49、Spark Streaming基本工作原理
一、大数据实时计算介绍
1、概述
Spark Streaming,其实就是一种Spark提供的,对于大数据,进行实时计算的一种框架。它的底层,其实,也是基于我们之前讲解的Spark Core的。
基本的计算模型,还是基于内存的大数据实时计算模型。而且,它的底层的组件或者叫做概念,其实还是最核心的RDD。 只不过,针对实时计算的特点,在RDD之上,进行了一层封装,叫做DStream。其实,学过了Spark SQL之后,你理解这种封装就容易了。之前学习Spark SQL是不是也是发现,
它针对数据查询这种应用,提供了一种基于RDD之上的全新概念,DataFrame,但是,其底层还是基于RDD的。所以,RDD是整个Spark技术生态中的核心。
要学好Spark在交互式查询、实时计算上的应用技术和框架,首先必须学好Spark核心编程,也就是Spark Core。
2、图解

二、Spark Streaming基本工作原理
1、Spark Streaming简介
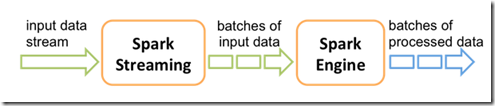
Spark Streaming是Spark Core API的一种扩展,它可以用于进行大规模、高吞吐量、容错的实时数据流的处理。它支持从很多种数据源中读取数据,
比如Kafka、Flume、Twitter、ZeroMQ、Kinesis或者是TCP Socket。并且能够使用类似高阶函数的复杂算法来进行数据处理,比如map、reduce、join和window。
处理后的数据可以被保存到文件系统、数据库、Dashboard等存储中。

2、Spark Streaming基本工作原理
Spark Streaming内部的基本工作原理如下:接收实时输入数据流,然后将数据拆分成多个batch,比如每收集1秒的数据封装为一个batch,
然后将每个batch交给Spark的计算引擎进行处理,最后会生产出一个结果数据流,其中的数据,也是由一个一个的batch所组成的。
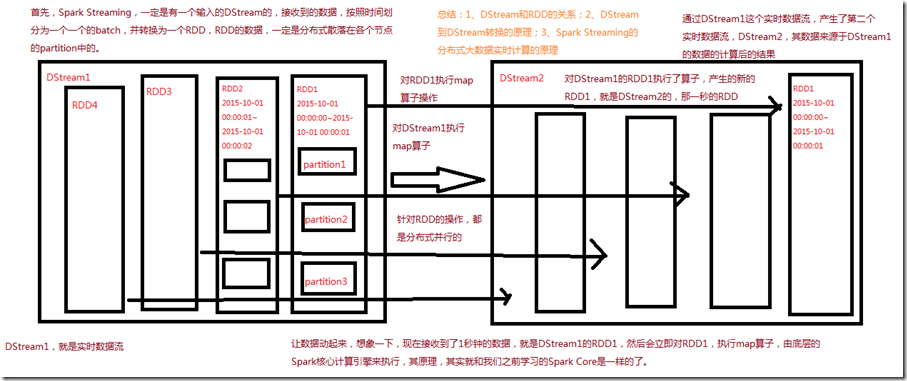
Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),
每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,
将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行缓存或者存储到外部设备。下图显示了Spark Streaming的整个流程。
三、DStream
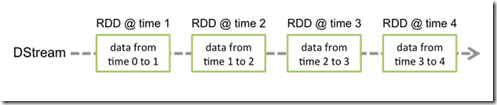
Spark Streaming提供了一种高级的抽象,叫做DStream,英文全称为Discretized Stream,中文翻译为“离散流”,它代表了一个持续不断的数据流。
DStream可以通过输入数据源来创建,比如Kafka、Flume和Kinesis;也可以通过对其他DStream应用高阶函数来创建,比如map、reduce、join、window。 DStream的内部,其实一系列持续不断产生的RDD。RDD是Spark Core的核心抽象,即,不可变的,分布式的数据集。DStream中的每个RDD都包含了一个时间段内的数据。
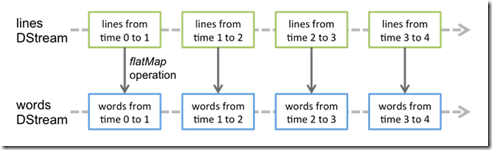
对DStream应用的算子,比如map,其实在底层会被翻译为对DStream中每个RDD的操作。比如对一个DStream执行一个map操作,会产生一个新的DStream。
但是,在底层,其实其原理为,对输入DStream中每个时间段的RDD,都应用一遍map操作,然后生成的新的RDD,即作为新的DStream中的那个时间段的一个RDD。
底层的RDD的transformation操作,其实,还是由Spark Core的计算引擎来实现的。Spark Streaming对Spark Core进行了一层封装,隐藏了细节,
然后对开发人员提供了方便易用的高层次的API。
四、Spark Streaming与Storm的对比
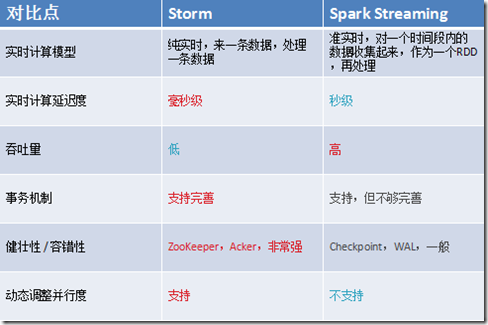
1、Spark Streaming与Storm的优劣分析
事实上,Spark Streaming绝对谈不上比Storm优秀。这两个框架在实时计算领域中,都很优秀,只是擅长的细分场景并不相同。 Spark Streaming仅仅在吞吐量上比Storm要优秀,而吞吐量这一点,也是历来挺Spark Streaming,贬Storm的人着重强调的。
但是问题是,是不是在所有的实时计算场景下,都那么注重吞吐量?不尽然。因此,通过吞吐量说Spark Streaming强于Storm,不靠谱。 事实上,Storm在实时延迟度上,比Spark Streaming就好多了,前者是纯实时,后者是准实时。而且,Storm的事务机制、健壮性 / 容错性、
动态调整并行度等特性,都要比Spark Streaming更加优秀。 Spark Streaming,有一点是Storm绝对比不上的,就是:它位于Spark生态技术栈中,因此Spark Streaming可以和Spark Core、Spark SQL无缝整合,
也就意味着,我们可以对实时处理出来的中间数据,立即在程序中无缝进行延迟批处理、交互式查询等操作。这个特点大大增强了Spark Streaming的优势和功能。
2、Spark Streaming与Storm的应用场景
对于Storm来说:
1、建议在那种需要纯实时,不能忍受1秒以上延迟的场景下使用,比如实时金融系统,要求纯实时进行金融交易和分析
2、此外,如果对于实时计算的功能中,要求可靠的事务机制和可靠性机制,即数据的处理完全精准,一条也不能多,一条也不能少,也可以考虑使用Storm
3、如果还需要针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),也可以考虑用Storm
4、如果一个大数据应用系统,它就是纯粹的实时计算,不需要在中间执行SQL交互式查询、复杂的transformation算子等,那么用Storm是比较好的选择 对于Spark Streaming来说:
1、如果对上述适用于Storm的三点,一条都不满足的实时场景,即,不要求纯实时,不要求强大可靠的事务机制,不要求动态调整并行度,那么可以考虑使用Spark Streaming
2、考虑使用Spark Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,即,如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询等业务功能,
而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,那么就应该首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,
用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性。
49、Spark Streaming基本工作原理的更多相关文章
- 一图看懂hadoop Spark On Yarn工作原理
hadoop Spark On Yarn工作原理
- Spark Streaming简介及原理
简介: SparkStreaming是一套框架. SparkStreaming是Spark核心API的一个扩展,可以实现高吞吐量的,具备容错机制的实时流数据处理. 支持多种数据源获取数据: Spark ...
- Spark Streaming fileStream实现原理
fileStream是Spark Streaming Basic Source的一种,用于“近实时”地分析HDFS(或者与HDFS API兼容的文件系统)指定目录(假设:dataDirectory)中 ...
- 66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)
一.数据处理原理剖析 每隔我们设置的batch interval 的time,就去找ReceiverTracker,将其中的,从上次划分batch的时间,到目前为止的这个batch interval ...
- 63、Spark Streaming:架构原理深度剖析
一.架构原理深度剖析 StreamingContext初始化时,会创建一些内部的关键组件,DStreamGraph,ReceiverTracker,JobGenerator,JobScheduler, ...
- Spark Streaming初步使用以及工作原理详解
在大数据的各种框架中,hadoop无疑是大数据的主流,但是随着电商企业的发展,hadoop只适用于一些离线数据的处理,无法应对一些实时数据的处理分析,我们需要一些实时计算框架来分析数据.因此出现了很多 ...
- Spark Streaming笔记
Spark Streaming学习笔记 liunx系统的习惯创建hadoop用户在hadoop根目录(/home/hadoop)上创建如下目录app 存放所有软件的安装目录 app/tmp 存放临时文 ...
- spark streaming (一)
实时计算介绍 Spark Streaming, 其实就是一种Spark提供的, 对于大数据, 进行实时计算的一种框架. 它的底层, 其实, 也是基于我们之前讲解的Spark Core的. 基本的计算模 ...
- Spark Streaming 入门
概述 什么是 Spark Streaming? Spark Streaming is an extension of the core Spark API that enables scalable, ...
随机推荐
- js判断数组中是否有重复元素
方法一:正则 var ary = new Array("111","ff","222","aa","222&q ...
- JAVA基础之HttpServletResponse响应
用户在客户端输入网址(虚拟路径)时,开始发送一个HTTP请求(请求行.请求头.请求体)至服务器.服务器内的Tomcat引擎会解析请求的地址,去找XML文件,然后根据虚拟路径找Servlet的真实路径, ...
- LCD 驱动 S3C2440A
LCD Control 1 Register 以16BPP为例 LCD Control 2 Register LCD Control 3 Register LCD Control 4 Register ...
- php与mysql交互 面向过程
1.建立.关闭与MySQL服务器的连接 1)连接指定的mysql服务器 $mysqli_connect=@mysqli_connect($host, $user, $password,$databas ...
- Java开发环境之ActiveMQ
查看更多Java开发环境配置,请点击<Java开发环境配置大全> 柒章:ActiveMQ安装教程 1)去官网下载ActiveMQ安装包 http://activemq.apache.org ...
- vue父组件触发子组件方法
比如应用场景是弹窗中的组件,想要点弹窗时更新该组件展示对应记录的的值 methods: { edit (record) { this.mdl = Object.assign({}, record) t ...
- Synchronized偏向锁和轻量级锁的升级
原文:https://blog.csdn.net/tongdanping/article/details/79647337 锁的优化1.锁升级锁的4中状态:无锁状态.偏向锁状态.轻量级锁状态.重量级锁 ...
- MySQL:主键、外键、索引(一)
干货: 主键是关系表中记录的唯一标识.主键的选取非常重要:主键不要带有业务含义,而应该使用BIGINT自增或者GUID类型.主键也不应该允许NULL.可以使用多个列作为联合主键,但联合主键并不常用. ...
- python笔记36-装饰器之wraps
前言 前面一篇对python装饰器有了初步的了解了,但是还不够完美,领导看了后又提出了新的需求,希望运行的日志能显示出具体运行的哪个函数. __name__和doc __name__用于获取函数的名称 ...
- 补充拓展:CSS权重值叠加
都知道CSS选择器有权重优先级,权重大的优先展示. 但部分人可能不清楚,权重值也是可以叠加计算的 <!DOCTYPE html> <html> <head> < ...