 二叉树系列 - 求两节点的最低公共祖先,例 剑指Offer 50
前言 本篇是对二叉树系列中求最低公共祖先类题目的讨论. 题目 对于给定二叉树,输入两个树节点,求它们的最低公共祖先. 思考:这其实并不单单是一道题目,解题的过程中,要先弄清楚这棵二叉树有没有一些特殊的 ...
- JPA映射持久化对象(Entity)
推荐阅读:JPA criteria 查询:类型安全与面向对象 来源: http://blog.sina.com.cn/s/blog_49fd52cf0100rzjn.html 一个普通的POJO类通过 ...
- 最小割dp Intel Code Challenge Final Round (Div. 1 + Div. 2, Combined) E
http://codeforces.com/contest/724/problem/E 题目大意:有n个城市,每个城市有pi件商品,最多能出售si件商品,对于任意一队城市i,j,其中i<j,可以 ...
- 动态规划:LIS优化
对于1D/1D动态规划来说,理论时间复杂度都是O(n^2)的,这种动态规划一般都可以进行优化,贴一篇文章 https://wenku.baidu.com/view/e317b1020740be1e65 ...
- Spark Core 资源调度与任务调度(standalone client 流程描述)
Spark Core 资源调度与任务调度(standalone client 流程描述) Spark集群启动: 集群启动后,Worker会向Master汇报资源情况(实际上将Worker的资 ...