hadoop部署安装(六)hive
5.配置hive
5.1 hive下载地址
http://mirror.bit.edu.cn/apache/hive/
解压缩
[root@master ~]# tar xf apache-hive-3.1.2-bin.tar.gz
[root@master ~]# mv apache-hive-3.1.2-bin /usr/local/hive
5.2准备数据库hive
192.168.101.54提供hive服务的数据库hive,用户密码均为hive
建表语句
create database hive default character set utf8;
grant all privileges on hive.* to 'hive'@'%' identified by 'hive';
flush privileges;
5.3配置 Hive
a重命名以下配置文件:
cd /usr/local/hive/conf/
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
cp hive-log4j2.properties.template hive-log4j2.properties
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
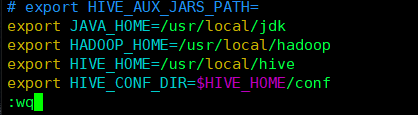
b修改 hive-env.sh:
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export HIVE_HOME=/usr/local/hive
export HIVE_CONF_DIR=$HIVE_HOME/conf
c修改 hive-site.xml:
修改对应属性的 value 值
vi hive-site.xml
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive-${user.name}</value>
<description>HDFS root scratch dir for Hive jobs which gets
created with write all (733) permission. For each connecting user,
an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created,
with ${hive.scratch.dir.permission}.
</description>
</property>

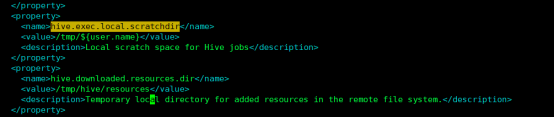
<property>
<name>hive.exec.local.scratchdir</name>
<value>/tmp/${user.name}</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/tmp/hive/resources</value>
<description>Temporary local directory for added resources in the remote
file system.</description>
</property>
<property>
<name> hive.querylog.location</name>
<value>/tmp/${user.name}</value>
<description>Location of Hive run time structured log file</description>
</property>

<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/tmp/${user.name}/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>

d配置 Hive Metastore
Hive Metastore 是用来获取 Hive 表和分区的元数据,本例中使用 mariadb 来存储此类元数据。
将 mysql-connector-java-5.1.32-bin.jar 放入 $HIVE_HOME/lib 下

并在 hive-site.xml 中配置 MySQL 数据库连接信息。
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.101.54:3306/hive</value>
</property>
(下图内容以上述文本为准)

<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
(下图内容以上述文本为准)

<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
(下图内容以上述文本为准)

<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
(下图内容以上述文本为准)
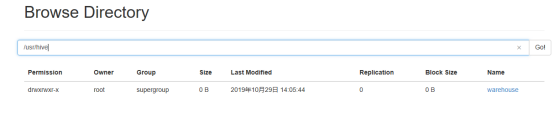
e为 Hive 创建 HDFS 目录
start-dfs.sh #如果在安装配置hadoop是已经启动,则此命令可省略
hdfs dfs -mkdir /tmp
hdfs dfs -mkdir -p /usr/hive/warehouse
hdfs dfs -chmod g+w /tmp
hdfs dfs -chmod g+w /usr/hive/warehouse
f hive-site.xml
3213 Ensures commands with OVERWRITE (such as INSERT OVERWRITE) acquire Exclusive locks fortransactional tables. This ensures that inserts (w/o over
write) running concurrently
删除&#*:
5.4初始化schematool
添加环境变量
vim /etc/profile
#hive
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
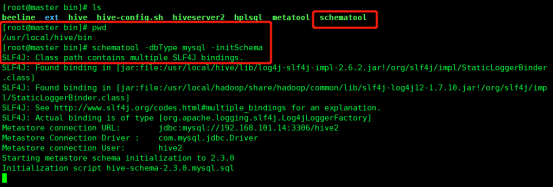
从 Hive 2.1 版本开始, 在启动 Hive 之前需运行 schematool 命令来执行初始化操作:
schematool -dbType mysql -initSchema
5.5启动 Hive,输入命令 Hive

5.6测试 Hive
在 Hive中创建一个表:
hive> create table test_hive(id int, name string)
> row format delimited fields terminated by '\t'
#字段之间用tab键进行分割
> stored as textfile;
# 设置加载数据的数据类型,默认是TEXTFILE,如果文件数据是纯文本,就是使用 [STORED AS TEXTFILE],然后从本地直接拷贝到HDFS上,hive直接可以识别数据
hive> show tables;
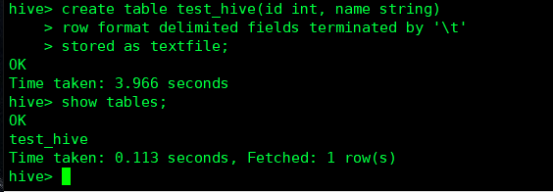
可以看到表已经创建成功,输入 quit ; 退出 Hive,接下来以文本形式创建数据:
进入 Hive,导入数据:
hive> load data local inpath '/opt/test_db.txt' into table test_hive;
hive> select * from test_hive;

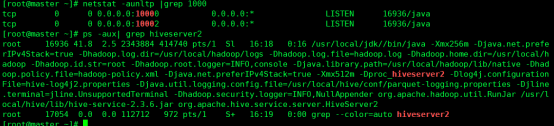
5.7后台运行hiveserver2
远程访问,开放10000端口。10002为beeline的GUI界面。
运行服务
[root@master ~]# nohup hive –service hiveserver2 &
[root@master ~]# netstat -aunltp |grep 10000
[root@master ~]# ps -aux| grep hiveserver2
复制jar包
[root@master lib]# cp /usr/local/jdk/lib/tools.jar /usr/local/hive/lib/
hadoop部署安装(六)hive的更多相关文章
- Hadoop 2.2.0部署安装(笔记,单机安装)
SSH无密安装与配置 具体配置步骤: ◎ 在root根目录下创建.ssh目录 (必须root用户登录) cd /root & mkdir .ssh chmod 700 .ssh & c ...
- ubuntu18.04 安装hadoop 2.7.3+hive 2.3.4
1. 安装hadoop 详细请参见本人的另外一片博文<Hadoop 2.7.3 分布式集群安装> 2. 下载hive 2.3.4 解压文件到/opt/software -bin.tar.g ...
- HIVE部署安装(笔记)
1.下载hive:wget http://mirrors.cnnic.cn/apache/hive/hive-0.12.0/hive-0.12.0.tar.gz2.解压hive安装文件 tar -zv ...
- Hadoop之中的一个:Hadoop的安装部署
说到Hadoop不得不说云计算了,我这里大概说说云计算的概念,事实上百度百科里都有,我仅仅是copy过来,好让我的这篇hadoop博客内容不显得那么单调.骨感.云计算近期今年炒的特别火,我也是个刚開始 ...
- hadoop生态圈安装详解(hadoop+zookeeper+hbase+pig+hive)
-------------------------------------------------------------------* 目录 * I hadoop分布式安装 * II zoo ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- hive学习(一)hive架构及hive3.1.1三种方式部署安装
1.hive简介 logo 是一个身体像蜜蜂,头是大象的家伙,相当可爱. Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据.它架构在Hadoop之上,总归为大数据,并使得查询和分析方便 ...
- Hadoop 部署之 Hive (五)
目录 一.Hive 简介 1.什么是 Hive 2.为什么使用 Hive 3.Hive 的特点 4.Hive 的架构 二.Hive 安装 1.MySQL 安装(datanode01) 2.MySQL ...
- mac安装Hadoop,mysql,hive,sqoop教程
在安装Hadoop,mysql,hive之前,首先要保证电脑上安装了jdk 一.配置jdk 1. 下载jdk http://www.oracle.com/technetwork/java/javase ...
- Hadoop学习---安装部署
hadoop框架 Hadoop使用主/从(Master/Slave)架构,主要角色有NameNode,DataNode,secondary NameNode,JobTracker,TaskTracke ...
随机推荐
- InfluxDB UI 设置保留策略
InfluxDB UI 设置保留策略 创建Bucket时设置保留策略 在InfluxDB 2.x的UI中创建Bucket时,你可以直接设置其保留策略.以下是一个基本的步骤指南: 登录到InfluxDB ...
- 5. Docker 本地镜像发布到阿里云
5. Docker 本地镜像发布到阿里云 @ 目录 5. Docker 本地镜像发布到阿里云 1. 本地镜像发布到阿里云流程 最后: 1. 本地镜像发布到阿里云流程 镜像的生成方法: 基于当前容器创建 ...
- C# 性能优化 --- Lazy<T> 用法学习
参考原文:https://kb.cnblogs.com/page/99182/ 延迟实例化,对于需要创建大量对象,而又不需要立即使用的场景非常有用.一下实例说明了Lazy<T>的用法. u ...
- .NET 使用 DeepSeek R1 开发智能 AI 客户端
前言 最近 DeepSeek 可太火了,在人工智能领域引起了广泛的关注,其强大的自然语言处理能力和智能搜索功能让大家跃跃欲试. 对于 .NET 技术栈的开发来说,一个常见的问题是:能否在 .NET 程 ...
- Linux MiniMal版本常规所需环境安装
Docker 环境安装 前置工作 之 基础环境安装 当前环境 centos7.9 64位 minimal版本 当前环境为 root用户 若当前存在Docker环境 需卸载 yum remove doc ...
- Maven - 项目的JDK编译level是1.5,修改不掉??
背景 idea中的maven项目,父项目和子项目的Project Structure的language level都是1.5,怎么修改为8?尝试修改并应用后会失效,还是会自动恢复为1.5. 1.S ...
- “未能加载工具箱项xxx,将从工具箱中将其删除”提示出现原因及解决方案
https://www.thinbug.com/q/27289366 https://social.msdn.microsoft.com/Forums/vstudio/en-US/77e10b58-4 ...
- C#/.NET/.NET Core技术前沿周刊 | 第 27 期(2025年2.17-2.23)
前言 C#/.NET/.NET Core技术前沿周刊,你的每周技术指南针!记录.追踪C#/.NET/.NET Core领域.生态的每周最新.最实用.最有价值的技术文章.社区动态.优质项目和学习资源等. ...
- Golang 入门 : 类型系统介绍
Go语言类型系统 从计算机底层看,所有的数据都是由比特组成,但计算机一般操作的是固定大小的数,如整数.浮点数.比特数组.内存地址等.但是直接操控底层计算机指令进行编程是非常繁琐和容易出错的,所以Go语 ...
- Oracle操作审计
因为信安的要求,要对Oracle加审计.看了一下,原来是有开的,类型为DB: SQL> show parameter audit; NAME TYPE VALUE --------------- ...