NodeJS制作爬虫全过程
今天来学习alsotang的爬虫教程,跟着把CNode简单地爬一遍。
建立项目craelr-demo
我们首先建立一个Express项目,然后将app.js的文件内容全部删除,因为我们暂时不需要在Web端展示内容。当然我们也可以在空文件夹下直接 npm install express来使用我们需要的Express功能。
目标网站分析
如图,这是CNode首页一部分div标签,我们就是通过这一系列的id、class来定位我们需要的信息。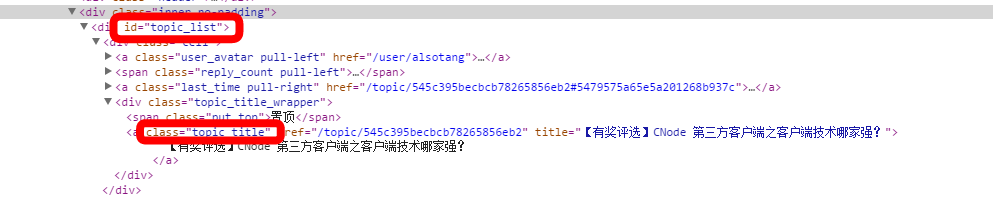
使用superagent获取源数据
superagent就是ajax API来使用的Http库,它的使用方法与jQuery差不多,我们通过它发起get请求,在回调函数中输出结果。
var url = require('url'); //解析操作url
var superagent = require('superagent'); //这三个外部依赖不要忘记npm install
var cheerio = require('cheerio');
var eventproxy = require('eventproxy');
var targetUrl = 'https://cnodejs.org/';
superagent.get(targetUrl)
.end(function (err, res) {
console.log(res);
});
它的res结果为一个包含目标url信息的对象,网站内容主要在其text(string)里。
使用cheerio解析
cheerio充当服务器端的jQuery功能,我们先使用它的.load()来载入HTML,再通过CSS selector来筛选元素。
//通过CSS selector来筛选数据
$('#topic_list .topic_title').each(function (idx, element) {
console.log(element);
});
其结果为一个个对象,调用 .each(function(index, element))函数来遍历每一个对象,返回的是HTML DOM Elements。
输出 console.log($element.attr('title'));的结果为 广州 2014年12月06日 NodeParty 之 UC 场
之类的标题,输出 console.log($element.attr('href'));的结果为 /topic/545c395becbcb78265856eb2之类的url。再用NodeJS1的url.resolve()函数来补全完整的url。
.end(function (err, res) {
if (err) {
return console.error(err);
}
var topicUrls = [];
var $ = cheerio.load(res.text);
// 获取首页所有的链接
$('#topic_list .topic_title').each(function (idx, element) {
var $element = $(element);
var href = url.resolve(tUrl, $element.attr('href'));
console.log(href);
//topicUrls.push(href);
});
});
使用eventproxy来并发抓取每个主题的内容
教程上展示了深度嵌套(串行)方法和计数器方法的例子,eventproxy就是使用事件(并行)方法来解决这个问题。当所有的抓取完成后,eventproxy接收到事件消息自动帮你调用处理函数。
var ep = new eventproxy();
//第二步:定义监听事件的回调函数。
//after方法为重复监听
//params: eventname(String) 事件名,times(Number) 监听次数, callback 回调函数
ep.after('topic_html', topicUrls.length, function(topics){
// topics 是个数组,包含了 40 次 ep.emit('topic_html', pair) 中的那 40 个 pair
//.map
topics = topics.map(function(topicPair){
//use cheerio
var topicUrl = topicPair[0];
var topicHtml = topicPair[1];
var $ = cheerio.load(topicHtml);
return ({
title: $('.topic_full_title').text().trim(),
href: topicUrl,
comment1: $('.reply_content').eq(0).text().trim()
});
});
//outcome
console.log('outcome:');
console.log(topics);
});
//第三步:确定放出事件消息的
topicUrls.forEach(function (topicUrl) {
superagent.get(topicUrl)
.end(function (err, res) {
console.log('fetch ' + topicUrl + ' successful');
ep.emit('topic_html', [topicUrl, res.text]);
});
});
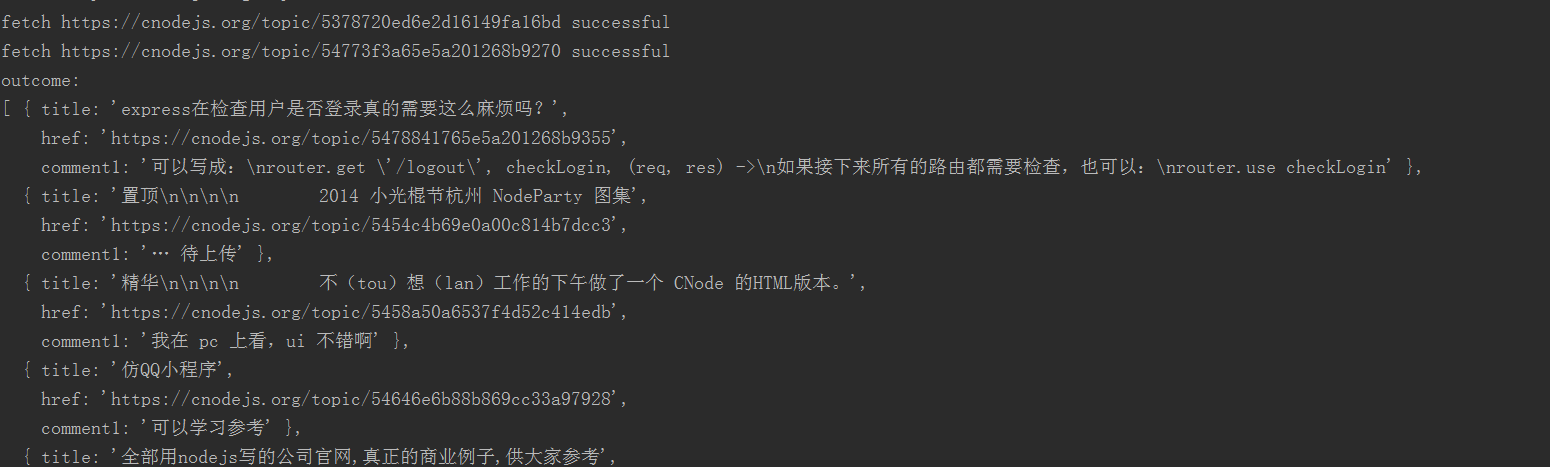
结果如下
扩展练习(挑战)
获取留言用户名和积分
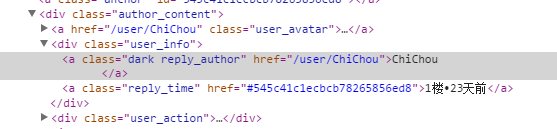
在文章页面的源码找到评论的用户class名,classname为reply_author。console.log第一个元素 $('.reply_author').get(0)可以看到,我们需要获取东西都在这里头。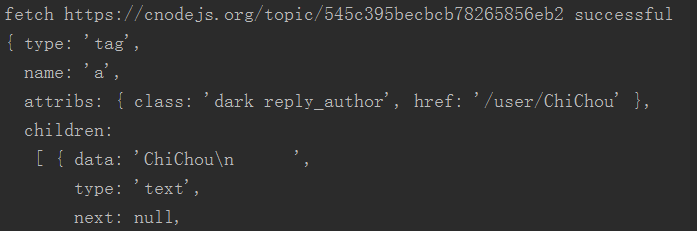
首先,我们先对一篇文章进行抓取,一次性把需要的都得到即可。
console.log(userHref);
console.log($('.reply_author').get(0).children[0].data);
我们可以通过https://cnodejs.org/user/username抓取积分信息
var $element = $(element);
console.log($element.attr('href'));
});
在用户信息页面 $('.big').text().trim()即为积分信息。
使用cheerio的函数.get(0)为获取第一个元素。
console.log(userHref);
这只是对于单个文章的抓取,对于40个还有需要修改的地方。
书接上回,我们需要修改程序以达到连续抓取40个页面的内容。也就是说我们需要输出每篇文章的标题、链接、第一条评论、评论用户和论坛积分。
如图所示,$('.reply_author').eq(0).text().trim();得到的值即为正确的第一条评论的用户。
{<1>}

在eventproxy获取评论及用户名内容后,我们需要通过用户名跳到用户界面继续抓取该用户积分
//此URL为下一步抓取目标URL
var userHref = 'https://cnodejs.org' + $('.reply_author').eq(0).attr('href');
userHref = url.resolve(tUrl, userHref);
var title = $('.topic_full_title').text().trim().replace(/\n/g,"");;
var href = topicUrl;
var comment1 = $('.reply_content').eq(0).text().trim();
var author1 = $('.reply_author').eq(0).text().trim();
//传递参数到下一次并发抓取
ep.emit('user_html', [userHref, title, href, comment1, author1]);
在eventproxy这一次中,我们要找到score是放在哪里(class="big")。
{<2>}

找到classname就好办了,我们先试着把结果输出一下
.end(function (err, res) {
if (err) {
return console.error(err);
}
var $ = cheerio.load(res.text);
var score = $('.big').text().trim();
console.log(user[1]);
console.log(user[2]);
console.log(user[3]);
console.log(user[4]);
console.log($('.big').text().trim());
return ({
title: user[1],
href: user[2],
comment1: user[3],
author1: user[4],
score1: score
});
});
});
运行程序,这段代码得到的结果。
{<3>}

但是问题来了,我们在.end()的回调函数中能正确输出结果,但是不能正确的输出outcome。仔细一看,需要输出的outcome是一个Request对象。这是因为粗心犯的错的,.end()函数并不会传递返回值给Request对象,需要将结果返回到上一层(users)。
ep.after('user_html', topicUrls.length, function(users){
users = users.map(function(user){
var userUrl = user[0];
var score;
superagent.get(userUrl)
.end(function (err, res) {
if (err) {
return console.error(err);
}
//console.log(res.text);
var $ = cheerio.load(res.text);
score = $('.big').text().trim();
});
return ({
title: user[1],
href: user[2],
comment1: user[3],
author1: user[4],
score1: score
});
});
把users好好地输出发现除了score1其他是正确值。仔细调试发现,程序是先进行了console.log(),然后再进行.map()。更准确地说,在.map()函数内,.get()的回调函数并没有执行完赋值score,return 返回值就进行了。这就是回调函数的异步,而外层的同步操作是不会等待回调函数做完操作的。
{<4>}

我的做法就是eventproxy再emit一层消息,伴随着消息把需要的数据一起传递给接收消息操作.after(),只有当消息全部接收完毕,再打印出传递的参数(结果)。
//新添加
ep.emit('got_score', [user[1], user[2], user[3], user[4], score]);
.....
ep.after('got_score', 10, function(users){
console.log(users);
});
{<6>}
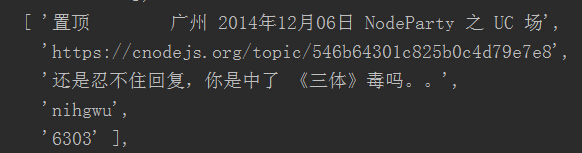
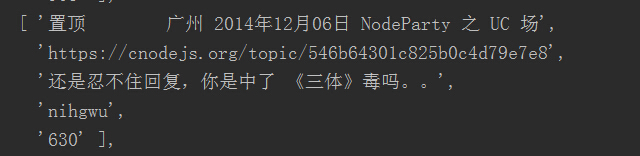
这个问题解决了,但score1的数值好像太大了点吧。再一看,原来class='big'有两个,用户的话题收藏也是属于这个class。我们得通过cheerio的.slice( start, [end] )来切取第一个元素,即将score 修改为 score = $('.big').slice(0).eq(0).text().trim();。正确结果如图。
{<7>}
NodeJS制作爬虫全过程的更多相关文章
- nodejs制作爬虫程序
在nodejs中,可以通过不断对服务器进行请求,以及本身的fs =>filesystem 模块和clientRequest模块对网站的资源进行怕取,目前只做到了对图片的趴取!视频文件格式各异, ...
- NodeJS网络爬虫
原文地址:NodeJS网络爬虫 网上有很多其他语言平台版本的网络爬虫,比如Python,Java.那怎么能少得了我们无所不能的javascript呢
- NodeJS简单爬虫
NodeJS简单爬虫 最近一直在追火星的一本书,然后每次都要去网站看,感觉很麻烦,于是,想起用爬虫爬取章节,务实派,说干就干! 爬取思路 1.该网站的页面呈现出一定的规律 2.使用NodeJS的req ...
- nodejs豆瓣爬虫
从零开始nodejs系列文章,将介绍如何利Javascript做为服务端脚本,通过Nodejs框架web开发.Nodejs框架是基于V8的引擎,是目前速度最快的Javascript引擎.chrome浏 ...
- 基于node.js制作爬虫教程
前言:最近想学习node.js,突然在网上看到基于node的爬虫制作教程,所以简单学习了一下,把这篇文章分享给同样初学node.js的朋友. 目标:爬取 http://tweixin.yueyishu ...
- c#制作计算器全过程
前言: 网上看的计算器制作只有代码,没有为全过程下面贴图,所以我在下面主要是贴图,让大家零基础制作计算器. 我的环境是visual studio 2010,其他版本例如2008,2012 都可以 1. ...
- Nodejs书写爬虫工具
看了几天的nodejs,的确是好用,全当是练手了,就写了一个爬虫工具. 爬虫思路都是一致的,先抓取页面数据,然后分析页面,获取到所需要的数据,最后获得这些数据,是写入到硬盘,还是显示到网页,自己看着办 ...
- Nodejs实现爬虫抓取数据
开始之前请先确保自己安装了Node.js环境,还没有安装的的童鞋请自行百度安装教程...... 1.在项目文件夹安装两个必须的依赖包 npm install superagent --save-dev ...
- Nodejs 网络爬虫(资讯爬虫) 案例
1. superagent superagent 是一个流行的nodejs第三方模块,专注于处理服务端/客户端的http请求.在nodejs中,我们可以使用内置的http等模块来进行请求的发送.响应处 ...
随机推荐
- 在一台电脑访问另一台电脑的mysql数据库
1. 假设192.168.1.3为服务器 2. 首先在ip为192.168.1.103的机子上能够ping 通 运行->cmd >ping 192.168.1.3 检 ...
- 委托、 Lambda表达式和事件——事件
/* * 由SharpDevelop创建. * 用户: David Huang * 日期: 2015/7/31 * 时间: 14:21 */ using System; namespace 事件 { ...
- Adding Validation to our Album Forms 添加类属性的一些验证特性
Adding Validation to our Album Forms We’ll use the following Data Annotation attributes: Required – ...
- tableView尾部多处一部分空白高度
问题出现的原因:创建tableView时使用的style是UITableViewStylePlain 解决办法: 在创建tableView时,self.automaticallyAdjustsScro ...
- 内联式css样式,直接写在现有的HTML标签中
CSS样式可以写在哪些地方呢?从CSS 样式代码插入的形式来看基本可以分为以下3种:内联式.嵌入式和外部式三种.这一小节先来讲解内联式. 内联式css样式表就是把css代码直接写在现有的HTML标签中 ...
- JS入门笔记
DOM有四种节点: 1. 元素节点:即标签2. 属性节点:写在标签里的属性3. 文本节点:嵌在元素节点里展示出来的文本4. 文档节点:document 获取元素节点的三种常用方法: 1.ById 2. ...
- mysql数据库中编码问题(续)
其实之前的数据库中文乱码问题并没有彻底的解决,虽然在网页上显示正常,但是在数据库中却是乱码,虽然用户看起来没问题,但是自己就遭罪了,而且也是个极大的问题 究其原因,是没注意到一点,就是数据库中表的结构 ...
- 2016.7.16equals的使用(一)
class V{ private int a; V(int a){ rhis a=a; } public boolean equals(int a,int b){ if(this.a equals( ...
- IOS下双击背景, touchmove, 阻止页面背景scroll.
ios prevent dblclick(tap) page scrollhtml add:("minimal-ui" is very important) <meta na ...
- Xcode编译项目出现访问private key提示框
原因: 在编译时Xcode进行codesign时需要访问"private key"时没有权限,然后让询问是否允许,有三个选项,全部允许.否绝.允许,一次弹出4个(我遇到的) 遇到问 ...