Scrapy爬取携程桂林问答
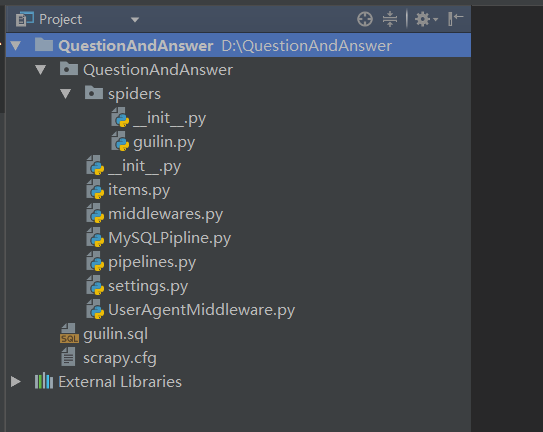
guilin.sql:
CREATE TABLE `guilin_ask` (
`id` INT(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`question` VARCHAR(255) DEFAULT NULL COMMENT '问题的标题',
`full_question` VARCHAR(255) DEFAULT NULL COMMENT '问题的详情',
`keyword` VARCHAR(255) DEFAULT NULL COMMENT '关键字',
`ask_time` VARCHAR(255) DEFAULT NULL COMMENT '提问时间',
`accept_answer` TEXT COMMENT '提问者采纳的答案',
`recommend_answer` TEXT COMMENT '旅游推荐的答案',
`agree_answer` TEXT COMMENT '赞同数最高的答案',
PRIMARY KEY (`id`),
UNIQUE KEY `question` (`question`)
) ENGINE=INNODB DEFAULT CHARSET=utf8 COMMENT='桂林_问答表'
guilin.py:
# -*- coding: utf-8 -*- import scrapy
from scrapy import Request from QuestionAndAnswer.items import QuestionandanswerItem
from pyquery import PyQuery as pq class GuilinSpider(scrapy.Spider):
name = 'guilin'
allowed_domains = ['you.ctrip.com'] def start_requests(self):
# 重写start_requests方法
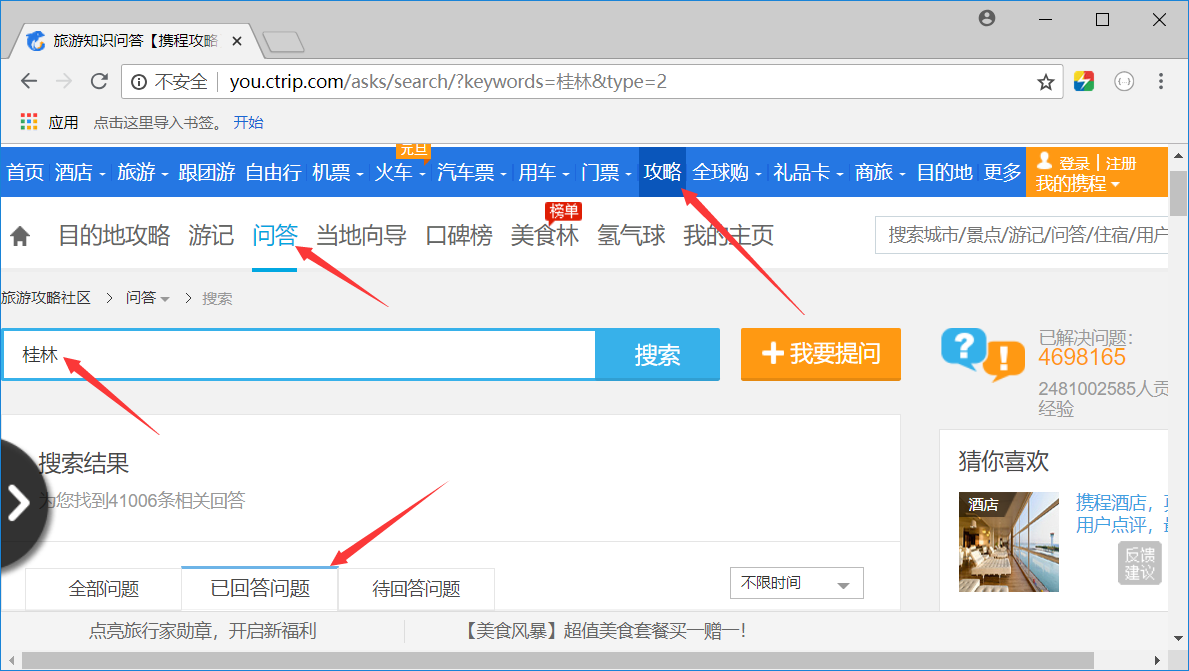
ctrip_url = "http://you.ctrip.com/asks/search/?keywords=%e6%a1%82%e6%9e%97&type=2"
# 携程~攻略~问答~桂林~已回答问题 yield Request(ctrip_url, callback=self.list_page) def list_page(self, response):
result = pq(response.text)
# 调用pyquery.PyQuery
result_list = result(".cf")
# 问题列表
question_urls = []
# 问题链接列表
for ask_url in result_list.items():
question_urls.append(ask_url.attr("href"))
while None in question_urls:
question_urls.remove(None)
# 去除None for url in question_urls:
yield response.follow(url, callback=self.detail_page) result.make_links_absolute(base_url="http://you.ctrip.com/")
# 把相对路径转换成绝对路径
next_link = result(".nextpage")
next_url = next_link.attr("href")
# 下一页
if next_url is not None:
# 如果下一页不为空
yield scrapy.Request(next_url, callback=self.list_page) def detail_page(self, response):
detail = pq(response.text)
question_frame = detail(".detailmain")
# 问答框 for i_item in question_frame.items():
ask = QuestionandanswerItem()
ask["question"] = i_item(".ask_title").text()
ask["full_question"] = i_item("#host_asktext").text()
ask["keyword"] = i_item(".asktag_oneline.cf").text()
ask["ask_time"] = i_item(".ask_time").text().strip("发表于")
ask["accept_answer"] = i_item(".bestanswer_con > div > p.answer_text").text()
ask["recommend_answer"] = i_item(".youyouanswer_con > div > p.answer_text").text()
ask["agree_answer"] = i_item("#replyboxid > ul > li:nth-child(1) > div > p.answer_text").text()
yield ask
items.py:
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class QuestionandanswerItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field() question = scrapy.Field()
# 问题的标题
full_question = scrapy.Field()
# 问题的详情
keyword = scrapy.Field()
# 关键字
ask_time = scrapy.Field()
# 提问时间
accept_answer = scrapy.Field()
# 提问者采纳的答案
recommend_answer = scrapy.Field()
# 旅游推荐的答案
agree_answer = scrapy.Field()
# 赞同数最高的答案
MySQLPipline.py:
from pymysql import connect class MySQLPipeline(object):
def __init__(self):
self.connect = connect(
host='192.168.1.108',
port=3306,
db='scrapy',
user='root',
passwd='Abcdef@123456',
charset='utf8',
use_unicode=True)
# MySQL数据库
self.cursor = self.connect.cursor()
# 使用cursor()方法获取操作游标 def process_item(self, item, spider):
self.cursor.execute(
"""select * from guilin_ask WHERE question = %s""",
item['question'])
# 是否有重复问题
repetition = self.cursor.fetchone() if repetition:
pass
# 丢弃 else:
self.cursor.execute(
"""insert into guilin_ask(
question, full_question, keyword, ask_time, accept_answer, recommend_answer, agree_answer)
VALUE (%s, %s, %s, %s, %s, %s, %s)""",
(item['question'],
item['full_question'],
item['keyword'],
item['ask_time'],
item['accept_answer'],
item['recommend_answer'],
item['agree_answer']
))
# 执行sql语句,item里面定义的字段和表字段一一对应
self.connect.commit()
# 提交
return item
# 返回item def close_spider(self, spider):
self.cursor.close()
# 关闭游标
self.connect.close()
# 关闭数据库连接
Scrapy爬取携程桂林问答的更多相关文章
- 使用requests、re、BeautifulSoup、线程池爬取携程酒店信息并保存到Excel中
import requests import json import re import csv import threadpool import time, random from bs4 impo ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- scrapy爬取西刺网站ip
# scrapy爬取西刺网站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem class Xicispi ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- scrapy爬取极客学院全部课程
# -*- coding: utf-8 -*- # scrapy爬取极客学院全部课程 import scrapy from pyquery import PyQuery as pq from jike ...
- scrapy爬取全部知乎用户信息
# -*- coding: utf-8 -*- # scrapy爬取全部知乎用户信息 # 1:是否遵守robbots_txt协议改为False # 2: 加入爬取所需的headers: user-ag ...
- Scrapy爬取Ajax(异步加载)网页实例——简书付费连载
这两天学习了Scrapy爬虫框架的基本使用,练习的例子爬取的都是传统的直接加载完网页的内容,就想试试爬取用Ajax技术加载的网页. 这里以简书里的优选连载网页为例分享一下我的爬取过程. 网址为: ht ...
- Scrapy爬取静态页面
Scrapy爬取静态页面 安装Scrapy框架: Scrapy是python下一个非常有用的一个爬虫框架 Pycharm下: 搜索Scrapy库添加进项目即可 终端下: #python2 sudo p ...
随机推荐
- [2018HN省队集训D8T1] 杀毒软件
[2018HN省队集训D8T1] 杀毒软件 题意 给定一个 \(m\) 个01串的字典以及一个长度为 \(n\) 的 01? 序列. 对这个序列进行 \(q\) 次操作, 修改某个位置的字符情况以及查 ...
- JS代码高亮编辑器 ace.js
JS代码高亮编辑器 ace.js 字数254 阅读2 评论0 喜欢0 瞎扯 ace 是 js 实现的代码编辑器 编译打包之后的 ACE 代码 官网,未提供编译好的文件 ACE 拥有的特点 语法高亮超过 ...
- Hadoop HA on Yarn——集群配置
集群搭建 因为服务器数量有限,这里服务器开启的进程有点多: 机器名 安装软件 运行进程 hadoop001 Hadoop,Zookeeper NameNode, DFSZKFailoverContro ...
- 洛谷 P4012 深海机器人问题【费用流】
题目链接:https://www.luogu.org/problemnew/show/P4012 洛谷 P4012 深海机器人问题 输入输出样例 输入样例#1: 1 1 2 2 1 2 3 4 5 6 ...
- js等比压缩上传
一.js文件,这个是封装过的,借用了网络上的代码然后修改的 (function(window,undefined){ var upload = function(){ this.init(); }; ...
- vue2.* 事件结合双向数据绑定、模块化以及封装Storage实现todolist 待办事项 已经完成 和进行中持久化 06
ceshi.vue <template> <div id="app"> <input type='text' v-model='todo' @keyd ...
- (转)MySQL高可用方案MHA的部署和原理
背后深层次的逻辑: MHA Node则运行在每个mysql节点上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它自动将最新数据的slave提升为master,然 ...
- 认识BPM
什么是BPM BPM,即业务流程管理,是一种以规范化的构造端到端的卓越业务流程为中心,以持续的提高组织业务绩效为目的的系统化方法,常见商业管理教育如EMBA.MBA等均将BPM包含在内. BPM能干什 ...
- 安装framework 4.6.2的时报错 “无法建立到信任根颁发机构的证书链”
解决方案: 1.下载证书:MicrosoftRootCertificateAuthority2011.cer 2.开始→运行→MMC 3.文件→添加删除管理单元 (Ctrl+M) 4.证书→计算机账户 ...
- C++之指针指向二维数组
一维指针通经常使用指针表示,其指向的地址是数组第一元素所在的内存地址,例如以下 int ary[4][5]; int(*aryp)[5] = ary; 那么ary[4]相当于int(*aryp).下面 ...