Scrapy爬虫框架第八讲【项目实战篇:知乎用户信息抓取】--本文参考静觅博主所写
思路分析:
(1)选定起始人(即选择关注数和粉丝数较多的人--大V)
(2)获取该大V的个人信息
(3)获取关注列表用户信息
(4)获取粉丝列表用户信息
(5)重复(2)(3)(4)步实现全知乎用户爬取
实战演练:
(1)、创建项目:scrapy startproject zhijutest
(2)、创建爬虫:cd zhihutest -----scrapy genspider zhihu www.zhihu.com
(3)、选取起始人(这里我选择了以下用户)
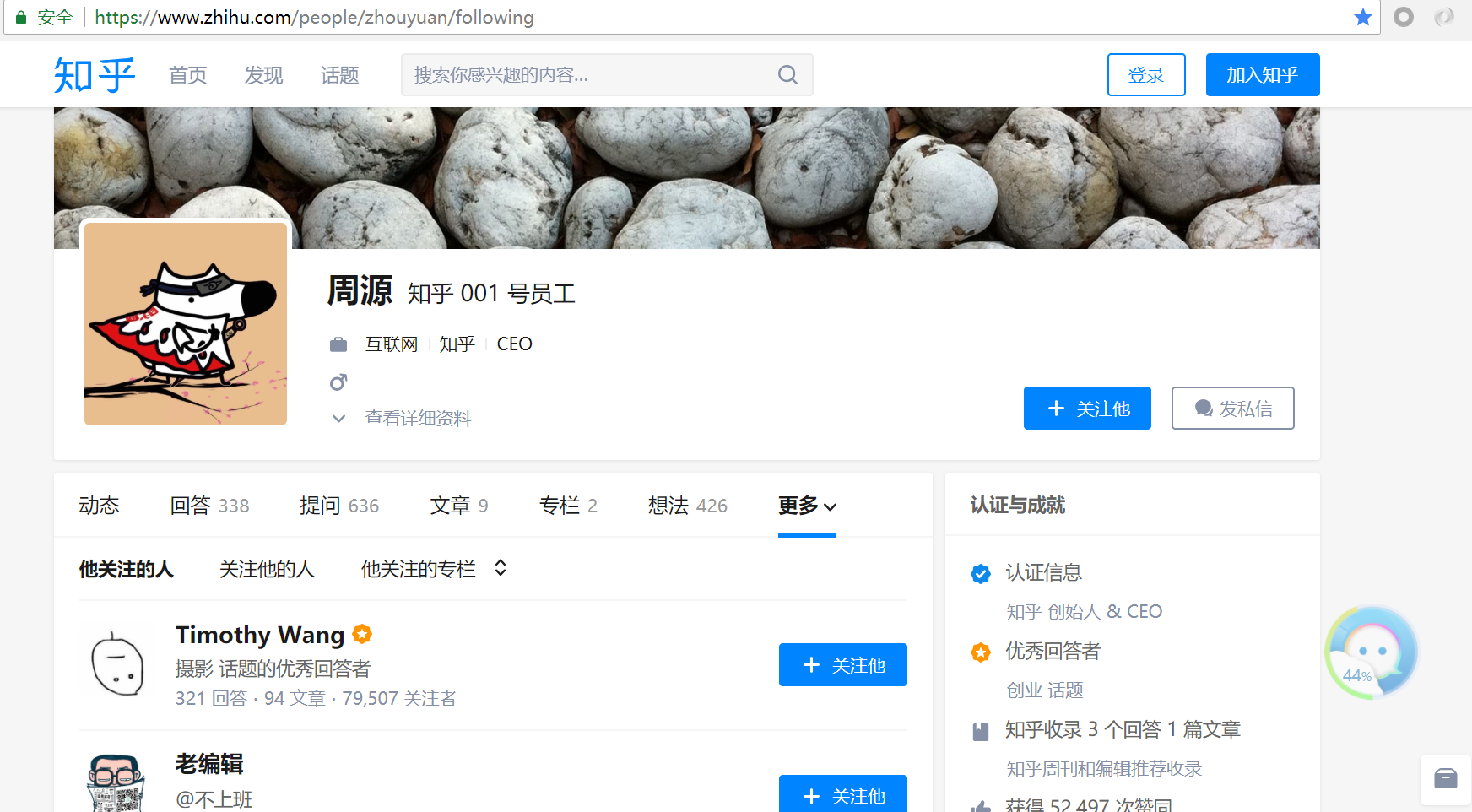
我们可以看到他关注的人和关注他的人,这些内容是我们(3)(4)步需要获取的
(3)、更改settings.py

代码分析:这里我们设置了不遵守robots协议
robots协议:网络爬虫协议,它用来告诉用户那些内容可以爬取,那些内容禁止爬取,一般我们运行爬虫项目,首先会访问网站的robots.txt页面,它告诉爬虫那些是你可以获取的内容,这里我们为了方便,即不遵守robots协议。

代码分析:这里我们设置了User-Agent和authorization字段(这是知乎对请求头的限制了,即反爬),而这里我们通过设置模拟了在没有登陆的前提下伪装成浏览器去请求知乎
(4)、页面初步分析
右击鼠标打开chrome开发者工具选项,并选中如下箭头所指,将鼠标放在黄色标记上,我们可以发现右侧加载出了一个ajax请求
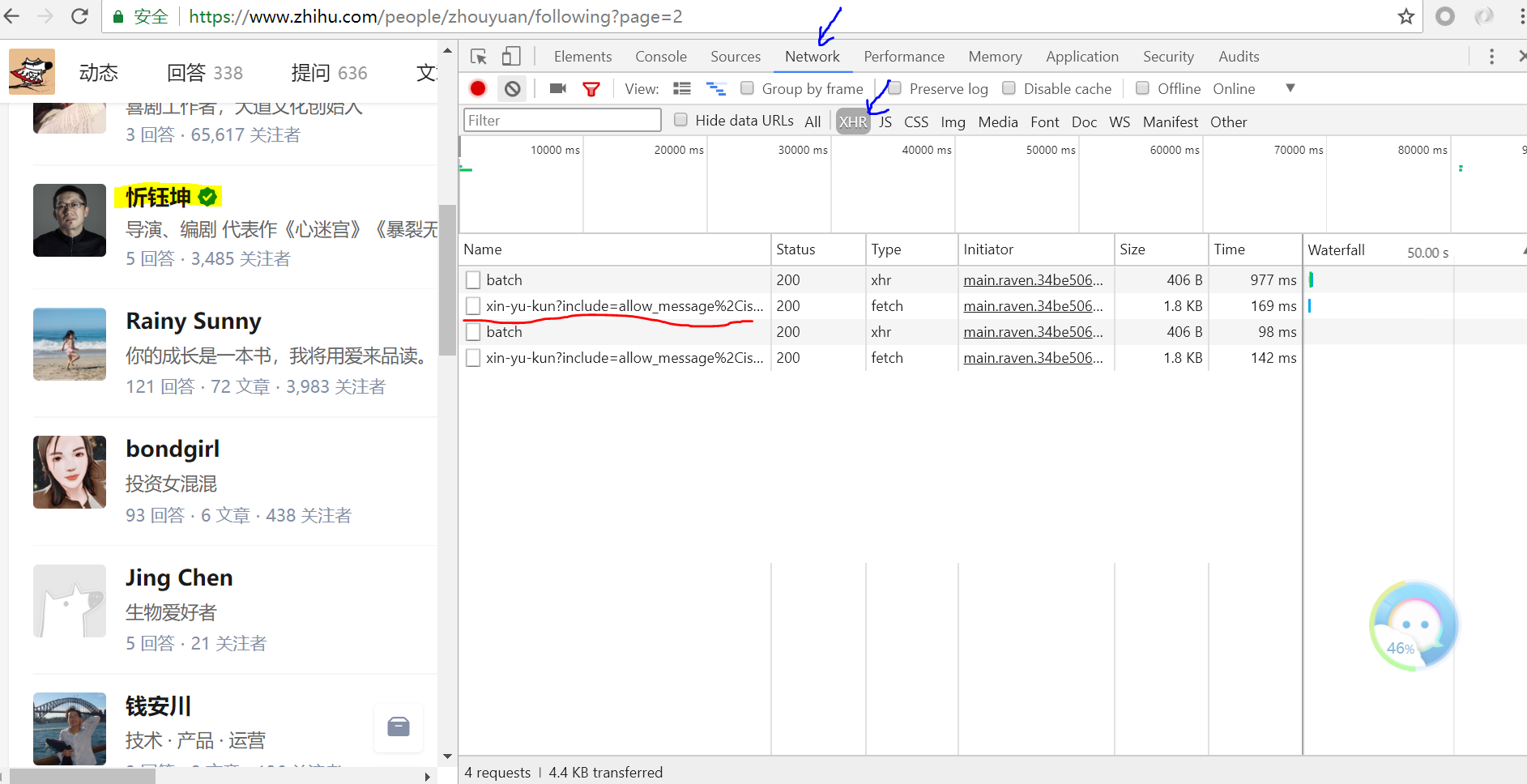
单击该ajax请求,得到如下页面:我们可以看见黄色部分为每位用户的详细信息的url,它包含多个参数用来存储信息
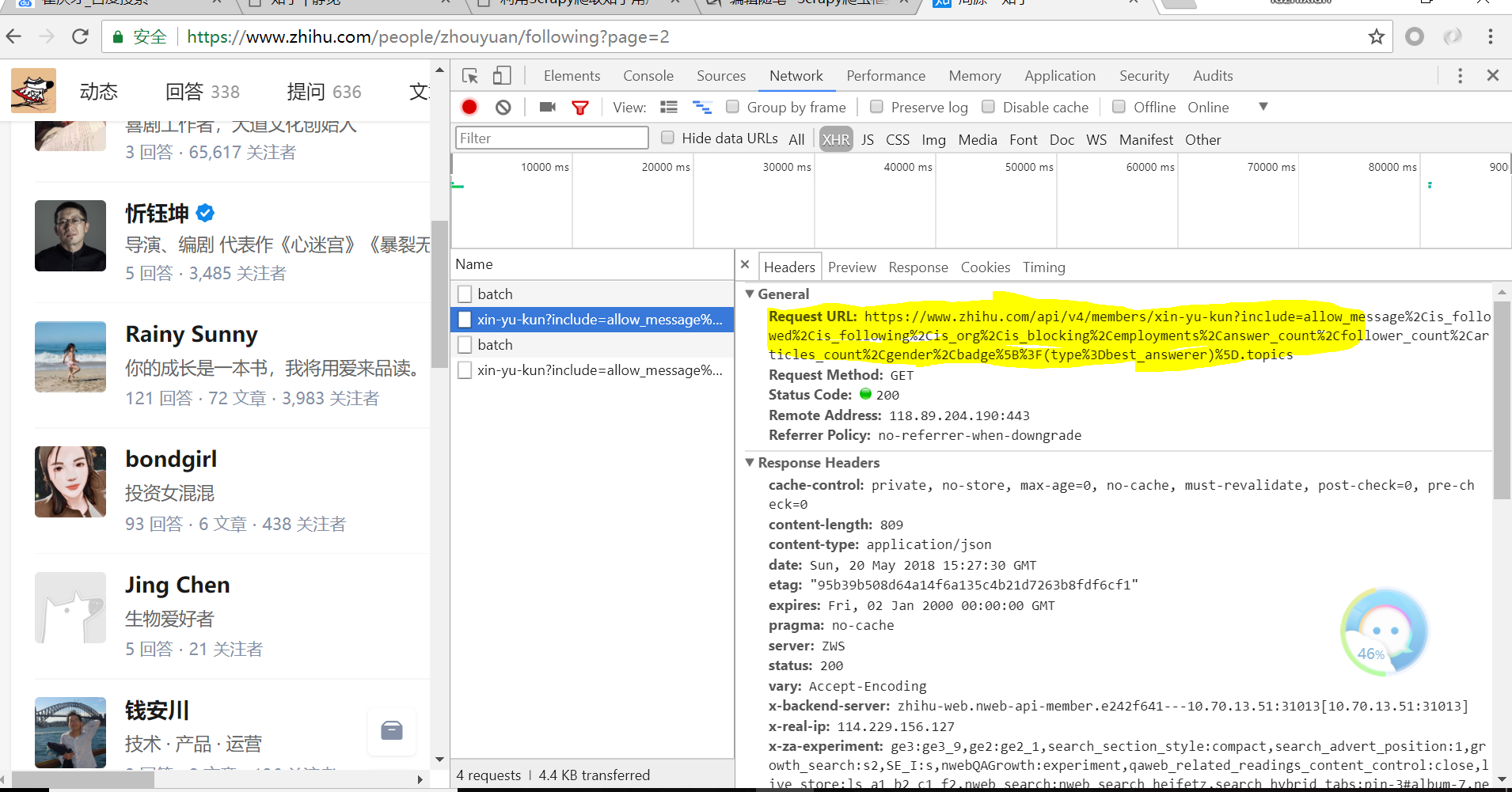
此时再将页面下滑可以看到如下信息:

该字段为上面参数的字段详情(Query String Parameters,英文好的小伙伴应该一眼发现)
(5)、更改items.py
承接上面将页面点击左侧并翻页,可以看出右侧出现了新的Ajax请求:followees:......这就是他关注者信息,通过点击Preview我们获取了网页源代码,可以发现包含了每一页的用户信息,小伙伴们可以核对下,发现信息能匹配上,我们可以从中发现每页包含20条他的关注者信息,而黑框部分就是包含每一位用户详细信息的参数,我们通过它们来定义item.py(即爬什么???)
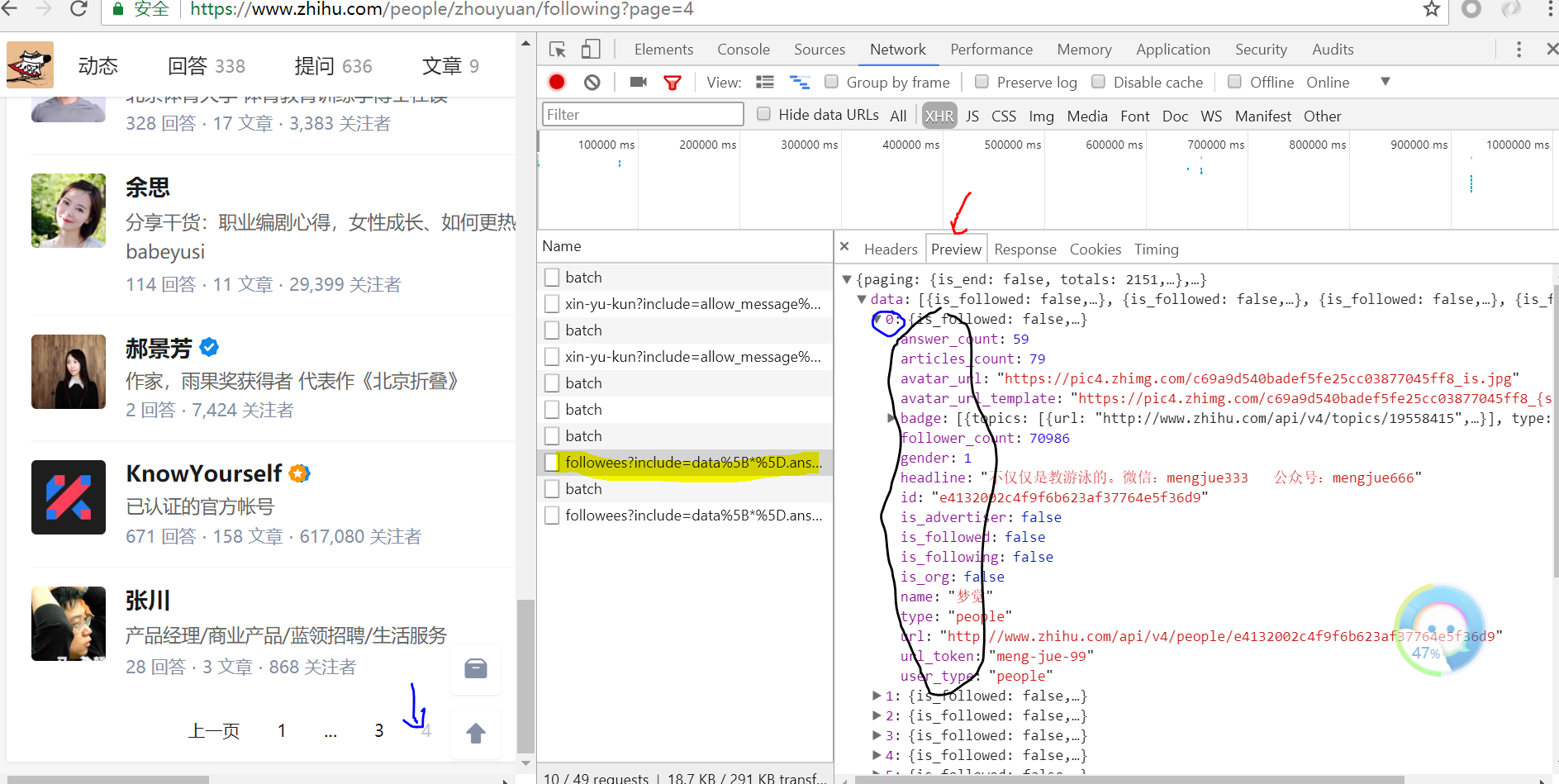
修改items.py如下:
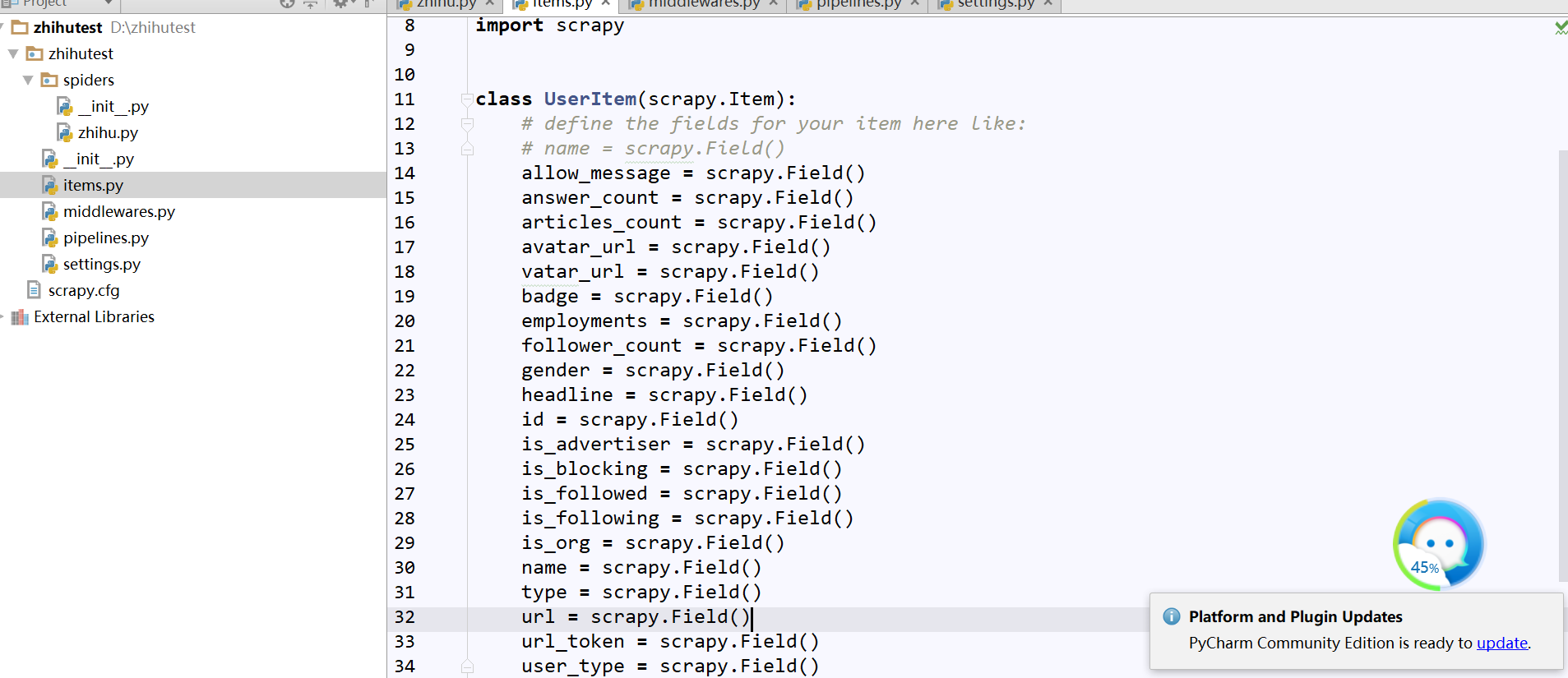
(6)、更改zhihu.py
第一步:模块导入
# -*- coding: utf-8 -*-
import json import scrapy from ..items import UserItem class ZhihuSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['zhihu.com']
start_urls = ['http://zhihu.com/'] #设定起始爬取人,这里我们通过观察发现与url_token字段有关
start_user = 'zhouyuan' #选取起始爬取人的页面详情信息,这里我们传入了user和include参数方便对不同的用户进行爬取
user_url = 'https://www.zhihu.com/api/v4/members/{user}?include={include}'
#用户详情参数即包含在include后面的字段
user_query = 'allow_message,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics' #这是他的关注者的url,这里包含了每位他的关注者的url,同样我们传入了user和include参数方便对不同用户进行爬取
follows_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}'
#他的每位关注者详情参数,即包含在include后面的字段
follows_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' #这是他的粉丝的url,这里包含了每位他的关注者的url,同样我们传入了user和include参数方便对不同用户进行爬取
followers_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}'
#他的每位粉丝的详情参数,即包含在include后面的字段
followers_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' #重新定义起始爬取点的url
def start_requests(self):
#这里我们传入了将选定的大V的详情页面的url,并指定了解析函数parseUser
yield scrapy.Request(self.user_url.format(user=self.start_user, include=self.user_query), callback=self.parseUser)
#这里我们传入了将选定的大V他的关注者的详情页面的url,并指定了解析函数parseFollows
yield scrapy.Request(self.follows_url.format(user=self.start_user, include=self.follows_query, offset=0, limit=20), callback=self.parseFollows)
#这里我们传入了将选定的大V的粉丝的详情页面的url,并指定了解析函数parseFollowers
yield scrapy.Request(self.followers_url.format(user=self.start_user, include=self.followers_query, offset=0, limit=20), callback=self.parseFollowers) #爬取每一位用户详情的页面解析函数
def parseUser(self, response):
#这里页面上是json字符串类型我们使用json.loads()方法将其变为文本字符串格式
result = json.loads(response.text)
item = UserItem() #这里我们遍历了items.py中定义的字段并判断每位用户的详情页中的keys是否包含该字段,如包含则获取
for field in item.fields:
if field in result.keys():
item[field] = result.get(field)
yield item
#定义回调函数,爬取他的关注者与粉丝的详细信息,实现层层迭代
yield scrapy.Request(self.follows_url.format(user=result.get('url_token'), include=self.follows_query, offset=0, limit=20), callback=self.parseFollows)
yield scrapy.Request(self.followers_url.format(user=result.get('url_token'), include=self.followers_query, offset=0, limit=20), callback=self.parseFollowers) #他的关注者的页面解析函数
def parseFollows(self, response):
results = json.loads(response.text)
#判断data标签下是否含有获取的文本字段的keys
if 'data' in results.keys():
for result in results.get('data'):
yield scrapy.Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), callback=self.parseUser)
#判断页面是否翻到了最后
if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
yield scrapy.Request(next_page, callback=self.parseFollows) #他的粉丝的页面解析函数
def parseFollowers(self, response):
results = json.loads(response.text) if 'data' in results.keys():
for result in results.get('data'):
yield scrapy.Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), callback=self.parseUser) if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
yield scrapy.Request(next_page, callback=self.parseFollowers)
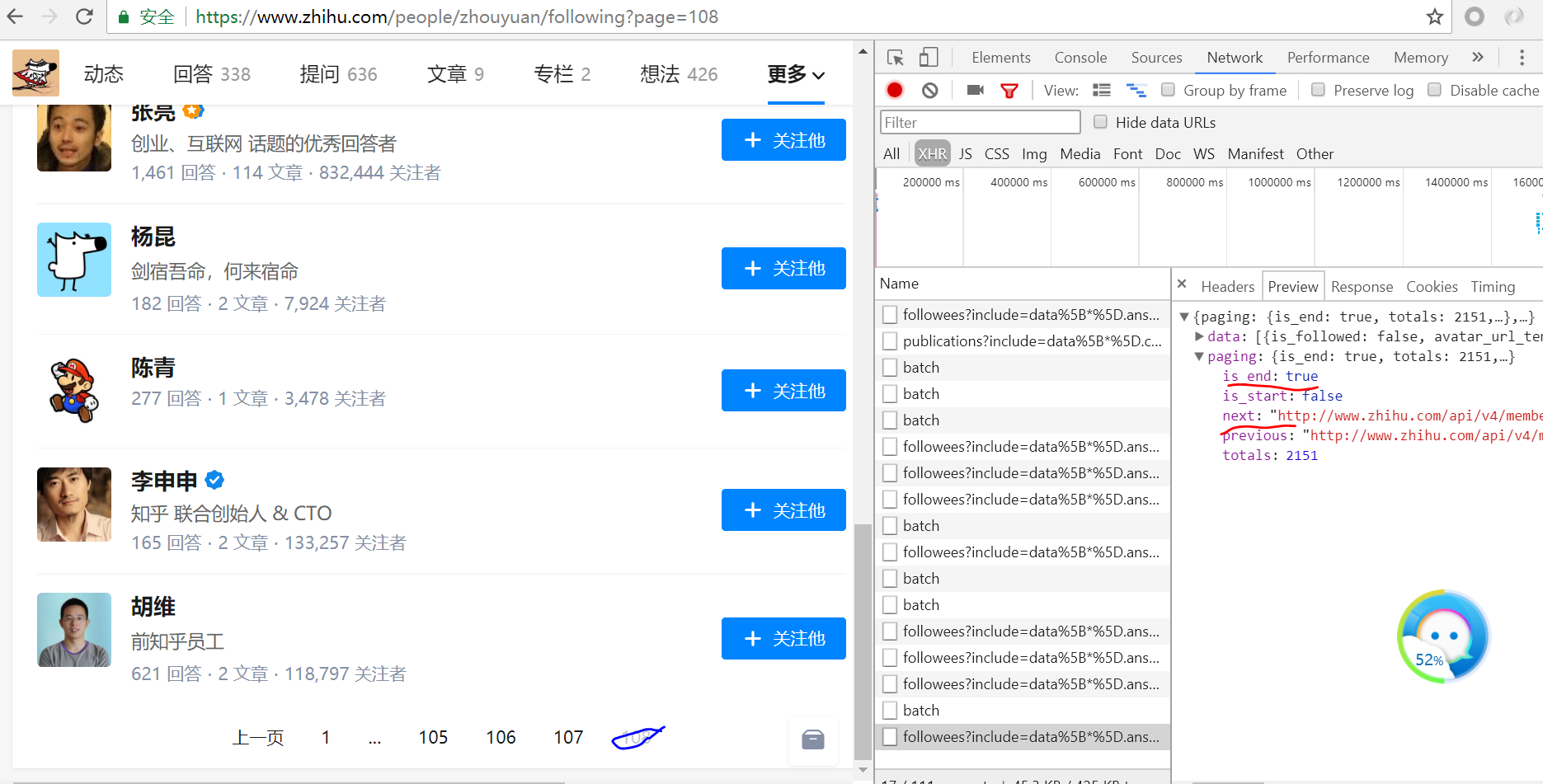
我们可以看到当我们翻到了最后is_end字段变为了True,而next字段就是下一个页面的url
(7)、运行下程序,可以看见已经在爬取了

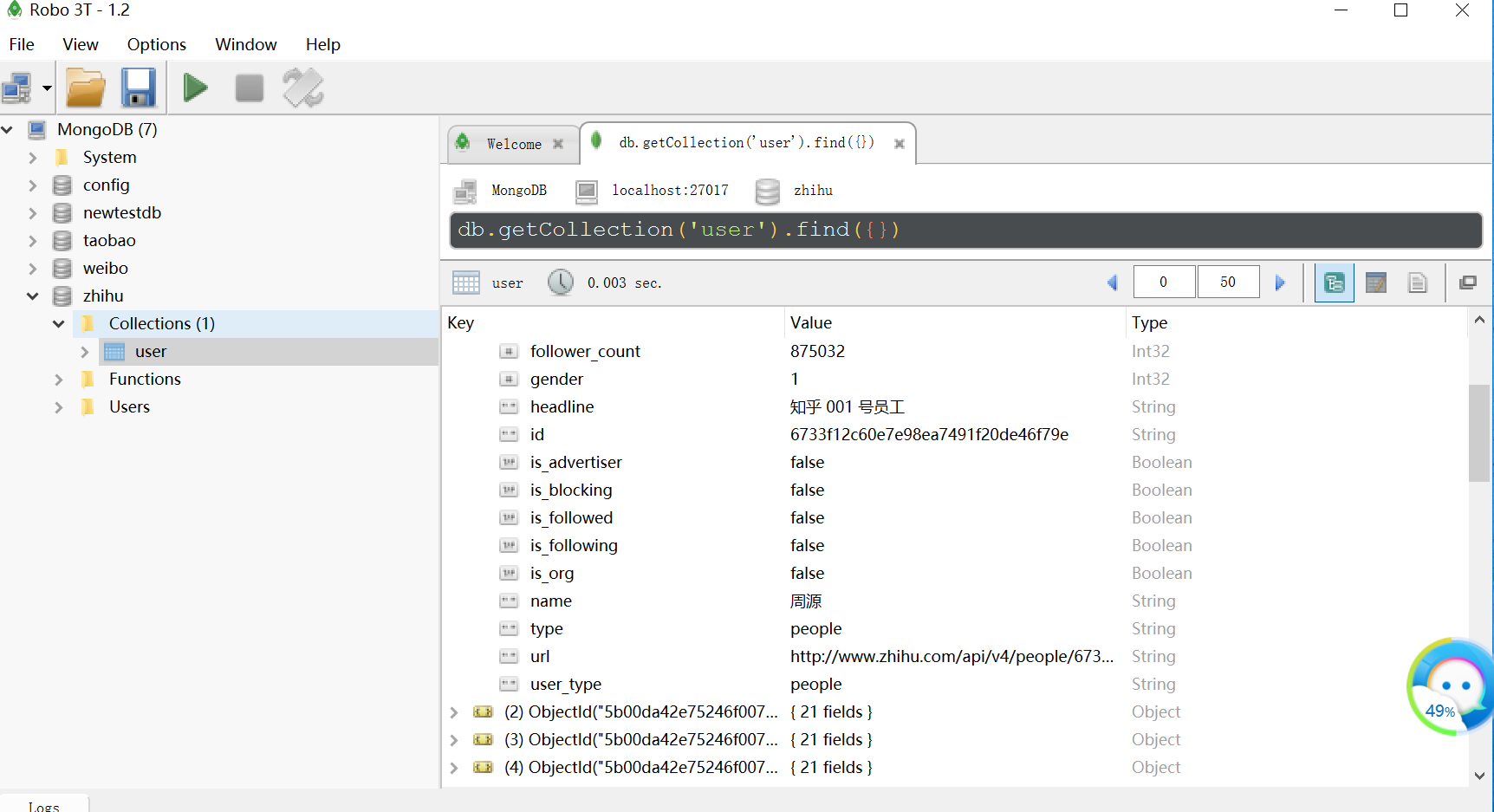
(8)、将结果存入Mongodb数据库
重写pipelines.py
import pymongo
class MongoPipeline(object):
collection_name = 'user'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db['user'].update({'url_token' :item['url_token']},{'$set':item},True)
代码分析:
我们创建了名为user的集合
重写了__init__方法指定了数据库的链接地址和数据库名称
并修改了工厂类函数(具体参见上讲ITEM PIPLELIEN用法)
打开数据库并插入数据并以url_token字段对重复数据执行了更新操作
最后我们关闭了数据库
再配置下settings.py


再次运行程序,可以看见我们的数据就到了数据库了
Scrapy爬虫框架第八讲【项目实战篇:知乎用户信息抓取】--本文参考静觅博主所写的更多相关文章
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- Scrapy爬虫框架第七讲【ITEM PIPELINE用法】
ITEM PIPELINE用法详解: ITEM PIPELINE作用: 清理HTML数据 验证爬取的数据(检查item包含某些字段) 去重(并丢弃)[预防数据去重,真正去重是在url,即请求阶段做] ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(下)
前几天小编带大家学会了如何在Scrapy框架下创建属于自己的第一个爬虫项目(上),今天我们进一步深入的了解Scrapy爬虫项目创建,这里以伯乐在线网站的所有文章页为例进行说明. 在我们创建好Scrap ...
- python 手机App数据抓取实战二抖音用户的抓取
前言 什么?你问我国庆七天假期干了什么?说出来你可能不信,我爬取了cxk坤坤的抖音粉丝数据,我也不知道我为什么这么无聊. 本文主要记录如何使用appium自动化工具实现抖音App模拟滑动,然后分析数据 ...
- Scrapy爬虫框架第四讲(Linux环境)
下面我们来学习Selector的具体使用:(参考文档:http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/selectors.html) Selecto ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
随机推荐
- 色彩转换——RGB & HSL
RGB to HSL The R,G,B values are divided by 255 to change the range from 0..255 to 0..1: R' = R/255 G ...
- C语言实现printf的基本格式输出%d,%c,%p,%s
关于printf的实现,想必看过我之前发表的文章的伙伴们已经了解了不少基本的知识.好了,接下来不多说了,直接上源码,看看一种简单的实现方式: #include <stdio.h> #def ...
- C语言可变参实现参数累加返回
C语言可变参的作用真的是非常大,自从发表了可变参如何实现printf,fprintf,sprintf的文章以来,便有不少博友私信问我实现的机制,我也解释了相关的知识点.今天,我们借着这个机会,再来举一 ...
- HBase Region级别二级索引
我们会经常谈及二级索引,这是对全表数据进行另外一种方式的组织存储,是针对table级别的.如果要为HBase上的表实现一个强一致性的二级索引,那么就无法逃避分布式事务,而这一直是用户最期待的功能. 而 ...
- ios中XMPP的搭建
1 首先下载xmppframework这个框架 https://github.com/robbiehanson/XMPPFramework 2 环境配置 参考:https://github.com ...
- Factor Pattern----工厂模式
一. 概念 工厂模式就是负责生成其他对象的类或方法,就是把创建对象的过程封装起来,这样随时可以产生一个新的对象,减少代码之间耦合. 二. 使用场景(原因) 工厂模式可以将对象的生产从直接new 一个对 ...
- asp.net mvc控制器激活全分析
控制器的激活默认情况下使用反射来实现的,这其中采用了DI,单例等设计模式.对于控制器的主要涉及到如下的类:ControllerBuilder.DefaultControllerFactory.Defa ...
- c# 获取TFS结构 文件
#region 获取最新版本 /// <summary> /// 获取最新版本 /// </summary> /// <param name="server_u ...
- 如何使你的Ajax应用内容可让搜索引擎爬行
This document outlines the steps that are necessary in order to make your AJAX application crawlable ...
- Heap
#include using namespace std; int heap[100010],cnt=0; void put(int x) { cnt++; heap[cnt]=x; int now= ...