ADNI数据
数据的模态有
Clinical Data(临床数据)
Genetic(基因数据)
MRI
PET
BIOSPECIMEN(生物样本)
各模态数据的内容、特点
Clinical Data
内容: 招聘、人口统计、体检和认知评估数据。完整的临床数据集可以作为逗号分隔值(CSV)文件批量下载
基因数据
内容: 受试者的基因分型和测序数据,数据格式:CSV,VCF,BAM
基因分型数据:
APOE Genotyping -- CSV
TOMM40 PolyT Variant -- CSV
全基因组测序数据:
WGS (GATK Call) SNV + Indel -- VCF
WGS (CASAVA Call) SNV -- VCF
Sequenced alignment data -- BAM(不可直接下载)
存在VCF数据,不过数据量都较大,是以G为单位的
VCF数据完整的表现应为:
Record(CHROM, POS, ID, REF, ALT, QUAL, FILTER, INFO, FORMAT, sample_indexes, samples=None)
其中:
- CHROM:染色体名称,类型为str
- POS:位点在染色体上的位置,类型为int
- ID:一般是突变的rs号,类型为str。如果是‘.’,则为None
- REF:参考基因组在该位点上的碱基,类型为str
- ALT:在该位点的测序结果。是_AltRecord类的子类实例的列表。类型为list。_AltRecord类有4个子类,代表了突变的几种类型:如snp,indel,structual variants等。所有的实例都可以进行比较(仅限于相等的比较,没有大于小于之说),部分子类没有实现str方法,也就是说不能转成字符串
- QUAL:该位点的测序质量,类型为int或float
- FILTER:过滤信息。将FILTER列按分号分隔形成的字符串列表,类型为list。如果未给出参数则为None
- INFO:该位点的一些测试指标。将‘=’前的参数作为键,后面的参数作为值,构建成的字典。类型为dict
- FORMAT:基因型信息。保存vcf的FORMAT列的原始形式,类型为str
现下载了一个较小的文件,数据量为:39.5 M(不知道当时是怎么找到的了),里面的信息以条为单位,其中前十记录表现为:
Record(CHROM=gi|251831106|ref|NC_012920.1|, POS=3, REF=T, ALT=[C])
Record(CHROM=gi|251831106|ref|NC_012920.1|, POS=41, REF=C, ALT=[T])
Record(CHROM=gi|251831106|ref|NC_012920.1|, POS=42, REF=T, ALT=[TC])
Record(CHROM=gi|251831106|ref|NC_012920.1|, POS=55, REF=T, ALT=[C])
Record(CHROM=gi|251831106|ref|NC_012920.1|, POS=56, REF=A, ALT=[AC])
Record(CHROM=gi|251831106|ref|NC_012920.1|, POS=57, REF=T, ALT=[C, G])
Record(CHROM=gi|251831106|ref|NC_012920.1|, POS=64, REF=C, ALT=[T])
Record(CHROM=gi|251831106|ref|NC_012920.1|, POS=72, REF=T, ALT=[C, G])
Record(CHROM=gi|251831106|ref|NC_012920.1|, POS=73, REF=A, ALT=[G])
Record(CHROM=gi|251831106|ref|NC_012920.1|, POS=75, REF=G, ALT=[A])
Record(CHROM=gi|251831106|ref|NC_012920.1|, POS=93, REF=A, ALT=[G])
读取方式
import vcf
import os
vcf_file = "adni_mito_genomes.vcf"
vcf_reader = vcf.Reader(filename=vcf_file)
i = 0
for record in vcf_reader:
print(record)
if i == 10:
break
i += 1
MRI
内容: 原始、预处理和后处理的图像文件,FMRI和DTI
数据格式: MRI(structural, diffusion weighted imaging, perfusion, and resting state sequences)
可得到的图像数据
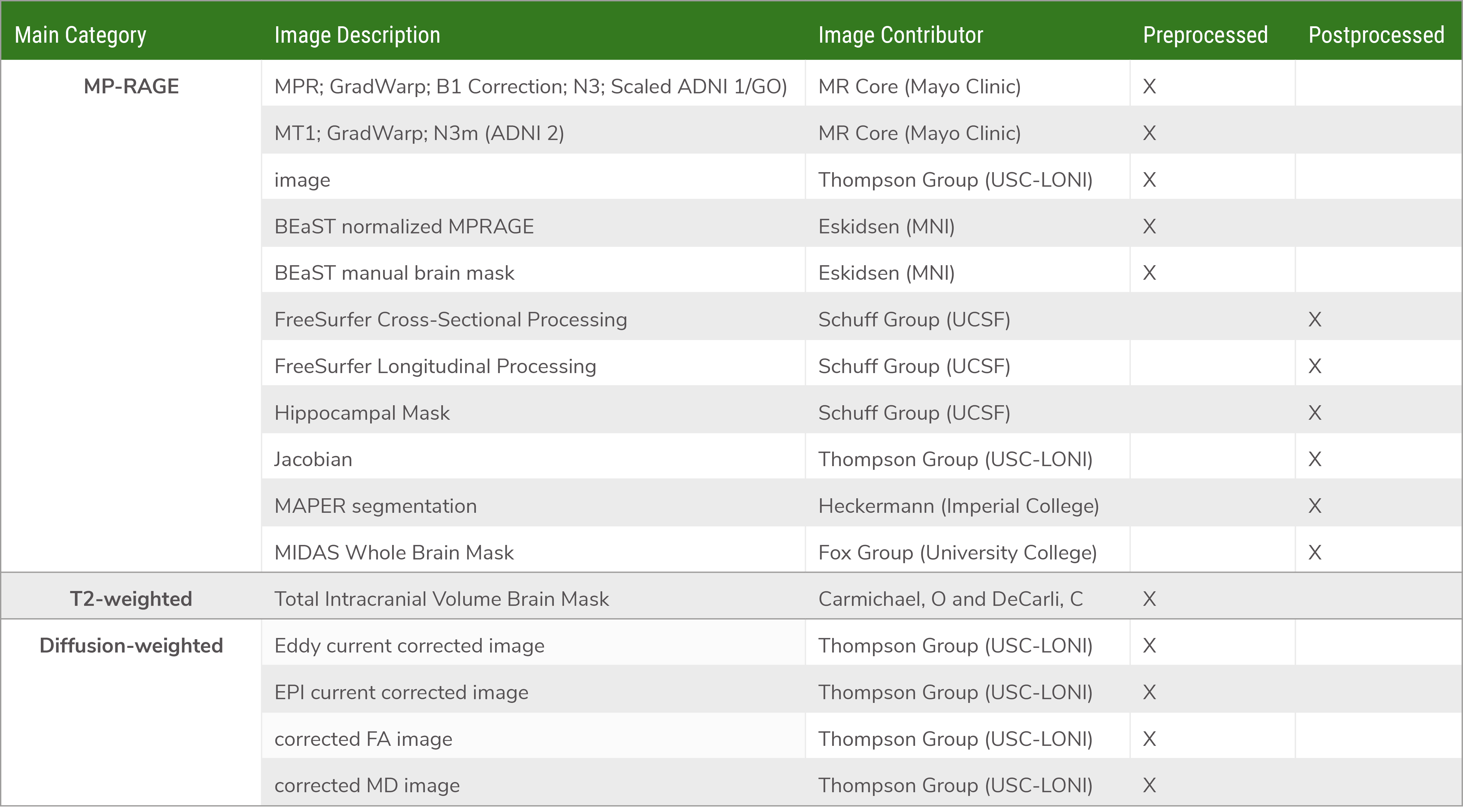
图像示例
下载数据(经过处理)示例:
名字: ADNI1_Complete_2Yr_1.5T
格式: NiFTI
大小: 22.5 M
尺寸: 192 * 192 * 160
类型: T1
制造商: SIEMENS
成像信息:
Acquisition Plane=SAGITTAL; Acquisition Type=3D; Coil=HE; Field Strength=1.5 tesla; Flip Angle=8.0 degree; Manufacturer=SIEMENS; Matrix X=192.0 pixels; Matrix Y=192.0 pixels; Matrix Z=160.0 ; Mfg Model=Symphony; Pixel Spacing X=1.25 mm; Pixel Spacing Y=1.25 mm; Pulse Sequence=IR/GR; Slice Thickness=1.2000000476837158 mm; TE=3.609999895095825 ms; TI=1000.0 ms; TR=3000.0 ms; Weighting=T1
使用Mango可直接显示图片,效果如下
名字:ADNI1_Baseling_3T
格式:NiFTI
大小:22.5 M
尺寸: 192 * 192 * 160
制造商: GE MEDICAL SYSTEMS
类型: T1
成像信息:
Acquisition Plane=SAGITTAL; Acquisition Type=3D; Coil=8HRBRAIN; Field Strength=3.0 tesla; Flip Angle=8.0 degree; Manufacturer=GE MEDICAL SYSTEMS; Matrix X=256.0 pixels; Matrix Y=256.0 pixels; Matrix Z=166.0 ; Mfg Model=SIGNA EXCITE; Pixel Spacing X=1.0156199932098389 mm; Pixel Spacing Y=1.0156199932098389 mm; Pulse Sequence=RM; Slice Thickness=1.2000000476837158 mm; TE=2.8399999141693115 ms; TI=900.0 ms; TR=6.616000175476074 ms; Weighting=T1
使用Mango可直接显示图片,效果如下

ADNI中的扫描是在两种不同的特斯拉扫描仪上进行的,即飞利浦医疗系统和西门子
飞利浦医疗系统扫描的EPI序列为144个体积,场强=3.0特斯拉,翻转角=80.0°,TE=30.0ms,TR=3000.0ms,64×65矩阵,6720.0层厚度为3.31mm的静止状态fMRI
用飞利浦医学系统扫描仪进行扩展静息状态fMRI的EPI序列为:200体积,场强=3.0tesla,翻转角=90.0°,TE=30.0ms,TR=3000.0,64×65矩阵,9600.0层厚3.31mm
对于西门子扫描仪,EPI序列是197个体积,场强=3.0特斯拉,翻转角=80.0度,TE=30.0ms,TR=2999.99,448×448矩阵,以及197个3.4mm厚度的切片
(此处显示的信息与下载的经过处理的信息TE不一致)
python代码示例
import skimage.io as io
import nibabel as nib
import numpy as np
import random
nii_file = "1.nii"
img = nib.load(nii_file)
img_arr = img.get_fdata()
img_arr = np.squeeze(img_arr)
#随机选取一张图片
img_arr1 = img_arr[:, :, random.randint(0, img_arr.shape[2])]
# 数据归一化至[0,1]
print(img_arr.shape)
img_arr1 = (img_arr1 - np.min(img_arr)) / (np.max(img_arr) - np.min(img_arr))
io.imshow(img_arr1)
io.show()
注:只能找到T1的图像,T2的未找到
PET
特点:该数据的目标是跟踪老年痴呆症的恶化和潜在的病理变化
可得到的数据
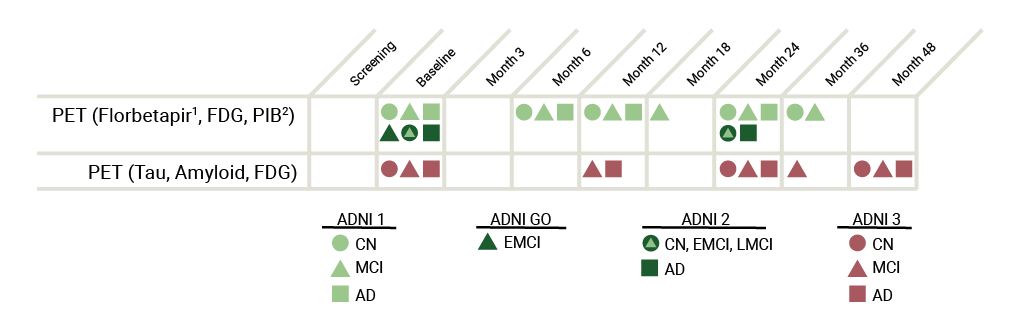
图像示例
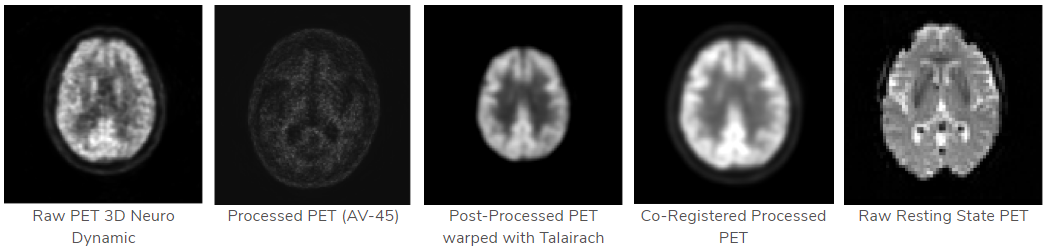
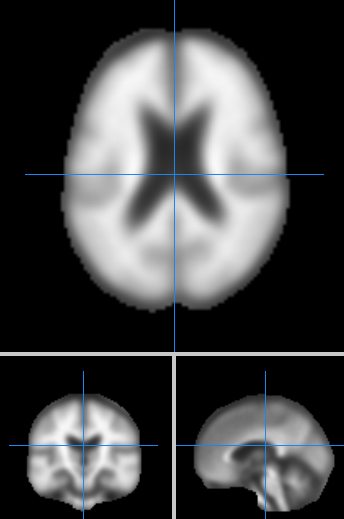
下载的数据:
单个图片大小:3.44 M
格式: NiFTI
尺寸: 91 * 109 * 91
使用Mango可直接显示图片,效果如下
BIOSPECIMEN(生物样本)
内容:血液、尿液和脑脊液(CSF)等生物标本
ADNI数据的更多相关文章
- ADNI数据和样例
ADNI临床数据集: 由各个学科的临床信息组成,包括招募.人口统计特征.体格检查和认知评估数据 所收集的临床数据: 基因数据: ILLUMINA SNP基因分型检测 ADNI的一个关键目标就是为研究人 ...
- study design of ADNI
AD(Alzheimers disease):不可逆的神经退化,患病人员会由于脑部问题的恶化而导致心智功能不健全. ADNI:阿尔茨海默氏症神经成像项目 ADNI的总体目标是验证用于阿尔茨海默病临床 ...
- ADNI以及study design简介
相关名词: MCI:轻度认知功能障碍 EMCI:早期认知障碍 MCI:轻度认知障碍 LMCI:晚期认知障碍 CN:认知正常的志愿者 DTI:doppler tissue imaging,多普勒组织显像 ...
- AD预测论文研读系列1
A Deep Learning Model to Predict a Diagnosis of Alzheimer Disease by Using 18F-FDG PET of the Brain ...
- Dicom图像解析
医疗图像解析 Dicom 后缀: .dcm..DCM Dicom中规定的坐标系是以人坐标系为绝对坐标系的,规定X轴正向指向病人的左侧,Y轴正向指向病人的背部,Z轴正向指向病人的头部.但是,坐标点的位置 ...
- niftynet Demo分析 -- brain_parcellation
brain_parcellation 论文详细介绍 通过从脑部MR图像中分割155个神经结构来验证该网络学习3D表示的效率 目标:设计一个高分辨率和紧凑的网络架构来分割体积图像中的精细结构 特点:大多 ...
- AD阶段分类论文阅读笔记
A Deep Learning Pipeline for Classifying Different Stages of Alzheimer's Disease from fMRI Data -- Y ...
- ADNI数据集相关概念整理
数据类型 临床 遗传 MRI图像 PET图像 生物样本 临床 ADNI临床数据集包括关于每个受试者的临床信息,包括招募,人口统计学,身体检查和认知评估数据.可以将整套临床数据作为逗号分隔值(CSV)文 ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
随机推荐
- AVH IP网络广播系统
AVH IP网络广播系统特点: IP网络广播系统是基于当前已广泛使用的以太网网络平台,充分利用网络平台,如用户处已有网络平台,则无需再布线,完全不同于纯模拟广播.调频寻址广播和数控广播 ...
- Spring MVC 中的输入验证 Vlidator
在 Spring MVC 中有两种方式可以验证输入:1. Spring 自带的验证框架:2. 利用 JSR 303 实现,即 Java Specification Requests Converter ...
- php上传多张图片
第一种:加后缀 代码实现(就是普通的上传图片,只是在外面加个foreach循环) $allow_file_types = '|GIF|JPG|PNG|BMP|SWF|DOC|XLS|PPT|MID|W ...
- 字符编码中ASCII、Unicode和UTF-8的区别
1. ASCII码 我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串.每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte). ...
- E: Sub-process /usr/bin/dpkg returned an error code
E: Sub-process /usr/bin/dpkg returned an error code (1)错误解决 在用apt-get安装软件时出现了类似于install-info: No dir ...
- Python(四) 列表元组
- MySQL中Decimal类型和Float Double等区别
MySQL中存在float,double等非标准数据类型,也有decimal这种标准数据类型. 其区别在于,float,double等非标准类型,在DB中保存的是近似值,而Decimal则以字符串的形 ...
- JAVA 8 主要新特性 ----------------(四)Lambda函数式接口
一.什么是函数式接口 只包含一个抽象方法的接口,称为函数式接口. 你可以通过 Lambda 表达式来创建该接口的对象.(若 Lambda 表达式抛出一个受检异常,那么该异常需要在目标接口的抽象方法 ...
- Xutils简
//解析 private void myinitData() { RequestParams parms=new RequestParams("http://huixinguiyu.cn/A ...
- HTK计算mfcc/filter_bank源码解析
HTK计算mfcc/filter_bank源码解析 HTK可以用简单的 HCopy -C config -s scp 求取mfcc或者filter_bank 关于mfcc的原理在 http://my. ...