Python之随机梯度下降
实现:
# -*- coding: UTF-8 -*-
"""
练习使用随机梯度下降算法
"""
import numpy as np
import math __author__ = 'zhen'
# 生成测试数据
x = 2 * np.random.rand(100, 1) # 随机生成100*1的二维数组,值分别在0~2之间 y = 4 + 3 * x + np.random.randn(100, 1) # 随机生成100*1的二维数组,值分别在4~11之间 x_b = np.c_[np.ones((100, 1)), x]
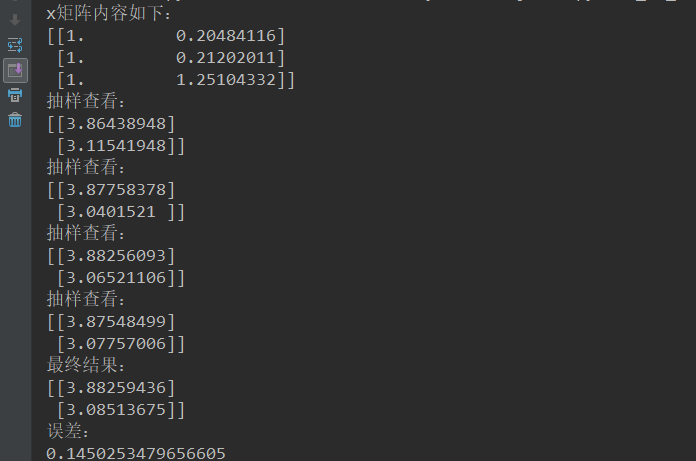
print("x矩阵内容如下:\n{}".format(x_b[0:3]))
n_epochs = 100
t0, t1 = 1, 10 m = n_epochs
def learning_schedule(t): # 模拟实现动态修改步长
return t0 / (t + t1) theta = np.random.randn(2, 1) for epoch in range(n_epochs):
for i in range(m):
random_index = np.random.randint(m)
x_i = x_b[random_index:random_index+1]
y_i = y[random_index:random_index+1]
gradients = 2 * x_i.T.dot(x_i.dot(theta)-y_i) # 调用公式
learning_rate = learning_schedule(epoch * m + i)
theta = theta - learning_rate * gradients if epoch % 30 == 0:
print("抽样查看:\n{}".format(theta))
print("最终结果:\n{}".format(theta))
# 计算误差
error = math.sqrt(math.pow((theta[0][0] - 4), 2) + math.pow((theta[1][0] - 3), 2))
print("误差:\n{}".format(error))
结果:
Python之随机梯度下降的更多相关文章
- python机器学习——随机梯度下降
上一篇我们实现了使用梯度下降法的自适应线性神经元,这个方法会使用所有的训练样本来对权重向量进行更新,也可以称之为批量梯度下降(batch gradient descent).假设现在我们数据集中拥有大 ...
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比[转]
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- 【转】 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- 机器学习-随机梯度下降(Stochastic gradient descent)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 对数几率回归法(梯度下降法,随机梯度下降与牛顿法)与线性判别法(LDA)
本文主要使用了对数几率回归法与线性判别法(LDA)对数据集(西瓜3.0)进行分类.其中在对数几率回归法中,求解最优权重W时,分别使用梯度下降法,随机梯度下降与牛顿法. 代码如下: #!/usr/bin ...
- 机器学习-随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- 梯度下降之随机梯度下降 -minibatch 与并行化方法
问题的引入: 考虑一个典型的有监督机器学习问题,给定m个训练样本S={x(i),y(i)},通过经验风险最小化来得到一组权值w,则现在对于整个训练集待优化目标函数为: 其中为单个训练样本(x(i),y ...
- batch gradient descent(批量梯度下降) 和 stochastic gradient descent(随机梯度下降)
批量梯度下降是一种对参数的update进行累积,然后批量更新的一种方式.用于在已知整个训练集时的一种训练方式,但对于大规模数据并不合适. 随机梯度下降是一种对参数随着样本训练,一个一个的及时updat ...
- AI 随机梯度下降(SGD)
随机梯度下降(stochastic gradient descent) 梯度是期望 计算梯度耗时太长
随机推荐
- [视频]K8飞刀 Discuz csrf Exp教程
[视频]K8飞刀 一键构造Discuz csrf Exp教程 链接:https://pan.baidu.com/s/1tVseP_ZBneKpXQueIncPcA 提取码:6qnh
- python 牛客网 你的输出为:空。请检查一下你的代码,有没有循环输入处理多个case。问题解决
你的输出为:空.请检查一下你的代码,有没有循环输入处理多个case.点击查看如何处理多个case 核心:他这个程序测试正确与否的流程是 连续输入多组测试数据进行测试,只有每组数据都对才行 所以必须使用 ...
- linux中一些简便的命令之tr
tr是个简单字符处理命令,主要有以下几个用法: 1.替换字符: echo "hello,world" | tr 'a-z' 'A-Z' 执行结果:HELLO,WORLD 注释:这里 ...
- Linux学习笔记之一————什么是Linux及其应用领域
1.1认识Linux 1)什么是操作系统 2)现实生活中的操作系统 win7 Mac Android iOS 3) 操作系统的发展史 (1)Unix 1965年之前的时候,电脑并不像现在一样普遍,它 ...
- NetMQ 发布订阅模式 Publisher-Subscriber
第一部分引用于:点击打开 1:简单介绍 PUB-SUB模式一般处理的都不是系统的关键数据.发布者不关注订阅者是否收到发布的消息,订阅者也不知道自己是否收到了发布者发出的所有消息.你也不知道订阅者何时开 ...
- vi常用命令总结
1. 打开文件 > vi 文件 //该模式是命令模式 2. 尾行模式操作 > :q //该模式是“尾行模式” > :w //保存已经修改的文档 > :wq //保存并退出 &g ...
- Session会话保持机制的原理与Tomcat Session共享的几种实现方式(Session Cluster、memcached+MSM)
一.Session的定义 在计算机科学中,特别是在网络中,session是两个或更多个通信设备之间或计算机和用户之间的临时和交互式信息交换.session在某个时间点建立,然后在之后的某一时间点拆除. ...
- 记一次安装Nginx+php-fpm安装后无法解析.php文件,状态码200,但显示空白页
安装环境: Nginx:Nginx1.12.2 PHP:PHP 7.2 系统:CentOS 7.4 安装方式: Nginx与PHP都是yum安装的,具体步骤: 1.安装epel源再安装Nginx: r ...
- VirtualBox centos7扩容
有时候扩容还真不如重新建立一个大硬盘的系统,但是如果你安装了好多东西的话,那还是来扩容一下吧. 查看磁盘格式 在virtualBox中右键点击虚拟机->设置->存储,如 ...
- [转]【Angular4】基础(一):脚手架 Angular CLI
本文转自:https://blog.csdn.net/u013451157/article/details/79444495 版权声明:本文为博主原创文章,未经博主允许不得转载. https://bl ...