强化学习算法中的log_det_jacobian
相关:
https://colab.research.google.com/github/google/brax/blob/main/notebooks/training_torch.ipynb
之前写过一篇同主题的文章,后来发现这个文章中有一些问题,不过也有些不好改动,于是就新开一篇来进行更正和补充!!!
之前版本:
https://www.cnblogs.com/xyz/p/18564777
之所以之前版本有一些问题,其主要原因是其中的很多推理都是使用ChatGPT完成的,后来又遇到其他关于log_det_jacobian的算法,于是就重新遇到了相关问题,这时候通过查看相关资料发现ChatGPT的生成的理论推理有一些问题,但是出现的问题又十分不好察觉,于是就有了本篇。
要想知道log_det_jacobian是个什么东西,首先需要知道Bijector是什么。
A bijector is a function of a tensor and its utility is to transform one distribution to another distribution. Bijectors bring determinism to the randomness of a distribution where the distribution by itself is a source of stochasticity. For example, If you want a log density of distribution, we can start with a Gaussian distribution and do log transform using bijector functions. Why do we need such transformations, the real world is full of randomness and probabilistic machine learning establishes a formalism for reasoning under uncertainty. i.e A prediction that outputs a single variable is not sufficient but has to quantify the uncertainty to bring in model confidence. Then to sample complex random variables that get closer to the randomness of nature, we seek the help of bijective functions.
简单来说就是对一个分布进行变换,比如X服从高斯分布,y=tanh(x),那么Y服从什么分布呢,Y的概率密度如何计算,Y分布如何抽样,可以说Bijector就是指分布的变换,而log_det_jacobian就是在分布变换时计算概率密度所需要用到的。
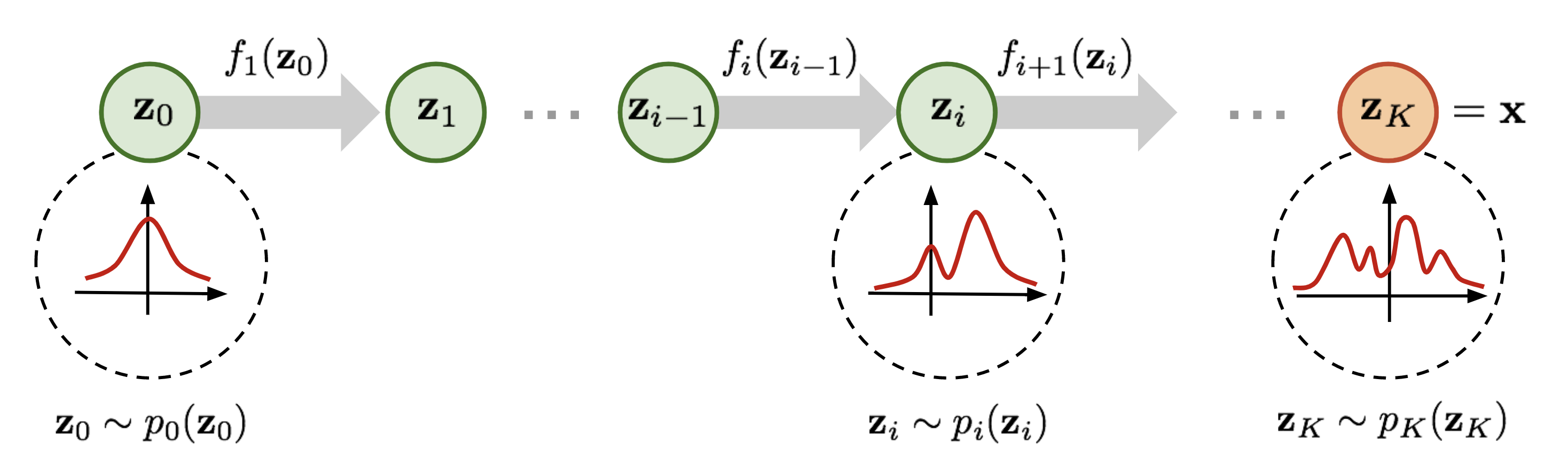
各个深度学习框架都针对机器学习中的这种概率分布变换的Bijector提供单独的计算方法,如:
paddle中的:
paddle.distribution.Transform
相关:
https://www.paddlepaddle.org.cn/documentation/docs/en/api/paddle/distribution/Transform_en.html


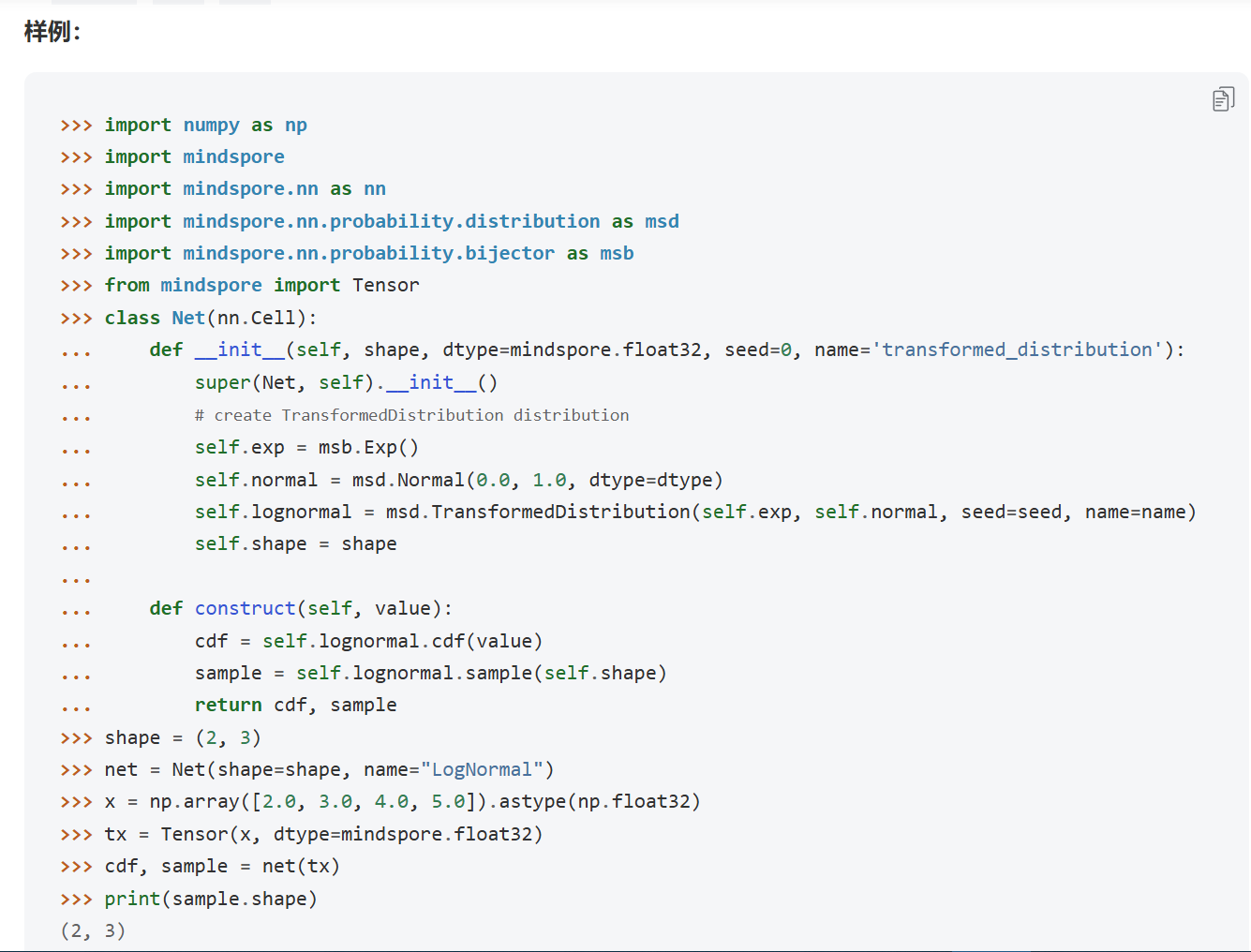
mindspore中的:
mindspore.nn.probability.distribution.TransformedDistribution
相关:

log_det_jacobian = 2 * (math.log(2) - dist - F.softplus(-2 * dist))
= log( tanh'(x) )
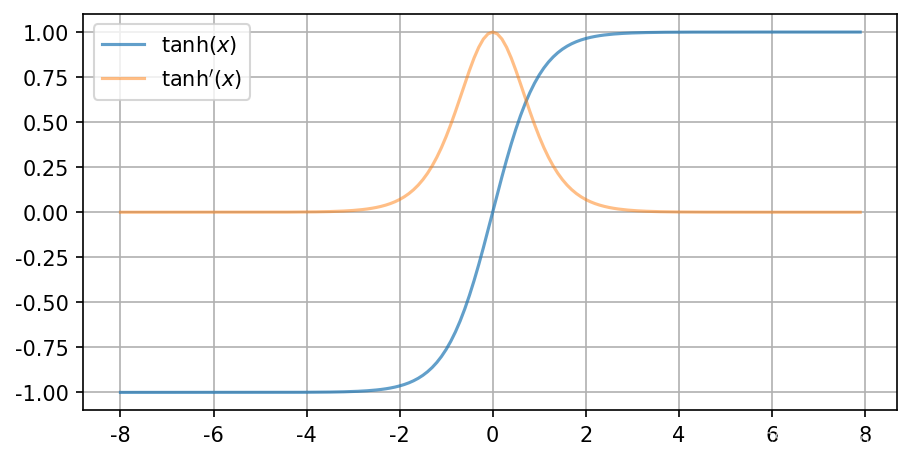
关于tanh函数的特性:

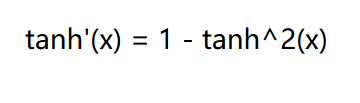
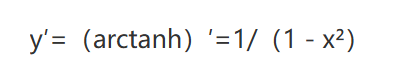
下图来自:
高斯函数的信息熵求解公式:

各个深度学习框架中的Probability模块的不足之处:
可以说在这个领域TensorFlow Probability (TFP)是最为功能强大和全面的,也是最为公认和广泛使用的,虽然我不喜欢用TensorFlow搞deep learning,但是必须要承认搞probability的深度学习的话还是用这个TensorFlow的TFP貌似更稳妥。
虽然Probability模块的可以自动实现分布变换后的概率密度,采样(sample),logP的计算,但是对于一些其他的计算其实支持并不是很好,如信息熵的计算,因为比如像信息熵这样的计算并不能由Probability模块自动获得,而是需要人为的设置,比如高斯分布的信息熵,这个就是需要人为手动的为不同的分布进行计算,因此可以说Probability模块并不能解决所有的分布变换后的新的统计量的计算,还是有一些需要手动推导计算公式并进行硬编码的,也或者是采用其他的近似的计算方法来解决。
相关:
TensorFlow推荐器和TensorFlow概率:使用TensorFlow概率进行概率建模简介
强化学习算法中的log_det_jacobian的更多相关文章
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- 斯坦福大学公开课机器学习:machine learning system design | trading off precision and recall(F score公式的提出:学习算法中如何平衡(取舍)查准率和召回率的数值)
一般来说,召回率和查准率的关系如下:1.如果需要很高的置信度的话,查准率会很高,相应的召回率很低:2.如果需要避免假阴性的话,召回率会很高,查准率会很低.下图右边显示的是召回率和查准率在一个学习算法中 ...
- 强化学习算法DQN
1 DQN的引入 由于q_learning算法是一直更新一张q_table,在场景复杂的情况下,q_table就会大到内存处理的极限,而且在当时深度学习的火热,有人就会想到能不能将从深度学习中借鉴方法 ...
- 强化学习算法Policy Gradient
1 算法的优缺点 1.1 优点 在DQN算法中,神经网络输出的是动作的q值,这对于一个agent拥有少数的离散的动作还是可以的.但是如果某个agent的动作是连续的,这无疑对DQN算法是一个巨大的挑战 ...
- 强化学习Q-Learning算法详解
python风控评分卡建模和风控常识(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005214003&am ...
- 强化学习(十三) 策略梯度(Policy Gradient)
在前面讲到的DQN系列强化学习算法中,我们主要对价值函数进行了近似表示,基于价值来学习.这种Value Based强化学习方法在很多领域都得到比较好的应用,但是Value Based强化学习方法也有很 ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- 【转载】 DeepMind发表Nature子刊新论文:连接多巴胺与元强化学习的新方法
原文地址: baijiahao.baidu.com/s?id=1600509777750939986&wfr=spider&for=pc 机器之心 18-05-15 14:26 - ...
- 【转载】 准人工智能分享Deep Mind报告 ——AI“元强化学习”
原文地址: https://www.sohu.com/a/231895305_200424 ------------------------------------------------------ ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
随机推荐
- 数据库日常实操优质文章分享(含Oracle、MySQL等) | 11月刊
墨天轮社区正持续举办[聊聊故障处理那些事儿]DBA专题征文活动中,每月进行评优发奖,鼓励大家记录工作中遇到的数据库故障处理过程,不仅用于自我复盘与分析,同时也能帮助其他的同仁们避坑. 这里为大家整理出 ...
- Vue 的最大优势是???
Vue 是一套用于构建用户界面的渐进式框架.与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用.Vue 的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合.另一方面,当与现代 ...
- 关于自动部署 - 基于gitlab关联 腾讯云 web 应用
gitlab 相当于 gitee 的企业版形式 : 步骤 1. 使用 Vscode 编写代码,使用 gitlab托管代码, 2. 新建腾讯云 web 应用 ,gitlab 关联 web应用, 3. 每 ...
- RecyclerView刷新方式
RecyclerView刷新方式 刷新全部item notifyDataSetChanged() student.setValue(new Student("二狗")); stud ...
- windows当中C++版本的Opencv安装(动态库+静态库)
主要参考2篇博客,其实就是dll文件和lib文件的使用方法而已.链接如下: 1.静态库opencv配置 2.动态库opencv安装
- Zipkin+Sleuth调用链监控集成和使用
背景与需求 跨微服务的API调用发生异常,要求快速定位出问题出在哪里. 跨微服务的API调用发生性能瓶颈,要求迅速定位出性能瓶颈. 集成 整体结构 整体机构为C/S模式,客户端(Sleuth)来监控采 ...
- 推荐一个Star超过2K的.Net轻量级的CMS开源项目
推荐一个具有模块化和可扩展的架构的CMS开源项目. 01 项目简介 Piranha CMS是一个轻量级且跨平台的CMS库,专为.NET 8设计. 该项目提供多种模板,具备CMS基本功能,也有空模板方便 ...
- 鸿蒙NEXT开发案例:光强仪
[引言] 本文将介绍如何使用鸿蒙NEXT框架开发一个简单的光强仪应用,该应用能够实时监测环境光强度,并给出相应的场景描述和活动建议. [环境准备] 电脑系统:windows 10 开发工具:DevEc ...
- python岭迹图绘制函数
一.岭迹图是什么? 岭迹图(Ridge Trace Plot)是一种可视化工具,用于展示岭回归中正则化参数($\alpha$)对回归系数的影响.它能帮助我们理解特征的稳定性和正则化在控制模型复杂度中的 ...
- P3920 WC2014 紫荆花之恋
P3920 WC2014 紫荆花之恋 毒瘤题目,动态点分树. 前置科技点 替罪羊树 高速平衡树(除去 fhq_treap 和 splay 之外的所有平衡树) 约定 \(dis(u,v)\) 为原树上 ...