Hadoop之运行模式
Hadoop运行模式包括:本地模式、伪分布式以及完全分布式模式。
一、本地运行模式
1、官方Grep案例
1)在hadoop-2.7.2目录下创建一个 input 文件夹
[hadoop@hadoop101 hadoop-2.7.]$ mkdir input
2)将hadoop的xml配置文件复制到 input
[hadoop@hadoop101 hadoop-2.7.]$ cp etc/hadoop/*.xml input
3)执行share 目录下的MapReduce 程序
[hadoop@hadoop101 hadoop-2.7.]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar grep input output 'dfs[a-z.]+'
4)查看输出结果
[hadoop@hadoop101 hadoop-2.7.]$ cat output/*
2、官方WordCount 案例
1)在hadoop-2.7.2目录下创建一个 wcinput 文件夹
[hadoop@hadoop101 hadoop-2.7.]$ mkdir wcinput
2)在wcinput文件家下创建一个 wc.input 文件
[hadoop@hadoop101 hadoop-2.7.]$ cd wcinput
[hadoop@hadoop101 wcinput]$ touch wc.input
3)编辑 wc.input 文件,输入如下内容
hadoop yarn
hadoop mapreduce
tom
tom
4)回到hadoop目录 /opt/module/hadoop-2.7.2
5)执行程序
[hadoop@hadoop101 hadoop-2.7.]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar wordcount wcinput wcoutput
6)查看结果
[atguigu@hadoop101 hadoop-2.7.]$ cat wcoutput/part-r-
tom
hadoop
mapreduce
yarn
二、伪分布式运行模式
1、启动HDFS并运行MapReduce程序
1、分析
1)配置集群
2)启动、测试集群 增、删、查
3)执行 WordCount 案例
2、执行步骤
1)配置集群
a、配置:hadoop-env.sh
Linux系统中获取JDK的安装路径
[hadoop@ hadoop101 ~]# echo $JAVA_HOME
/opt/module/jdk1..0_144
修改JAVA_HOME路径:
export JAVA_HOME=/opt/module/jdk1..0_144
b、配置:core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property> <!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
c、配置:hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
2)启动集群
a、格式化NameNode(第一次启动时格式化,以后就不要总格式化)
[hadoop@hadoop101 hadoop-2.7.]$ bin/hdfs namenode -format
b、启动NameNode
[hadoop@hadoop101 hadoop-2.7.]$ sbin/hadoop-daemon.sh start namenode
c、启动DataNode
[hadoop@hadoop101 hadoop-2.7.]$ sbin/hadoop-daemon.sh start datanode
3)查看集群
a、查看是否启动成功
[hadoop@hadoop101 hadoop-2.7.]$ jps
NameNode
DataNode
Jps
b、web端查看HDFS文件系统
http://hadoop101:50070/dfshealth.html#tab-overview
注意:如果不能查看,看如下帖子处理:http://www.cnblogs.com/zlslch/p/6604189.html
c、查看产生的Log日志
当前目录:/opt/module/hadoop-2.7.2/logs
[hadoop@hadoop101 logs]$ ls
hadoop-atguigu-datanode-hadoop.atguigu.com.log
hadoop-atguigu-datanode-hadoop.atguigu.com.out
hadoop-atguigu-namenode-hadoop.atguigu.com.log
hadoop-atguigu-namenode-hadoop.atguigu.com.out
SecurityAuth-root.audit
[hadoop@hadoop101 logs]# cat hadoop-atguigu-datanode-hadoop101.log
d、思考:为什么不能一直格式化NameNode,格式化NameNode,要注意什么?
[hadoop@hadoop101 hadoop-2.7.]$ cd data/tmp/dfs/name/current/ [hadoop@hadoop101 current]$ cat VERSION
clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837 [hadoop@hadoop101 hadoop-2.7.]$ cd data/tmp/dfs/data/current/
clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到以往数据。所以,格式化NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
4)操作集群
a、在HDFS文件系统上创建一个 input 文件夹
[hadoop@hadoop101 hadoop-2.7.]$ bin/hdfs dfs -mkdir -p /user/hadoop/input
b、将测试文件内容上传到文件系统上
[hadoop@hadoop101 hadoop-2.7.]$bin/hdfs dfs -put wcinput/wc.input /user/hadoop/input/
c、查看上传的文件是否正确
[hadoop@hadoop101 hadoop-2.7.]$ bin/hdfs dfs -ls /user/hadoop/input/
[hadoop@hadoop101 hadoop-2.7.]$ bin/hdfs dfs -cat /user/hadoop/input/wc.input
d、运行MapReduce程序
[hadoop@hadoop101 hadoop-2.7.]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar wordcount /user/hadoop/input/ /user/hadoop/output
e、查看输出结果
命令行查看:
[hadoop@hadoop101 hadoop-2.7.]$ bin/hdfs dfs -cat /user/hadoop/output/*
浏览器查看:

f、将测试文件内容下载到本地
[hadoop@hadoop101 hadoop-2.7.]$ hdfs dfs -get /user/hadoop/output/part-r- ./wcoutput/
g、删除输出结果
[hadoop@hadoop101 hadoop-2.7.]$ hdfs dfs -rm -r /user/hadoop/output
2、启动YARN并运行MapReduce程序
1、分析
1)配置集群在YARN上运行MR
2)启动、测试集群 增、删、查
3)在YARN上执行WordCount案例
2、执行步骤
1)配置集群
a、配置yarn-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/opt/module/jdk1..0_144
b、配置yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
c、配置:mapred-env.sh
配置一下 JAVA_HOME
export JAVA_HOME=/opt/module/jdk1..0_144
d、配置:(对mapred-site.xml.template重命名为)mapred-site.xml
[hadoop@hadoop101 hadoop]$ mv mapred-site.xml.template mapred-site.xml
[hadoop@hadoop101 hadoop]$ vi mapred-site.xml <!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2)启动集群
a、启动前必须保证NameNode和DataNode已经启动
b、启动ResourceManager
[hadoop@hadoop101 hadoop-2.7.]$ sbin/yarn-daemon.sh start resourcemanager
c、启动NodeManager
[hadoop@hadoop101 hadoop-2.7.]$ sbin/yarn-daemon.sh start nodemanager
3)集群操作
a、yarn的浏览器页面查看:

b、删除文件系统上的output文件夹
[hadoop@hadoop101 hadoop-2.7.]$ bin/hdfs dfs -rm -R /user/atguigu/output
c、执行MapReduce程序
[hadoop@hadoop101 hadoop-2.7.]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar wordcount /user/hadoop/input /user/hadoop/output
d、查看运行结果:
[hadoop@hadoop101 hadoop-2.7.]$ bin/hdfs dfs -cat /user/atguigu/output/*
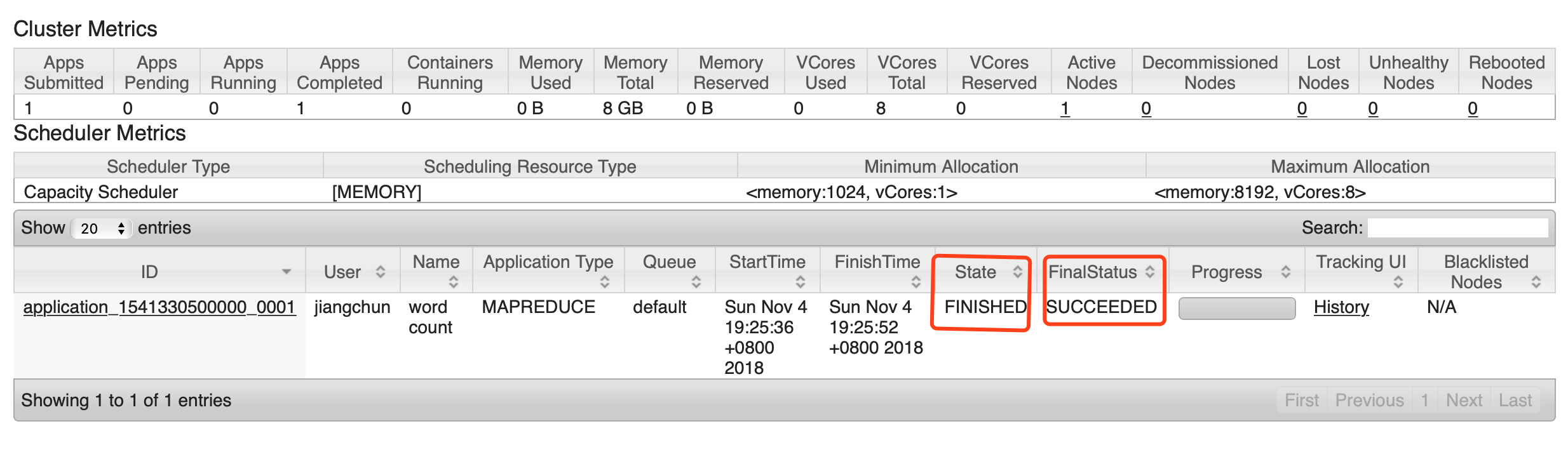
3、配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器,具体配置步骤如下:
1)配置mapred-site.xml
在该文件里面增加如下配置:
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property> <!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop101:19888</value>
</property>
2)启动历史服务器
[hadoop@hadoop101 hadoop-2.7.]$ sbin/mr-jobhistory-daemon.sh start historyserver
3)查看历史服务器是否启动
[hadoop@hadoop101 hadoop-2.7.]$ jps
4)查看JobHistory
http://hadoop101:19888/jobhistory
4、配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便地查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动 NodeManager、ResourceManager 和 HistoryManager。
步骤如下:
1)配置 yarn-site.xml
在该文件里面增加如下配置:
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property> <!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
2)关闭 NodeManager、ResourceManager 和 HistoryManager
[hadoop@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop resourcemanager
[hadoop@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager
[hadoop@hadoop101 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh stop historyserver
3)启动NodeManager、ResourceManager 和 HistoryManager
[hadoop@hadoop101 hadoop-2.7.]$ sbin/yarn-daemon.sh start resourcemanager
[hadoop@hadoop101 hadoop-2.7.]$ sbin/yarn-daemon.sh start nodemanager
[hadoop@hadoop101 hadoop-2.7.]$ sbin/mr-jobhistory-daemon.sh start historyserver
4)删除HDFS 上已经存在的输出文件
[hadoop@hadoop101 hadoop-2.7.]$ bin/hdfs dfs -rm -R /user/atguigu/output
5)执行 WordCount 程序
[hadoop@hadoop101 hadoop-2.7.]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar wordcount /user/atguigu/input /user/atguigu/output
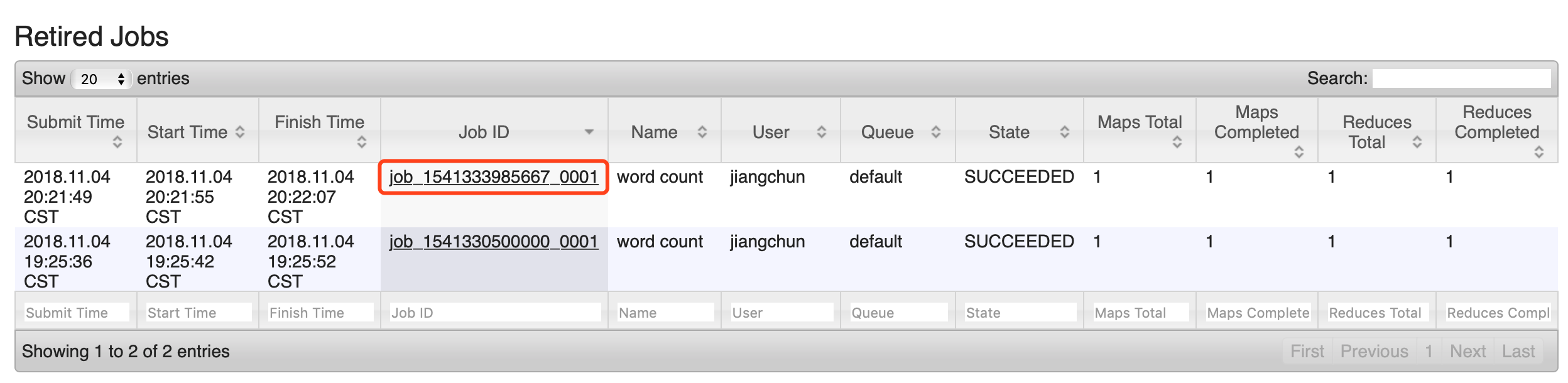
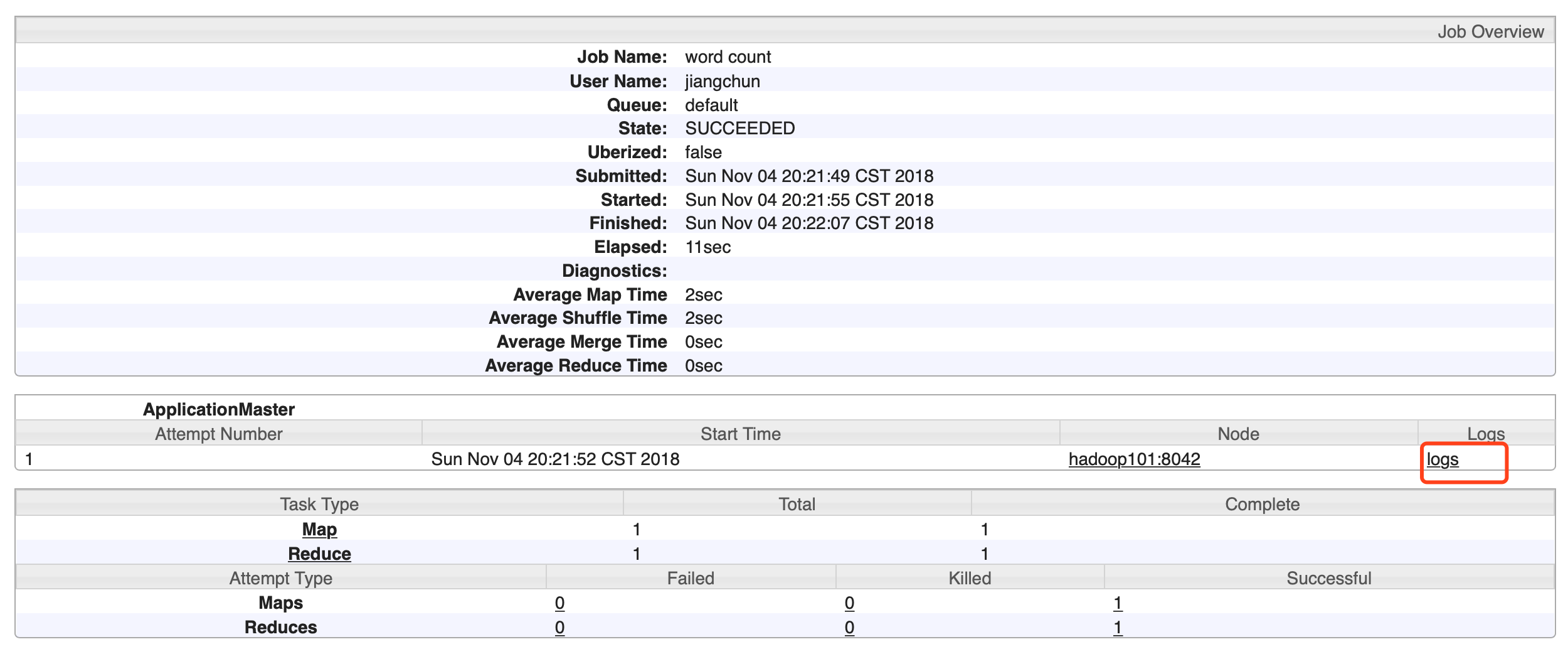
6)查看日志,如图
http://hadoop101:19888/jobhistory

5、配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
1)默认配置文件:
| 要获取的默认文件 | 文件存放在hadoop的jar包中的位置 |
| core-default.xml | hadoop-common-2.7.2.jar/core-default.xml |
| hdfs-default.xml | hadoop-hdfs-2.7.2.jar/hdfs-default.xml |
| yarn-default.xml | hadoop-yarn-common-2.7.2.jar/yarn-default.xml |
| mapred-default.xml | hadoop-mapreduce-client-core-2.7.2.jar/mapred-default.xml |
2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 四个配置文件存放在 $HADOOP_HOME/etc/hadoop 这个路径上,用户可以根据项目需求重新进行修改配置。
Hadoop之运行模式的更多相关文章
- hadoop本地运行模式调试
一:简介 最近学习hadoop本地运行模式,在运行期间遇到一些问题,记录下来备用:以运行hadoop下wordcount为例子. hadoop程序是在集群运行还是在本地运行取决于下面两个参数的设置,第 ...
- hadoop的运行模式
概述 1)资料查询(官方网址) (1)官方网站: http://hadoop.apache.org/ (2)各个版本归档库地址 https://archive.apache.org/dist/hado ...
- 大数据-Hadoop 本地运行模式
Grep案例 1. 创建在hadoop-2.7.2文件下面创建一个input文件夹 [atguigu@hadoop101 hadoop-2.7.2]$ mkdir input 2. 将Hadoop的x ...
- Hadoop系列004-Hadoop运行模式(上)
title: Hadoop系列004-Hadoop运行模式(上) date: 2018-11-20 14:27:00 updated: 2018-11-20 14:27:00 categories: ...
- Hadoop系列005-Hadoop运行模式(下)
本人微信公众号,欢迎扫码关注! Hadoop运行模式(下) 2.3.完全分布式部署Hadoop 1)分析: 1)准备3台客户机(关闭防火墙.静态ip.主机名称) 2)安装jdk 3)配置环境变量 4) ...
- 大数据学习之Hadoop运行模式
一.Hadoop运行模式 (1)本地模式(默认模式): 不需要启用单独进程,直接可以运行,测试和开发时使用. (2)伪分布式模式: 等同于完全分布式,只有一个节点. (3)完全分布式模式: 多个节点一 ...
- ubuntu上Hadoop三种运行模式的部署
Hadoop集群支持三种运行模式:单机模式.伪分布式模式,全分布式模式,下面介绍下在Ubuntu下的部署 (1)单机模式 默认情况下,Hadoop被配置成一个以非分布式模式运行的独立JAVA进程,适合 ...
- Hadoop运行模式
Hadoop运行模式 (1)本地模式(默认模式): 不需要启用单独进程,直接可以运行,测试和开发时使用. 即在一台机器上进行操作,仅为单机版. 本地运行Hadoop官方MapReduce案例 操作命令 ...
- 啃掉Hadoop系列笔记(03)-Hadoop运行模式之本地模式
Hadoop的本地模式为Hadoop的默认模式,不需要启用单独进程,直接可以运行,测试和开发时使用. 在<啃掉Hadoop系列笔记(02)-Hadoop运行环境搭建>中若环境搭建成功,则直 ...
随机推荐
- hdu1693 插头dp
题意:给了一个矩阵图,要求使用回路把图中的树全部吃掉的方案树,没有树的点不能走,吃完了这个点也就没有了,走到哪吃到哪 用插头dp搞 #include <iostream> #include ...
- Delphi中Move、CopyMemory操作
字串转字节数组 一.CopyMemory var s:PAnsiChar; ary:TArray<Byte>; bt:Byte; begin s:='Form Delphi'; SetLe ...
- 服务器告警其一:硬盘raid问题
问题描述 服务器一直间断发出告警音,但是根据raid类型的不同有一定可能进入系统. 问题详情 在LSI Mega Webbios自检之后系统开始出现告警音. 在Lsi Mega Webbios的ini ...
- ThinkAdmin for PHP后台管理系统
ThinkAdmin for PHP后台管理系统 ThinkAdmin 是一个基于 Thinkphp 5.1.x 开发的后台管理系统,集成后台系统常用功能.基于 ThinkPHP 5.1 基础开发平台 ...
- RPC REST 比较
REST 和 RPC是两种架构设计风格. 一般情况下REST多用于与外部接口访问时的设计,RPC多用于系统内部的. 为什么这样呢? 1.RPC必然有依赖,REST必然没有,不要抬杠,SDK暂时不算. ...
- maven 项目连接mysql8.0版本时的注意事项
MySQL 8.0 正式版 8.0.11 已发布,官方表示 MySQL 8 要比 MySQL 5.7 快 2 倍,还带来了大量的改进和更快的性能! 以前的maven项目,要注意依赖的注入 查看pom. ...
- [转载]Oracle用户创建及权限设置
出处:https://www.cnblogs.com/buxingzhelyd/p/7865194.html 权限: create session 允许用户登录数据库权限 create table ...
- vue图片onerror加载路径写法
vue里,img加载错误的时候,onerror属性可以加载错误图片的默认图片写法如下: <img class=avator' :src="data.picture" :one ...
- Easy methods to select MB Star, Extremely MB Star, MB SD C4, Mercedes BENZ C5 SD
MB Star, Extremely MB SD Connect C4, MB SD C4, Mercedes BENZ C5 SD are usually analysis tools to get ...
- vue 路由守卫
router.beforeEach((to, from, next) => { const nextRoute = [ 'login']; var token = window.localSto ...