Python词云(词频统计,掩膜显示)
Python2.7 anaconda。安装Wordcloud,网上有许多下载路径,说一下掩模,就是在这个膜的区域才会有东西,当然这个与实际的掩模还有一定区别,这个词频显示是把所有统计的词,显示在这个掩模图片的非白色区域。
(接下来就不用看着网上那些小软件很羡慕,其实代码就十行左右,你也可以)
from os import path
from scipy.misc import imread
import matplotlib.pyplot as plt from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator # 获取当前文件路径
# __file__ 为当前文件, 在ide中运行此行会报错,可改为
# d = path.dirname('.')
d = path.dirname(__file__) #
text = open(path.join(d, 't.txt')).read() # 设置背景图片,也就是掩膜图像,在非白色部分我们的统计好的词频会显示在这里
alice_coloring = imread(path.join(d, "b.jpg")) wc = WordCloud(background_color="white", #背景颜色
#max_words=2000,# 词云显示的最大词数
mask=alice_coloring,#设置背景图片
stopwords=STOPWORDS.add("said"),
max_font_size=60, #字体最大值
random_state=50) #上述函数设计了词云格式 # 生成词云, 可以用generate输入全部文本(中文不好分词),也可以我们计算好词频后使用generate_from_frequencies函数
wc.generate(text)
#文本词频统计函数,本函数自动统计词的个数,以字典形式内部存储,在显示的时候词频大的,字体也大 # 从背景图片生成颜色值
image_colors = ImageColorGenerator(alice_coloring) # 以下代码显示图片 plt.figure()
# recolor wordcloud and show
# we could also give color_func=image_colors directly in the constructor
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis("off")
# 绘制背景图片为颜色的图片

示例图像,文本分词是直接用的英文(网上随便粘贴一篇英文文章),它是以空格进行分词的。如果是中文也可以用网上推荐的分词器,或者你是做数据分析的,当然就知道怎么分词了。
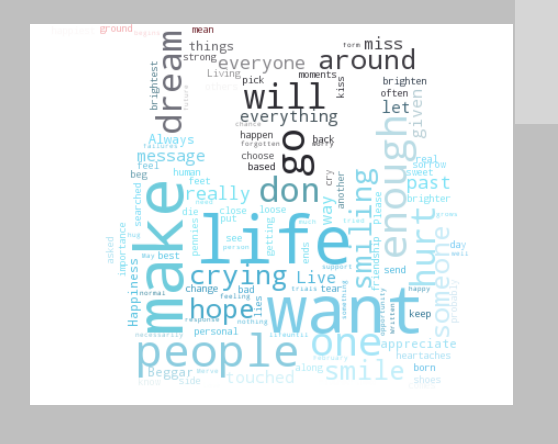
bra................嘿嘿嘿
图片背景色为白色,分清图片背景,和掩模,和掩模背景色(函数默认的是白色区域)
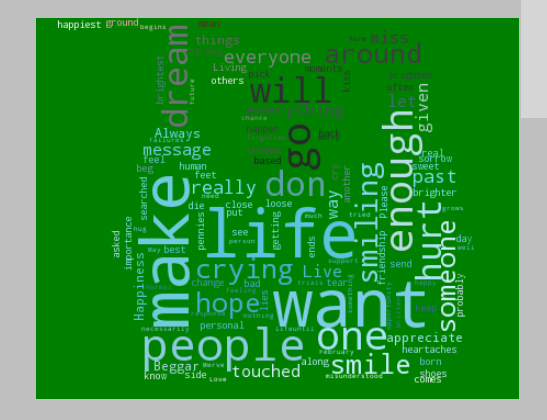
词频分析,数据分析挖掘。
以后再PPT中也可以用啦!!!!!!!!!!!!!!!!!
Python词云(词频统计,掩膜显示)的更多相关文章
- 利用python实现简单词频统计、构建词云
1.利用jieba分词,排除停用词stopword之后,对文章中的词进行词频统计,并用matplotlib进行直方图展示 # coding: utf-8 import codecs import ma ...
- python词云生成-wordcloud库
python词云生成-wordcloud库 全文转载于'https://www.cnblogs.com/nickchen121/p/11208274.html#autoid-0-0-0' 一.word ...
- 用Python实现一个词频统计(词云+图)
第一步:首先需要安装工具python 第二步:在电脑cmd后台下载安装如下工具: (有一些是安装好python电脑自带有哦) 有一些会出现一种情况就是安装不了词云展示库 有下面解决方法,需看请复制链接 ...
- Python 词云可视化
最近看到不少公众号都有一些词云图,于是想学习一下使用Python生成可视化的词云,上B站搜索教程的时候,发现了一位UP讲的很不错,UP也给出了GitHub上的源码,是一个很不错的教程,这篇博客主要就是 ...
- python 词云小demo
词云小demo jiebawordcloud 一 什么是词云? 由词汇组成类似云的彩色图形.“词云”就是对网络文本中出现频率较高的“关键词”予以视觉上的突出,形成“关键词云层”或“关键词渲染”,从而过 ...
- Python字典使用--词频统计的GUI实现
字典是针对非序列集合而提供的一种数据类型,字典中的数据是无序排列的. 字典的操作 为字典增加一项 dict[key] = value students = {"Z004":&quo ...
- Python 词云 【中/英】小白简单入门教程
1. 分析 构建词云需要具备: 原料即文章等内容 将内容进行分词 将分词后的内容利用构建词云的工具进行构建 保存成图片 2. 需要的主要模块 jieba 中文分词 wordcloud 构建词云 3. ...
- Python词云生成
一.目的 1. 熟悉jieba库和wordcloud库的使用方法: 2. 熟悉文本词频统计和词云生成的基本方法. 二.内容 1. 从网上自行下载一个长篇英文小说,统计并输出该小说中词频最大的TOP 2 ...
- python词云的制作方法
第一次接触到词云主要是觉得很好看,就研究了一下,官方给出了代码的,但是新手看的话还是有点不容易,我们来尝试下吧. 环境:python2.7 python库:PIL(pillow),numpy,matp ...
随机推荐
- xlwt模块
python使用xlwt模块操作Excel 该模块安装很简单 $ pip install xlwt 语法 import xlwt # 创建一个workbook 设置编码 workbook = xlwt ...
- django 认证模块auth,表单组件form
django认证系统(auth): 1.首先我们在新窗口中打开一个django项目,之后点击,
- Context namespace element 'annotation-config' and its parser class [org.springframework.context.annotation.AnnotationConfigBeanDefinitionParser] are only available on JDK 1.5 and higher
Context namespace element 'annotation-config' and its parser class [org.springframework.context.anno ...
- 2018SDIBT_国庆个人第二场
A.codeforces1038A You are given a string ss of length nn, which consists only of the first kk letter ...
- Lazarus 中文汉字解决方案
使用Lazarus不得不面对编码问题,尤其中文.Lazarus使用的是UTF8编码,而很多windows程序使用的是ANSI编码,编码问题在此不多说大家可以google去. ANSI数据库与Lazar ...
- weka连接mysql数据库
一.下载并解压数据库驱动 下载地址:http://www.mysql.com/products/connector/,本文下载 mysql-connector-java-5.0.8.zip.将解压后的 ...
- 一个有趣的nginx问题引发的小问题
最近处理一个nginx问题,故障现象是:所有的work进程,都在等锁.调用的是sem_wait 根据对应的堆栈,查看一下大家等的锁都一样,看看这把锁被谁拿了: 锁的结构是: typedef struc ...
- JDBC使用步骤分哪几步?
(1) 加载JDBC驱动程序: Cllass.forName(" 驱动程序" ); //你要连接的数据库对象 (2) 建立连接 Connection conn=DriverMa ...
- 基于Java SE集合的图书管理系统
图书管理系统一.需求说明1.功能:登录,注册,忘记密码,管理员管理,图书管理.2.管理员管理:管理员的增删改查.3.图书管理:图书的增删改查.4.管理员属性包括:id,姓名,性别,年龄,家庭住址,手机 ...
- C# 读取ini文件,读不出来原因
先赋上相关读取ini文件代码 public class INIHelper { public string inipath; [DllImport("kernel32")] pri ...