实例学习——爬取豆瓣音乐TOP250数据
开发环境:(Windows)eclipse+pydev+MongoDB
豆瓣TOP网址:传送门
一、连接数据库
打开MongoDBx下载路径,新建名为data的文件夹,在此新建名为db的文件夹,db文件夹即用于存储数据
在bin路径下输入配置信息——>mongod --dbpath D:\MongoDB\data\db (此处为存储文件路径)
再打开新的命令行窗口,输入——>mongo
注意:启动服务的命令行窗口不要关闭
打开可视化管理工具Robomongo,点击Connections对话框,在右侧新建connect
保持默认设置,单击save,最后单击Connect即可连接到数据库
### 二、运行爬虫
# -*- coding:utf-8 -*-
import pymongo
from lxml import etree
import re
import requests
import time
client =pymongo.MongoClient('localhost',27017) #创建并连接数据库
mydb = client['mydb']
musictop = mydb['musictop']
headers = {'User=Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'} #请求头
def get_url_music(url): #获得详细url的函数
html = requests.get(url, headers = headers)
selector = etree.HTML(html.text)
music_hrefs = selector.xpath('//a[@class="nbg"]/@href')
for music_href in music_hrefs:
get_music_info(music_href)
def get_music_info(url): #获取详细信息的函数
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
name = selector.xpath('//*[@id="wrapper"]/h1/span/text()')[0] #xpath
author = re.findall('表演者:.*?>(.*?)</a>',html.text,re.S)[0] #正则表达式
styles = re.findall('<span class="pl">流派:</span> (.*?)<br/>',html.text,re.S)
if len(styles)==0:
style = '未知'
else:
style = styles[0].strip()
time = re.findall('发行时间:</span> (.*?)<br/>',html.text,re.S)[0].strip()
publishers = re.findall('出版者:.*?>(.*?)</a>',html.text,re.S)
if len(publishers)==0:
publisher = "未知"
else:
publisher = publishers[0].strip()
score =selector.xpath('//*[@id="interest_sectl"]/div/div[2]/strong/text()')[0]
print(name,author,style,time,publisher,score)
info = {
'name':name,
'author':author,
'style':style,
'time':time,
'publisher':publisher,
'score':score,
}
musictop.insert_one(info)
if __name__=='__main__': #主程序入口
urls = ['https://music.douban.com/top250?start={}'.format(str(i)) for i in range(0,250,25)]
for url in urls:
get_url_music(url)
time.sleep(2)
成果展示:
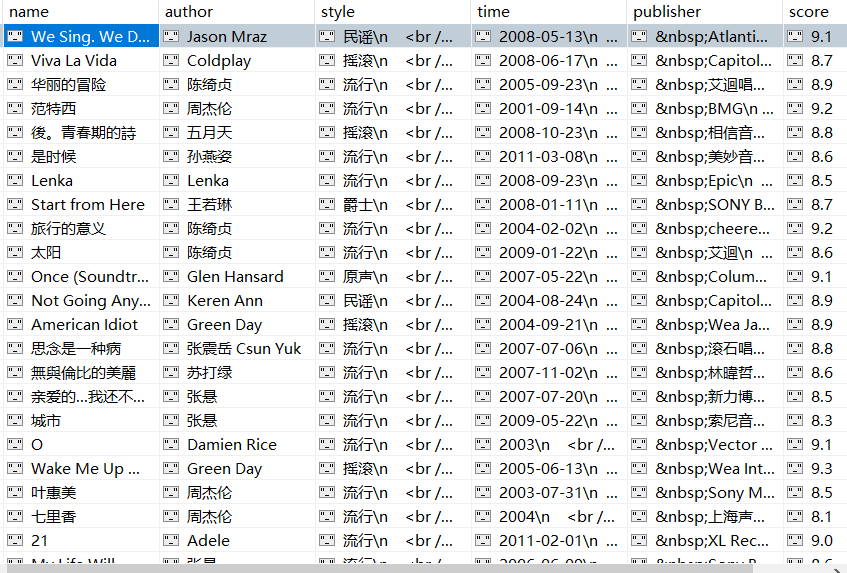
获取author字段信息时,采用正则是因为各详细页中标签位置略有不同,若通过定位标签获取信息,一些详细页信息匹配可能出错。
“表演者”字段在网页源代码中的相对位置是一样,可考虑正则表达式获取信息。
流派、发行时间、出版者信息若用Xpath方式爬取,会数据杂乱,多个标签嵌套,甚至存在乱码符号。
实例学习——爬取豆瓣音乐TOP250数据的更多相关文章
- 实例学习——爬取豆瓣网TOP250数据
开发环境:(Windows)eclipse+pydev 网址:https://book.douban.com/top250?start=0 from lxml import etree #解析提取数据 ...
- Python爬虫小白入门(七)爬取豆瓣音乐top250
抓取目标: 豆瓣音乐top250的歌名.作者(专辑).评分和歌曲链接 使用工具: requests + lxml + xpath. 我认为这种工具组合是最适合初学者的,requests比pytho ...
- 爬取豆瓣音乐TOP250的数据
参考网址:https://music.douban.com/top250 因为详细页的信息更丰富,本次爬虫在详细页中进行,因此先爬取进入详细页的网址链接,进而爬取数据. 需要爬取的信息有:歌曲名.表演 ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- Python爬虫:现学现用xpath爬取豆瓣音乐
爬虫的抓取方式有好几种,正则表达式,Lxml(xpath)与BeautifulSoup,我在网上查了一下资料,了解到三者之间的使用难度与性能 三种爬虫方式的对比. 这样一比较我我选择了Lxml(xpa ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
随机推荐
- poj 2187 Beauty Contest 凸包模板+求最远点对
题目链接 题意:给你n个点的坐标,n<=50000,求最远点对 #include <iostream> #include <cstdio> #include <cs ...
- sh_10_字典基本使用
sh_10_字典基本使用 xiaoming_dict = {"name": "小明"} # 1. 取值 print(xiaoming_dict["na ...
- Python 标准库、第三方库
Python 标准库.第三方库 Python数据工具箱涵盖从数据源到数据可视化的完整流程中涉及到的常用库.函数和外部工具.其中既有Python内置函数和标准库,又有第三方库和工具.这些库可用于文件读写 ...
- confluence 附件docx文件 乱码处理
服务器安装字体库 Fontconfig是一个用于配置和自定义字体访问的库 yum -y install fontconfig 拷贝需要的字体文件 fonts.zip(或自己电脑中的字体文件c:/Win ...
- Unity3D_(网格导航)简单物体自动寻路
NavMesh(导航网络)是3D游戏世界中用于实现动态物体自动寻路的一种技术,它将游戏场景中复杂的结构组织关系简化为带有一定信息的网格,进而在这些网格的基础上通过一系列的计算来实现自动寻路. 实现Ca ...
- Jmeter -- 入门,基础操作
1. 添加线程组 设置线程组参数(线程数.准备时长.循环次数等): a)线程数:虚拟用户数.一个虚拟用户占用一个进程或线程.设置多少虚拟用户数在这里也就是设置多少个线程数. b)Ramp-Up Per ...
- ssm框架文件配置
1 简介 Spring MVC (web level),采取 MVC 架构,意图取代麻烦的 Servlet 写法,简化 web 层 MyBatis (dao level),意图取代 jdbc 操作数据 ...
- winform Timer控件的使用
private void button1_Click(object sender, EventArgs e){ Timer timer1 = new Timer(); timer1.Interval ...
- TensorFlow常用操作
初始化数据: # -*- coding: utf-8 -*- import tensorflow as tf a = tf.zeros([3, 4], tf.int32) # [[0 0 0 0] # ...
- linux系统问题排查
通常linux系统出问题了 先看系统日志 tail -f /var/log/messages