YARN集群的mapreduce测试(三)
将user表、group表、order表关;(类似于多表关联查询)
测试准备:
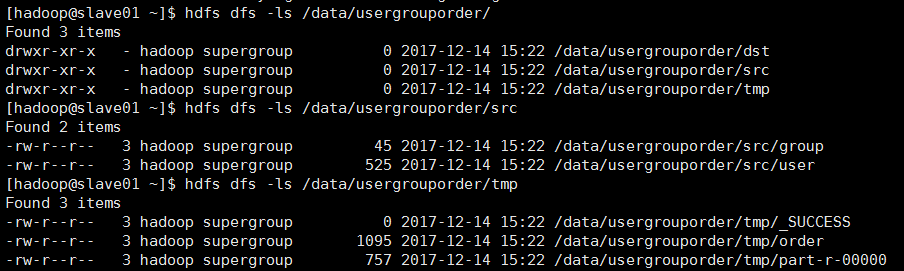
首先同步时间,然后 开启hdfs集群,开启yarn集群;在本地"/home/hadoop/test/"目录创建user表、group表、order表的文件;
user文件:
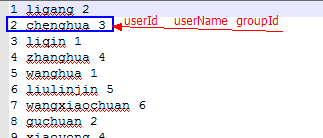
group文件:
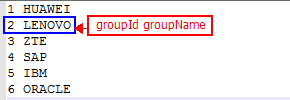
order文件:
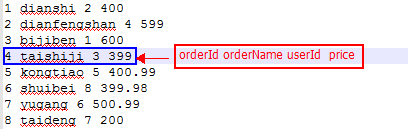
测试目标:
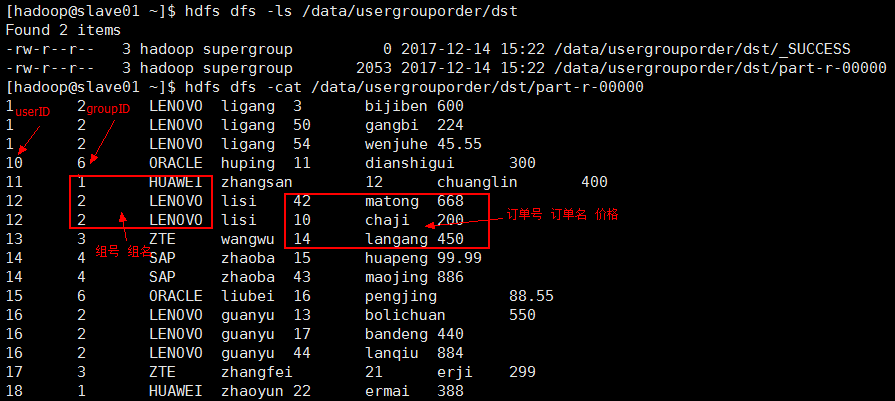
得到3张表关联后的结果;
测试代码:
一定要把握好输出键值的类型,否则有可能造成有输出目录,但是没有文件内容的问题;
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class UserGroupMapper01 extends Mapper<LongWritable, Text, Text, Text> { private Text outKey;
private Text outValue; @Override
protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
outKey = new Text();
outValue = new Text();
} @Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
FileSplit fp = (FileSplit) context.getInputSplit();
String fileName = fp.getPath().getName(); String line = value.toString();
String[] fields = line.split("\\s+"); String keyStr = null;
String valueStr = null;
if ("group".equalsIgnoreCase(fileName)) {
keyStr = fields[0];
valueStr = new StringBuilder(fields[1]).append("-->").append(fileName).toString();
} else {
keyStr = fields[2];
//加“-->”;后以此标识符作为分割符,进行文件区分
valueStr = new StringBuilder(fields[0]).append("\t").append(fields[1]).append("-->").append(fileName).toString();
} outKey.set(keyStr);
outValue.set(valueStr);
context.write(outKey, outValue); } @Override
protected void cleanup(Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
outKey = null;
outValue = null;
} }
UserGroupMapper01
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class UserGroupReducer01 extends Reducer<Text, Text, Text, Text> { private Text outValue; @Override
protected void setup(Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
outValue = new Text();
} @Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
Iterator<Text> its = values.iterator(); String masterRecord = null;
List<String> slaveRecords = new ArrayList<String>(); //拆分出主表记录和从表记录
while (its.hasNext()) {
String[] rowAndFileName = its.next().toString().split("-->");
if (rowAndFileName[1].equalsIgnoreCase("group")) {
masterRecord = rowAndFileName[0];
continue;
}
slaveRecords.add(rowAndFileName[0]);
} for (String slaveRecord : slaveRecords) {
String valueStr = new StringBuilder(masterRecord).append("\t").append(slaveRecord).toString();
outValue.set(valueStr);
context.write(key, outValue);
} } @Override
protected void cleanup(Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
outValue = null;
} }
UserGroupReducer01
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* @author hadoop
*
*/
public class UserGroupDriver01 { private static FileSystem fs;
private static Configuration conf;
static {
String uri = "hdfs://master01:9000/";
conf = new Configuration();
try {
fs = FileSystem.get(new URI(uri), conf, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Job ugJob01 = getJob(args);
if (null == ugJob01) {
return;
}
//提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端
boolean flag = false;
flag = ugJob01.waitForCompletion(true);
System.exit(flag?0:1);
} /**
* 获取Job实例
* @param args
* @return
* @throws IOException
*/
public static Job getJob(String[] args) throws IOException {
if (null==args || args.length<2) return null;
//放置需要处理的数据所在的HDFS路径
Path inputPath = new Path(args[0]);
//放置Job作业执行完成之后其处理结果的输出路径
Path outputPath = new Path(args[1]);
//主机文件路径
Path userPath = new Path("/home/hadoop/test/user");
Path groupPath = new Path("/home/hadoop/test/group"); //如果输入的集群路径存在,则删除
if (fs.exists(inputPath)) {
fs.delete(inputPath, true);//true表示递归删除
}
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);//true表示递归删除
} //创建并且将数据文件拷贝到创建的集群路径
fs.mkdirs(inputPath);
fs.copyFromLocalFile(false, false, new Path[]{userPath, groupPath}, inputPath); //获取Job实例
Job ugJob01 = Job.getInstance(conf, "UserGroupJob01");
//设置运行此jar包入口类
//ugJob01的入口是WordCountDriver类
ugJob01.setJarByClass(UserGroupDriver01.class);
//设置Job调用的Mapper类
ugJob01.setMapperClass(UserGroupMapper01.class);
//设置Job调用的Reducer类(如果一个Job没有Reducer则可以不调用此条语句)
ugJob01.setReducerClass(UserGroupReducer01.class); //设置MapTask的输出键类型
ugJob01.setMapOutputKeyClass(Text.class);
//设置MapTask的输出值类型
ugJob01.setMapOutputValueClass(Text.class); //设置整个Job的输出键类型(如果一个Job没有Reducer则可以不调用此条语句)
ugJob01.setOutputKeyClass(Text.class);
//设置整个Job的输出值类型(如果一个Job没有Reducer则可以不调用此条语句)
ugJob01.setOutputValueClass(Text.class); //设置整个Job需要处理数据的输入路径
FileInputFormat.setInputPaths(ugJob01, inputPath);
//设置整个Job计算结果的输出路径
FileOutputFormat.setOutputPath(ugJob01, outputPath); return ugJob01;
} }
UserGroupDriver01
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class UserGroupMapper02 extends Mapper<LongWritable, Text, Text, Text> { private Text outKey;
private Text outValue; @Override
protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
outKey = new Text();
outValue = new Text();
} @Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
FileSplit fp = (FileSplit) context.getInputSplit();
String fileName = fp.getPath().getName(); String line = value.toString();
String[] fields = line.split("\\s+"); String keyStr = fields[2];
String valueStr = null;
valueStr = new StringBuilder(fields[0]).append("\t").append(fields[1]).append("\t").append(fields[3]).append("-->").append(fileName).toString(); outKey.set(keyStr);
outValue.set(valueStr);
context.write(outKey, outValue); } @Override
protected void cleanup(Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
outKey = null;
outValue = null;
} }
UserGroupMapper02
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class UserGroupReducer02 extends Reducer<Text, Text, Text, Text> { private Text outValue; @Override
protected void setup(Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
outValue = new Text();
} @Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
String masterRecord = null;
List<String> slaveRecords = new ArrayList<String>(); //拆分出主表记录和从表记录
Iterator<Text> its = values.iterator();
while (its.hasNext()) {
String[] rowAndFileName = its.next().toString().split("-->");
if (!rowAndFileName[1].equalsIgnoreCase("order")) {
masterRecord = rowAndFileName[0];
continue;
}
slaveRecords.add(rowAndFileName[0]);
} for (String slaveRecord : slaveRecords) {
String valueStr = new StringBuilder(masterRecord).append("\t").append(slaveRecord).toString();
outValue.set(valueStr);
context.write(key, outValue);
} } @Override
protected void cleanup(Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
outValue = null;
} }
UserGroupReducer02
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* @author hadoop
*
*/
public class UserGroupDriver02 { private static FileSystem fs;
private static Configuration conf;
static {
String uri = "hdfs://master01:9000/";
conf = new Configuration();
try {
fs = FileSystem.get(new URI(uri), conf, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Job ugJob02 = getJob(new String[] {args[1], args[2]});
if (null == ugJob02) {
return;
}
//提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端
boolean flag = false;
flag = ugJob02.waitForCompletion(true);
System.exit(flag?0:1);
} /**
* 获取Job实例
* @param args
* @return
* @throws IOException
*/
public static Job getJob(String[] args) throws IOException {
if (null==args || args.length<2) return null;
//放置需要处理的数据所在的HDFS路径
Path inputPath = new Path(args[1]);
//放置Job作业执行完成之后其处理结果的输出路径
Path outputPath = new Path(args[2]);
//主机文件路径
Path orderPath = new Path("/home/hadoop/test/order"); //输入的集群路径存在,在第一次已创建
if (!fs.exists(inputPath)) return null;
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);//true表示递归删除
} //将数据文件拷贝到创建的集群路径
fs.copyFromLocalFile(false, false, orderPath, inputPath); //获取Job实例
Job ugJob02 = Job.getInstance(conf, "UserGroupJob02");
//设置运行此jar包入口类
//ugJob02的入口是WordCountDriver类
ugJob02.setJarByClass(UserGroupDriver02.class);
//设置Job调用的Mapper类
ugJob02.setMapperClass(UserGroupMapper02.class);
//设置Job调用的Reducer类(如果一个Job没有Reducer则可以不调用此条语句)
ugJob02.setReducerClass(UserGroupReducer02.class); //设置MapTask的输出键类型
ugJob02.setMapOutputKeyClass(Text.class);
//设置MapTask的输出值类型
ugJob02.setMapOutputValueClass(Text.class); //设置整个Job的输出键类型(如果一个Job没有Reducer则可以不调用此条语句)
ugJob02.setOutputKeyClass(Text.class);
//设置整个Job的输出值类型(如果一个Job没有Reducer则可以不调用此条语句)
ugJob02.setOutputValueClass(Text.class); //设置整个Job需要处理数据的输入路径
FileInputFormat.setInputPaths(ugJob02, inputPath);
//设置整个Job计算结果的输出路径
FileOutputFormat.setOutputPath(ugJob02, outputPath); return ugJob02;
} }
UserGroupDriver02
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job; public class UserGroupDriver { private static FileSystem fs;
private static Configuration conf;
private static final String TEMP= "hdfs://master01:9000/data/usergrouporder/tmp";
static {
String uri = "hdfs://master01:9000/";
conf = new Configuration();
try {
fs = FileSystem.get(new URI(uri), conf, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { String[] params = {args[0], TEMP, args[1]}; //运行第1个Job
Job ugJob01 = UserGroupDriver01.getJob(params);
//提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端
boolean flag01 = ugJob01.waitForCompletion(true);
if (!flag01) {
System.out.println("job2 running failure......");
System.exit(1);
} //运行第2个Job
Job ugJob02 = UserGroupDriver02.getJob(params);
//提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端
boolean flag02 = ugJob02.waitForCompletion(true);
if (flag02) {//等待Job02完成后就删掉中间目录并退出;
// fs.delete(new Path(TEMP), true);
System.out.println("job2 running success......");
System.exit(0);
}
System.out.println("job2 running failure......");
System.exit(1);
} }
UserGroupDriver
为了更好的测试,可以先屏蔽删除中间输出结果的语句;
//总Driver
String[] params = {args[0], TEMP, args[1]};
//运行第1个Job
Job ugJob01 = UserGroupDriver01.getJob(params);
//运行第2个Job
Job ugJob02 = UserGroupDriver02.getJob(params); //分Driver01
//放置需要处理的数据所在的HDFS路径
Path inputPath = new Path(args[0]);//params中的args[0]
//放置Job作业执行完成之后其处理结果的输出路径
Path outputPath = new Path(args[1]);//params中的TEMP //分Driver02
//params中的TEMP和args[2]//放置需要处理的数据所在的HDFS路径
Path inputPath = new Path(args[1]);
//放置Job作业执行完成之后其处理结果的输出路径
Path outputPath = new Path(args[2]);
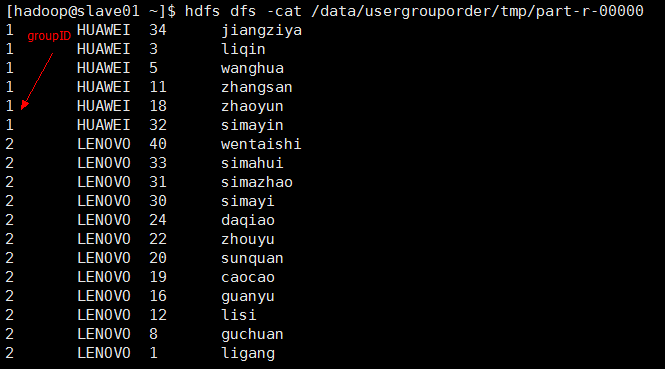
测试结果:
运行时传入参数是:
如果在eclipse上运行:传参需要加上集群的master的uri即 hdfs://master01:9000
输入路径参数: /data/usergrouporder/src
输出路径参数: /data/usergrouporder/dst
YARN集群的mapreduce测试(三)的更多相关文章
- YARN集群的mapreduce测试(六)
两张表链接操作(分布式缓存): ----------------------------------假设:其中一张A表,只有20条数据记录(比如group表)另外一张非常大,上亿的记录数量(比如use ...
- YARN集群的mapreduce测试(五)
将user表计算后的结果分区存储 测试准备: 首先同步时间,然后master先开启hdfs集群,再开启yarn集群:用jps查看: master上: 先有NameNode.SecondaryNameN ...
- YARN集群的mapreduce测试(一)
hadoop集群搭建中配置了mapreduce的别名是yarn [hadoop@master01 hadoop]$ mv mapred-site.xml.template mapred-site.xm ...
- YARN集群的mapreduce测试(四)
将手机用户使用流量的数据进行分组,排序: 测试准备: 首先同步时间,然后master先开启hdfs集群,再开启yarn集群:用jps查看: master上: 先有NameNode.SecondaryN ...
- YARN集群的mapreduce测试(二)
只有mapTask任务没有reduceTask的情况: 测试准备: 首先同步时间,然后 开启hdfs集群,开启yarn集群:在本地"/home/hadoop/test/"目录创建u ...
- 大数据入门第八天——MapReduce详解(三)MR的shuffer、combiner与Yarn集群分析
/mr的combiner /mr的排序 /mr的shuffle /mr与yarn /mr运行模式 /mr实现join /mr全局图 /mr的压缩 今日提纲 一.流量汇总排序的实现 1.需求 对日志数据 ...
- 大数据【三】YARN集群部署
一 概述 YARN是一个资源管理.任务调度的框架,采用master/slave架构,主要包含三大模块:ResourceManager(RM).NodeManager(NM).ApplicationMa ...
- Spark on Yarn 集群运行要点
实验版本:spark-1.6.0-bin-hadoop2.6 本次实验主要是想在已有的Hadoop集群上使用Spark,无需过多配置 1.下载&解压到一台使用spark的机器上即可 2.修改配 ...
- 使用Cloudera Manager搭建MapReduce集群及MapReduce HA
使用Cloudera Manager搭建MapReduce集群及MapReduce HA 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.通过CM部署MapReduce On ...
随机推荐
- leetcode - valid number 正则表达式解法
import java.util.regex.Pattern; public class Solution { Pattern p = Pattern.compile("^[\\+\\-]? ...
- android踩坑日记1
Android四大组件-活动.服务.广播.碎片 情况一 应用场景:定时从服务器获取数据,然后活动或者碎片中根据最新获得的数据,更新UI. 思考: 首先定时,想到定时器,推荐使用系统自带的AlertMa ...
- 解决Eclipse中无法直接使用Base64Encoder的问题(转载)
资源出处:https://blog.csdn.net/u011514810/article/details/72725398 Base64的加密解密都是使用sun.misc包下的BASE64Encod ...
- @ResponseBody 返回乱码 的解决办法
1:最快的 最简单的办法是 在Ajax请求脸面指定头信息Accept属性,StringHttpMessageConverter默认iso-8859-1编码,但是会根据请求头信息指定的编码格式来转换 ...
- Python之路【第四篇】Python基础2
一.格式化输出 按要求输出信息 name=input("name:") age=int(input("age:")) job=input("job:& ...
- 学习Java的进度
这周我们通过老师的讲解带着我们回到了第八周的知识点.lambda表达式也是一种简化程序的好方法,通过回调程序的测试可以对比出lambda 表达式少的不是一两行代码,可以少了类中方法的定义,直接使用.内 ...
- QEMU Networking
QEMU Networking QEMU has a number of really nice ways to set up networking for its guests. It can be ...
- c# 字符串中多个连续空格转为一个空格
#region 字符串中多个连续空格转为一个空格 /// <summary> /// 字符串中多个连续空格转为一个空格 /// </summary> /// <param ...
- 【洛谷4172】 [WC2006]水管局长(LCT)
传送门 洛谷 BZOJ Solution 如果不需要动态的话,那就是一个裸的最小生成树上的最大边权对吧. 现在动态了的话,把这个过程反着来,就是加边对吧. 现在问题变成了怎么动态维护加边的最小生成树, ...
- 使用githubpages主题NexT的语法
使用githubpages主题NexT的语法 NexT 前言 不知道为啥?网站总是不出现? 添加「标签」页面 title: 标签测试文章 tags: - Testing - Another Tag - ...