【SQL】数据库中的五种约束
#五大约束
1、主键约束(Primay Key Coustraint) 唯一性,非空性
2、唯一约束 (Unique Counstraint)唯一性,可以空,但只能有一个
3、检查约束 (Check Counstraint)对该列数据的范围、格式的限制(如:年龄、性别等)
4、默认约束 (Default Counstraint)该数据的默认值
5、外键约束 (Foreign Key Counstraint)需要建立两表间的关系并引用主表的列
#五大约束的语法示例
1、添加主键约束(将UserId作为主键)
alter table UserId
add constraint PK_UserId primary key (UserId)
2、添加唯一约束(身份证号唯一,因为每个人的都不一样)
alter table UserInfo
add constraint UQ_IDNumber unique(IdentityCardNumber)
3、添加默认约束(如果地址不填 默认为“地址不详”)
alter table UserInfo
add constraint DF_UserAddress default (‘地址不详’) for UserAddress
4、添加检查约束 (对年龄加以限定 20-40岁之间)
alter table UserInfo
add constraint CK_UserAge check (UserAge between 20 and 40)
alter table UserInfo
add constraint CK_UserSex check (UserSex=’男’ or UserSex=’女′)
5、添加外键约束 (主表UserInfo和从表UserOrder建立关系,关联字段UserId)
alter table UserOrder
add constraint FK_UserId_UserId foreign key(UserId)references UserInfo(UserId)
#SQL Server中五大约束详解
约束(Constraint)是Microsoft SQL Server 提供的自动保持数据库完整性的一种方法,定义了可输入表或表的单个列中的数据的限制条件。在SQL Server 中有5 种约束:主关键字约束(Primary Key Constraint)、外关键字约束(Foreign Key Constraint)、惟一性约束(Unique Constraint)、检查约束(Check Constraint)和缺省约束(Default Constraint)。
1、主关键字约束
主关键字约束指定表的一列或几列的组合的值在表中具有惟一性,即能惟一地指定一行记录。每个表中只能有一列被指定为主关键字,且IMAGE 和TEXT 类型的列不能被指定为主关键字,也不允许指定主关键字列有NULL 属性。
此处应有说明:多列组成的主键叫联合主键,而且联合主键约束只能设定为表级约束;单列组成的主键,既可设定为列级约束,也可以设定为表级约束。
表级约束与列级约束:点我!
联合主键:
联合主键就是用2个或2个以上的字段组成主键。用这个主键包含的字段作为主键,这个组合在数据表中是唯一,且加了主键索引。
可以这么理解,比如,你的订单表里有很多字段,一般情况只要有个订单号bill_no做主键就可以了,但是,现在要求可能会有补充订单,使用相同的订单号,那么这时单独使用订单号就不可以了,因为会有重复。那么你可以再使用个订单序列号bill_seq来作为区别。把bill_no和bill_seq设成联合主键。即使bill_no相同,bill_seq不同也是可以的。
#定义主关键字约束的语法如下:
CONSTRAINT constraint_name
PRIMARY KEY [CLUSTERED | NONCLUSTERED]
(column_name1[, column_name2,…,column_name16])
#各参数说明如下:
constraint_name
指定约束的名称约束的名称。在数据库中应是惟一的。如果不指定,则系统会自动生成一个约束名。
CLUSTERED | NONCLUSTERED
指定索引类别,CLUSTERED 为缺省值。
column_name
指定组成主关键字的列名。主关键字最多由16 个列组成。
#例子:
CREATE TABLE [dbo].[UserInfo](
[UserId] [int] NOT NULL,
[UserName] [nvarchar](50) NOT NULL,
CONSTRAINT [PK_UserInfo] PRIMARY KEY CLUSTERED
(
[UserId] ASC,
[UserName] ASC
)
) ON [PRIMARY]
2、外关键字约束
外关键字约束定义了表之间的关系。当一个表中的一个列或多个列的组合和其它表中的主关键字定义相同时,就可以将这些列或列的组合定义为外关键字,并设定它适合哪个表中哪些列相关联。这样,当在定义主关键字约束的表中更新列值,时其它表中有与之相关联的外关键字约束的表中的外关键字列也将被相应地做相同的更新。外关键字约束的作用还体现在,当向含有外关键字的表插入数据时,如果与之相关联的表的列中无与插入的外关键字列值相同的值时,系统会拒绝插入数据。与主关键字相同,不能使用一个定义为 TEXT 或IMAGE 数据类型的列创建外关键字。外关键字最多由16 个列组成。
#定义外关键字约束的语法如下:
CONSTRAINT constraint_name
FOREIGN KEY (column_name1[, column_name2,…,column_name16])
REFERENCES ref_table [ (ref_column1[,ref_column2,…, ref_column16] )]
[ ON DELETE { CASCADE | NO ACTION } ]
[ ON UPDATE { CASCADE | NO ACTION } ] ]
[ NOT FOR REPLICATION ]
#各参数说明如下:
REFERENCES
指定要建立关联的表的信息。
ref_table
指定要建立关联的表的名称。
ref_column
指定要建立关联的表中的相关列的名称。
ON DELETE {CASCADE | NO ACTION}
指定在删除表中数据时,对关联表所做的相关操作。在子表中有数据行与父表中的对应数据行相关联的情况下,如果指定了值CASCADE,则在删除父表数据行时会将子表中对应的数据行删除;如果指定的是NO ACTION,则SQL Server 会产生一个错误,并将父表中的删除操作回滚。NO ACTION 是缺省值。
ON UPDATE {CASCADE | NO ACTION}
指定在更新表中数据时,对关联表所做的相关操作。在子表中有数据行与父表中的对应数据行相关联的情况下,如果指定了值CASCADE,则在更新父表数据行时会将子表中对应的数据行更新;如果指定的是NO ACTION,则SQL Server 会产生一个错误,并将父表中的更新操作回滚。NO ACTION 是缺省值。
NOT FOR REPLICATION
指定列的外关键字约束在把从其它表中复制的数据插入到表中时不发生作用。
#例子:
CREATE TABLE [dbo].[UserOrder](
[OrderId] [int] NOT NULL,
[UserId] [int] NOT NULL,
[UserName] [nvarchar](50) NOT NULL,
CONSTRAINT fk_userid_username FOREIGN KEY([UserId],[UserName]) REFERENCES UserInfo(UserId,UserName) ON DELETE CASCADE,
) ON [PRIMARY]
3、惟一性约束
惟一性约束指定一个或多个列的组合的值具有惟一性,以防止在列中输入重复的值。惟一性约束指定的列可以有NULL 属性。由于主关键字值是具有惟一性的,因此主关键字列不能再设定惟一性约束。惟一性约束最多由16 个列组成
#定义惟一性约束的语法如下:
CONSTRAINT constraint_name
UNIQUE [CLUSTERED | NONCLUSTERED]
(column_name1[, column_name2,…,column_name16])
#l例子:
create table employees (
emp_id char(8),
emp_name char(10) ,
emp_cardid char(18),
constraint pk_emp_id primary key (emp_id),
constraint uk_emp_cardid unique (emp_cardid)
) on [primary]
4、检查约束
检查约束对输入列或整个表中的值设置检查条件,以限制输入值,保证数据库的数据完整性。可以对每个列设置复合检查。
#定义检查约束的语法如下:
CONSTRAINT constraint_name
CHECK [NOT FOR REPLICATION]
(logical_expression)
#各参数说明如下:
NOT FOR REPLICATION
指定检查约束在把从其它表中复制的数据插入到表中时不发生作用。
logical_expression
指定逻辑条件表达式返回值为TRUE 或FALSE。
#例子:
create table orders(
order_id char(8),
p_id char(8),
p_name char(10) ,
quantity smallint,
constraint pk_order_id primary key (order_id),
constraint chk_quantity check (quantity>=10) ,
) on [primary]
注意:对计算列不能作除检查约束外的任何约束。
5、缺省约束
缺省约束通过定义列的缺省值或使用数据库的缺省值对象绑定表的列,来指定列的缺省值。SQL Server 推荐使用缺省约束,而不使用定义缺省值的方式来指定列的缺省值。
#定义缺省约束的语法如下:
CONSTRAINT constraint_name
DEFAULT constant_expression [FOR column_name]
#例子:
CREATE TABLE [dbo].[Students](
[Id] [int] NOT NULL,
[Name] [nchar](10) NULL,
[Age] [int]
) ON [PRIMARY] GO
ALTER TABLE [dbo].[Students] ADD DEFAULT ('未知') FOR [Name]
GO
alter table [dbo].[Students] add Sex char(2) default '男' alter table [dbo].[Students] add constraint DF_age_Students default(20) for age
6、列约束和表约束
对于数据库来说,约束又分为列约束(Column Constraint)和表约束(Table Constraint)。
列约束作为列定义的一部分只作用于此列本身。表约束作为表定义的一部分,可以作用于
多个列。
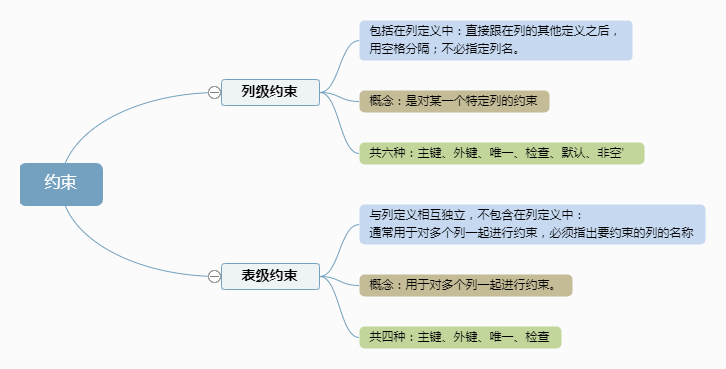
由上图可知,1,主键、外键、唯一、检查这四项,既可以创建列约束,也可以创建表约束。而缺省 和 非空只能创建列约束。
例子:
create table productsss (
p_id char(8) ,
p_name char(10) ,
price money default 0.01 ,
quantity smallint check (quantity>=10) , /* 列约束 */
constraint pk_p_id_name primary key (p_id, p_name) /* 表约束 */
)
7、关于约束的其他操作
#删除约束
ALTER TABLE employees DROP CONSTRAINT emp_manager_fk;
#关闭约束
ALTER TABLE employees DISABLE CONSTRAINT emp_emp_id_pk CASCADE; //如果没有被引用则不需CASCADE关键字
#打开约束
ALTER TABLE employees
ENABLE CONSTRAINT emp_emp_id_pk; //注意,打开一个先前关闭的被引用的主键约束,并不能自动打开相关的外部键约束
注:
1. 添加主键约束会自动创建唯一索引。如果表中尚未创建 聚焦索引,则自动创建聚焦唯一索引。如果表中已存在聚焦索引,则自动创建非聚焦索引。
2. 添加唯一约束会自动创建唯一索引。如果未在unique关键字后加上[nonclustered|clustered],则默认会创建非聚焦索引。
参考:
https://blog.csdn.net/shuohuameijiang/article/details/7275716
https://www.cnblogs.com/cyxdn/p/8509082.html
【SQL】数据库中的五种约束的更多相关文章
- Oracle--数据库中的五种约束
数据库中的五种约束 数据库中的五种约束及其添加方法 五大约束 1.--主键约束(Primay Key Coustraint) 唯一性,非空性 2.--唯一约束 (Unique Counstraint ...
- SQLServer 中有五种约束, Primary Key 约束、 Foreign Key 约束、 Unique 约束、 Default 约束和 Check 约束
一直在关注软件设计方面,数据库方面就忽略了很多,最近在设计数据库时遇到了一些小麻烦,主要是数据库中约束和性能调优方面的应用,以前在学习 Sql Server 2000,还有后来的 Sql Server ...
- 理解ORM的前提:数据库中的范式和约束
理解ORM的前提:数据库中的范式和约束 一.数据库中的范式: 范式, 英文名称是 Normal Form,它是英国人 E.F.Codd(关系数据库的老祖宗)在上个世纪70年代提出关系数据库模型后总结出 ...
- SQL数据库中临时表、临时变量和WITH AS关键词创建“临时表”的区别
原文链接:https://www.cnblogs.com/zhaowei303/articles/4204805.html SQL数据库中数据处理时,有时候需要建立临时表,将查询后的结果集放到临时表中 ...
- 分布式SQL数据库中部分索引的好处
在优锐课的java学习分享中,探讨了分布式SQL数据库中部分索引的优势,并探讨了性能测试,结果等. 如果使用局部索引而不是常规索引,则在可为空的列上(其中只有一小部分行的该列不具有空值),然后可以大大 ...
- SQL Server 中的6种事务隔离级别简单总结
本文出处:http://www.cnblogs.com/wy123/p/7218316.html (保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错 ...
- DB2有五种约束
DB2有五种约束: NOT NULL 约束是这样一种规则,它防止在表的一列或多列中输入空值. 唯一约束(也称为唯一键约束)是这样一种规则,它禁止表的一列或多列中出现重复值.唯一键和主键是受支持的唯一约 ...
- Odoo中的五种Action详解
转载请注明原文地址:https://www.cnblogs.com/ygj0930/p/10826232.html Odoo中的五种action都是继承自ir.actions.actions模型实现的 ...
- Linux 中的五种 IO 模型
Linux 中的五种 IO 模型 在正式开始讲Linux IO模型前,比如:同步IO和异步IO,阻塞IO和非阻塞IO分别是什么,到底有什么区别?不同的人在不同的上下文下给出的答案是不同的.所以先限定一 ...
随机推荐
- LIRE图片识别搜索demo--Ubuntu开发
Ubuntu安装shadowsocks客户端/服务端教程 1.安装shadowsocks sudo apt-get update sudo apt-get install python-pip sud ...
- mybatis,mysql批量delete多个记录
1.dao 接口中 Integer delete(List<UserDeviceRela> relas); 2.xml <delete id="delete" p ...
- [Codeforces741D]Arpa's letter-marked tree and Mehrdad's Dokhtar-kosh paths——dsu on tree
题目链接: Codeforces741D 题目大意:给出一棵树,根为$1$,每条边有一个$a-v$的小写字母,求每个点子树中的一条最长的简单路径使得这条路径上的边上的字母重排后是一个回文串. 显然如果 ...
- 洛谷P1360 [USACO07MAR]黄金阵容均衡题解
题目 不得不说这个题非常毒瘤. 简化题意 这个题的暴力还是非常好想的,完全可以过\(50\%\)的数据.但是\(100\%\)就很难想了. 因为数据很大,所以我们需要用\(O(\sqrt n)\)的时 ...
- 【XSY2731】Div 数论 杜教筛 莫比乌斯反演
题目大意 定义复数\(a+bi\)为整数\(k\)的约数,当且仅当\(a\)和\(b\)为整数且存在整数\(c\)和\(d\)满足\((a+bi)(c+di)=k\). 定义复数\(a+bi\)的实部 ...
- Nagios 监控 Httpd 并发数插件
工作需要监控Httpd并发数,找不到合适的插件,花时间研究了一下Nagios监控内存的脚本,做了一些修改,完成了脚本.监控内存脚本:http://www.cnblogs.com/Mrhuangrui/ ...
- 【BZOJ5213】[ZJOI2018]迷宫(神仙题)
[BZOJ5213][ZJOI2018]迷宫(神仙题) 题面 BZOJ 洛谷 题解 首先可以很容易的得到一个\(K\)个点的答案. 构建\(K\)个点分别表示\(mod\ K\)的余数.那么点\(i\ ...
- [JLOI2016/SHOI2016]侦察守卫(树形dp)
小R和B神正在玩一款游戏.这款游戏的地图由N个点和N-1条无向边组成,每条无向边连接两个点,且地图是连通的.换句话说,游戏的地图是一棵有N个节点的树. 游戏中有一种道具叫做侦查守卫,当一名玩家在一个点 ...
- Pro Git
1.安装 Linux: $ yum install git $ apt-get install git windows: 打开 http://git-scm.com/download/win,下载会自 ...
- prufer序列学习笔记
prufer序列是一个定义在无根树上的东西. 构造方法是:每次选一个编号最小的叶子结点,把他的父亲的编号加入到序列的最后.然后删掉这个叶节点.直到最后只剩下两个节点,此时得到的序列就是prufer序列 ...