在local模式下的spark程序打包到集群上运行
一、前期准备
前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客:
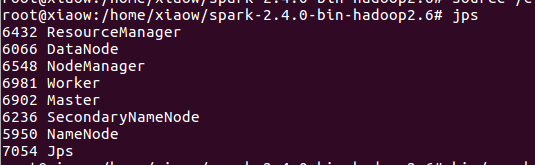
然后在spark伪分布式的环境下必须出现如下八个节点才算spark环境搭建好。
然后再在本地windows系统下有一个简单的词频统计程序。
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD object ScalaSparkDemo {
def main(args: Array[String]) {
/**
* 第一步:创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息,
* 例如说通过setMaster来设置程序要连接的Spark集群的Master的URL,
* 如果设置为local,则代表Spark程序在本地运行,特别适合于机器配置条件非常差
* (例如只有1G的内存)的初学者
*/
val conf = new SparkConf() //创建SparkConf对象,由于全局只有一个SparkConf所以不需要工厂方法
conf.setAppName("wow,my first spark app") //设置应用程序的名称,在程序的监控界面可以看得到名称
//conf.setMaster("local") //此时程序在本地运行,不需要安装Spark集群
/**
* 第二步:创建SparkContext对象
* SparkContext是Spark程序所有功能的唯一入口,无论是采用Scala、Java、Python、R等都必须要有一个
* SparkContext
* SparkContext核心作用:初始化Spark应用程序运行所需要的核心组件,包括DAGScheduler,TaskScheduler,SchedulerBacked,
* 同时还会负责Spark程序往Master注册程序等
* SparkContext是整个Spark应用程序中最为至关重要的一个对象
*/
val sc = new SparkContext(conf) //创建SpackContext对象,通过传入SparkConf实例来定制Spark运行的具体参数的配置信息
/**
* 第三步:根据具体的数据来源(HDFS,HBase,Local,FileSystem,DB,S3)通过SparkContext来创建RDD
* RDD的创建基本有三种方式,(1)根据外部的数据来源(例如HDFS)(2)根据Scala集合(3)由其它的RDD操作
* 数据会被RDD划分为成为一系列的Partitions,分配到每个Partition的数据属于一个Task的处理范畴
*/
//读取本地文件并设置为一个Partition
// val lines = sc.textFile("words.txt", 1) //第一个参数为为本地文件路径,第二个参数minPartitions为最小并行度,这里设为1
sc.setLogLevel("WARN")
val lines = sc.parallelize(List("pandas","i like pandas"))
//类型推断 ,也可以写下面方式
// val lines : RDD[String] =sc.textFile("words.txt", 1)
/**
* 第四步:对初始的RDD进行Transformation级别的处理,例如map,filter等高阶函数
* 编程。来进行具体的数据计算
* 第4.1步:将每一行的字符串拆分成单个的单词
*/
//对每一行的字符串进行单词拆分并把所有行的结果通过flat合并成一个大的集合
val words = lines.flatMap { line => line.split(" ") }
/**
* 第4.2步在单词拆分的基础上,对每个单词实例计数为1,也就是word=>(word,1)tuple
*/
val pairs = words.map { word => (word, 1) }
/**
* 第4.3步在每个单词实例计数为1的基础之上统计每个单词在文中出现的总次数
*/
//对相同的key进行value的累加(包括local和Reduce级别的同时Reduce)
val wordCounts = pairs.reduceByKey(_ + _)
//打印结果
wordCounts.foreach(wordNumberPair => println(wordNumberPair._1 + ":" + wordNumberPair._2))
//释放资源
sc.stop()
}
}
二、导出jar包
这里注意词频统计程序的包名为test,类名为ScalaSparkDemo。

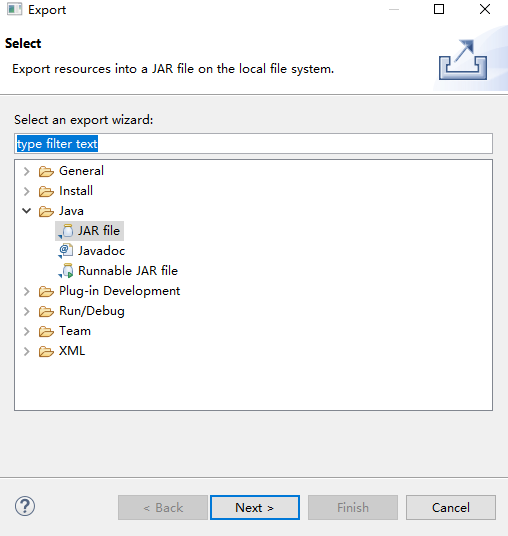
注意这里勾选要打包所依赖的一些文件。当然可以选择把整个工程打包。还要注意这里打包后的文件名为test.jar。

然后上传到Ubuntu中,使用这个命令 bin/spark-submit --class test.ScalaSparkDemo --master local /home/xiaow/test.jar 即可运行。/home/xiaow/test.jar:指明此jar包在主节点上的位置。关于打包到集群的详细命令,可以查阅我的这一篇博客:Spark学习之在集群上运行Spark

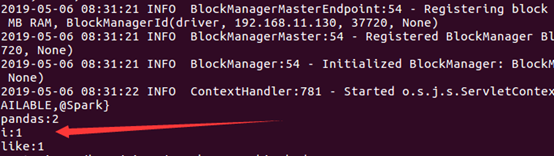
如此,搞定收工!!!
在local模式下的spark程序打包到集群上运行的更多相关文章
- Spark学习之在集群上运行Spark(6)
Spark学习之在集群上运行Spark(6) 1. Spark的一个优点在于可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力. 2. Spark既能适用于专用集群,也可以适用于共享的云计算 ...
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
- Spark学习笔记——在集群上运行Spark
Spark运行的时候,采用的是主从结构,有一个节点负责中央协调, 调度各个分布式工作节点.这个中央协调节点被称为驱动器( Driver) 节点.与之对应的工作节点被称为执行器( executor) 节 ...
- 012 Spark在IDEA中打jar包,并在集群上运行(包括local模式,standalone模式,yarn模式的集群运行)
一:打包成jar 1.修改代码 2.使用maven打包 但是目录中有中文,会出现打包错误 3.第二种方式 4.下一步 5.下一步 6.下一步 7.下一步 8.下一步 9.完成 二:在集群上运行(loc ...
- [MapReduce_add_1] Windows 下开发 MapReduce 程序部署到集群
0. 说明 Windows 下开发 MapReduce 程序部署到集群 1. 前提 在本地开发的时候保证 resource 中包含以下配置文件,从集群的配置文件中拷贝 在 resource 中新建 ...
- [Spark Core] 在 Spark 集群上运行程序
0. 说明 将 IDEA 下的项目导出为 Jar 包,部署到 Spark 集群上运行. 1. 打包程序 1.0 前提 搭建好 Spark 集群,完成代码的编写. 1.1 修改代码 [添加内容,判断参数 ...
- 将java开发的wordcount程序提交到spark集群上运行
今天来分享下将java开发的wordcount程序提交到spark集群上运行的步骤. 第一个步骤之前,先上传文本文件,spark.txt,然用命令hadoop fs -put spark.txt /s ...
- 06、部署Spark程序到集群上运行
06.部署Spark程序到集群上运行 6.1 修改程序代码 修改文件加载路径 在spark集群上执行程序时,如果加载文件需要确保路径是所有节点能否访问到的路径,因此通常是hdfs路径地址.所以需要修改 ...
- spark在集群上运行
1.spark在集群上运行应用的详细过程 (1)用户通过spark-submit脚本提交应用 (2)spark-submit脚本启动驱动器程序,调用用户定义的main()方法 (3)驱动器程序与集群管 ...
随机推荐
- 【CF1142B】Lynyrd Skynyrd
[CF1142B]Lynyrd Skynyrd 题面 洛谷 题解 假设区间\([l,r]\)内有一个循环位移,那么这个循环位移一定有一个最后的点,而这个点在循环位移中再往前移\(n-1\)个位置也一定 ...
- vlc for mac设置中文的方法
VLC for mac是一款mac系统下的多媒体播放器,支持播放MPEG-1.MPEG-2.MPEG-4.DivX.MP3和OGG,以及DVD.VCD.等各种流媒体协议在内的多种协议格式,并且能够对电 ...
- SpringBoot激活profiles
多环境是最常见的配置隔离方式之一,可以根据不同的运行环境提供不同的配置信息来应对不同的业务场景,在SpringBoot内支持了多种配置隔离的方式,可以激活单个或者多个配置文件. 激活Profiles的 ...
- 每天一个命令-cp 命令
cp命令用来将一个或多个源文件或者目录复制到指定的目的文件或目录.它可以将单个源文件复制成一个指定文件名的具体的文件或一个已经存在的目录下.cp命令还支持同时复制多个文件,当一次复制多个文件时,目标文 ...
- ubuntu下Vim安装失败
sudo apt-get install vim Reading package lists... Done Building dependency tree Reading state inform ...
- 【转】Android 将自己的应用改为系统应用
所谓系统程序就是system/app目录中的程序,普通应用转换成系统程序后有稳定.减少内存(DATA)空间占用.恢复出厂设置后不会消失.修改系统时间.调用隐藏方法.系统关机重启.静默安装升级卸载应用等 ...
- [SQL]用于提取组内最新数据,左连接,内连接,not exist三种方案中,到底谁最快?
本作代码下载:https://files.cnblogs.com/files/xiandedanteng/LeftInnerNotExist20191222.rar 人们总是喜欢给出或是得到一个简单明 ...
- crc64
oss2\models.py class PartInfo(object): """表示分片信息的文件. 该文件既用于 :func:`list_parts < ...
- jetty源码下载
jetty下载地址:https://www.eclipse.org/jetty/download.html Release 9.4.20.v20190813 .zip .tgz api ...
- Linux find命令忽略目录的查找方法
在Linux操作系统中,find命令非常强大,在文件与目录的查找方面可谓无所不至其极,如果能结合xargs命令使得,更是强大无比. 以下来看看find命令忽略目录查找的用法吧. 例1,根据文件属性查找 ...