Spark 系列(一)—— Spark简介
一、简介
Spark 于 2009 年诞生于加州大学伯克利分校 AMPLab,2013 年被捐赠给 Apache 软件基金会,2014 年 2 月成为 Apache 的顶级项目。相对于 MapReduce 的批处理计算,Spark 可以带来上百倍的性能提升,因此它成为继 MapReduce 之后,最为广泛使用的分布式计算框架。
二、特点
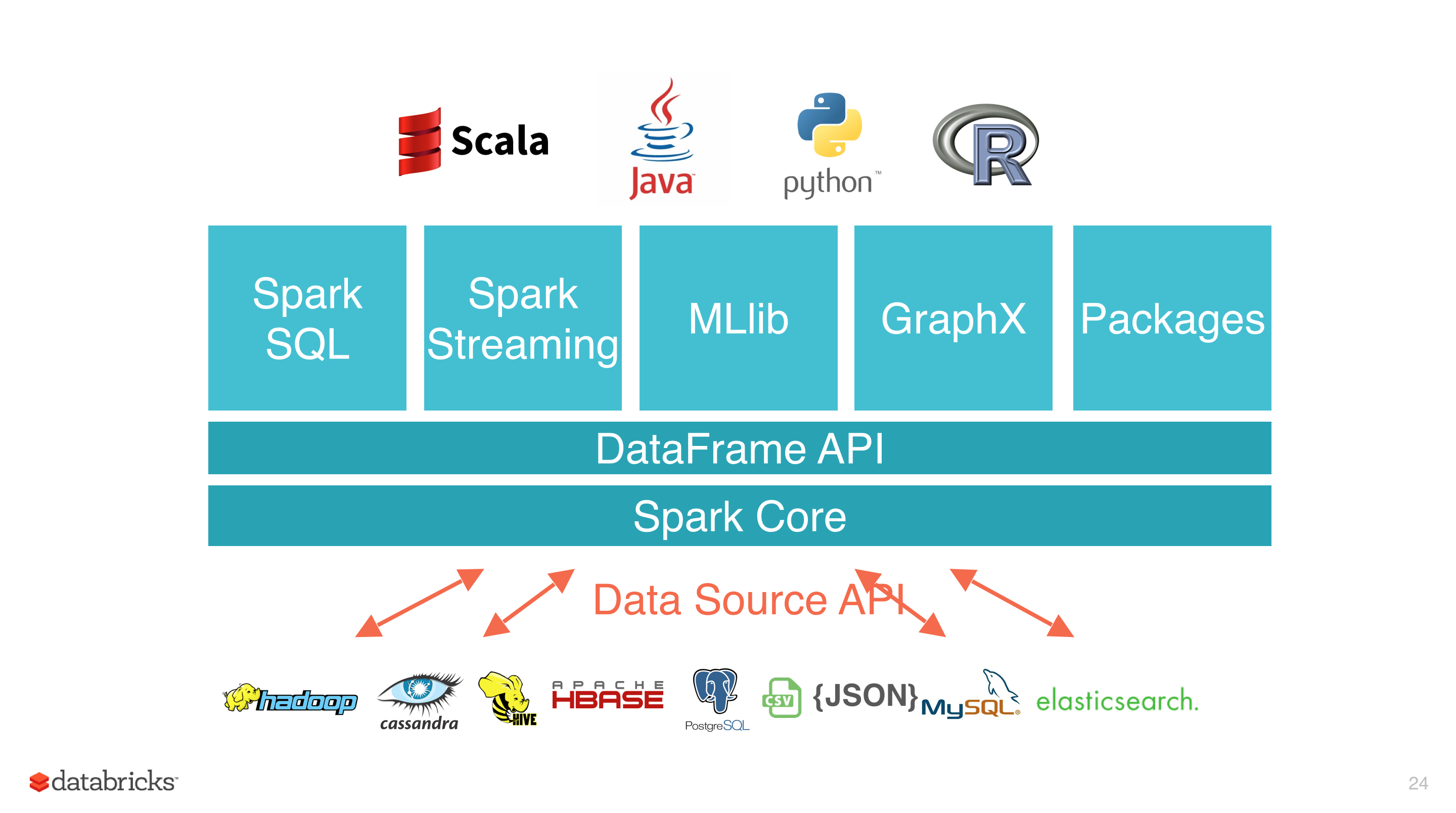
Apache Spark 具有以下特点:
- 使用先进的 DAG 调度程序,查询优化器和物理执行引擎,以实现性能上的保证;
- 多语言支持,目前支持的有 Java,Scala,Python 和 R;
- 提供了 80 多个高级 API,可以轻松地构建应用程序;
- 支持批处理,流处理和复杂的业务分析;
- 丰富的类库支持:包括 SQL,MLlib,GraphX 和 Spark Streaming 等库,并且可以将它们无缝地进行组合;
- 丰富的部署模式:支持本地模式和自带的集群模式,也支持在 Hadoop,Mesos,Kubernetes 上运行;
- 多数据源支持:支持访问 HDFS,Alluxio,Cassandra,HBase,Hive 以及数百个其他数据源中的数据。
三、集群架构
| Term(术语) | Meaning(含义) |
|---|---|
| Application | Spark 应用程序,由集群上的一个 Driver 节点和多个 Executor 节点组成。 |
| Driver program | 主运用程序,该进程运行应用的 main() 方法并且创建 SparkContext |
| Cluster manager | 集群资源管理器(例如,Standlone Manager,Mesos,YARN) |
| Worker node | 执行计算任务的工作节点 |
| Executor | 位于工作节点上的应用进程,负责执行计算任务并且将输出数据保存到内存或者磁盘中 |
| Task | 被发送到 Executor 中的工作单元 |
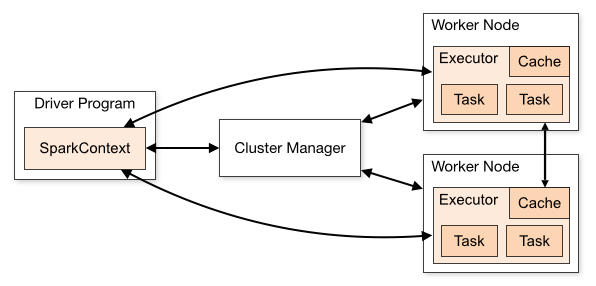
执行过程:
- 用户程序创建 SparkContext 后,它会连接到集群资源管理器,集群资源管理器会为用户程序分配计算资源,并启动 Executor;
- Dirver 将计算程序划分为不同的执行阶段和多个 Task,之后将 Task 发送给 Executor;
- Executor 负责执行 Task,并将执行状态汇报给 Driver,同时也会将当前节点资源的使用情况汇报给集群资源管理器。
四、核心组件
Spark 基于 Spark Core 扩展了四个核心组件,分别用于满足不同领域的计算需求。
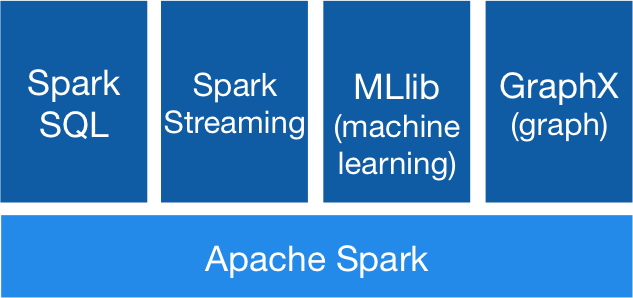
3.1 Spark SQL
Spark SQL 主要用于结构化数据的处理。其具有以下特点:
- 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 DataFrame API 对结构化数据进行查询;
- 支持多种数据源,包括 Hive,Avro,Parquet,ORC,JSON 和 JDBC;
- 支持 HiveQL 语法以及用户自定义函数 (UDF),允许你访问现有的 Hive 仓库;
- 支持标准的 JDBC 和 ODBC 连接;
- 支持优化器,列式存储和代码生成等特性,以提高查询效率。
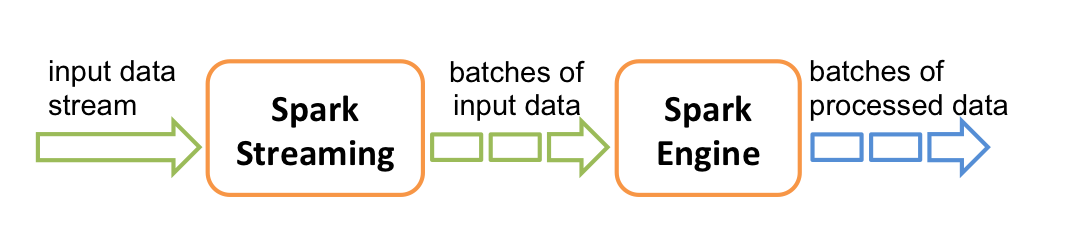
3.2 Spark Streaming
Spark Streaming 主要用于快速构建可扩展,高吞吐量,高容错的流处理程序。支持从 HDFS,Flume,Kafka,Twitter 和 ZeroMQ 读取数据,并进行处理。

Spark Streaming 的本质是微批处理,它将数据流进行极小粒度的拆分,拆分为多个批处理,从而达到接近于流处理的效果。
3.3 MLlib
MLlib 是 Spark 的机器学习库。其设计目标是使得机器学习变得简单且可扩展。它提供了以下工具:
- 常见的机器学习算法:如分类,回归,聚类和协同过滤;
- 特征化:特征提取,转换,降维和选择;
- 管道:用于构建,评估和调整 ML 管道的工具;
- 持久性:保存和加载算法,模型,管道数据;
- 实用工具:线性代数,统计,数据处理等。
3.4 Graphx
GraphX 是 Spark 中用于图形计算和图形并行计算的新组件。在高层次上,GraphX 通过引入一个新的图形抽象来扩展 RDD(一种具有附加到每个顶点和边缘的属性的定向多重图形)。为了支持图计算,GraphX 提供了一组基本运算符(如: subgraph,joinVertices 和 aggregateMessages)以及优化后的 Pregel API。此外,GraphX 还包括越来越多的图形算法和构建器,以简化图形分析任务。
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Spark 系列(一)—— Spark简介的更多相关文章
- Spark系列—02 Spark程序牛刀小试
一.执行第一个Spark程序 1.执行程序 我们执行一下Spark自带的一个例子,利用蒙特·卡罗算法求PI: 启动Spark集群后,可以在集群的任何一台机器上执行一下命令: /home/spark/s ...
- Spark系列—01 Spark集群的安装
一.概述 关于Spark是什么.为什么学习Spark等等,在这就不说了,直接看这个:http://spark.apache.org, 我就直接说一下Spark的一些优势: 1.快 与Hadoop的Ma ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- 小白学习Spark系列一:Spark简介
由于最近在工作中刚接触到scala和Spark,并且作为python中毒者,爬行过程很是艰难,所以这一系列分为几个部分记录下学习<Spark快速大数据分析>的知识点以及自己在工程中遇到的小 ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark 系列(八)—— Spark SQL 之 DataFrame 和 Dataset
一.Spark SQL简介 Spark SQL 是 Spark 中的一个子模块,主要用于操作结构化数据.它具有以下特点: 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 Da ...
- Spark 系列(十三)—— Spark Streaming 与流处理
一.流处理 1.1 静态数据处理 在流处理之前,数据通常存储在数据库,文件系统或其他形式的存储系统中.应用程序根据需要查询数据或计算数据.这就是传统的静态数据处理架构.Hadoop 采用 HDFS 进 ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark系列-核心概念
Spark系列-初体验(数据准备篇) Spark系列-核心概念 一. Spark核心概念 Master,也就是架构图中的Cluster Manager.Spark的Master和Workder节点分别 ...
随机推荐
- javascript 之正则表达式匹配不包含特定字符串的字符
如:有如下字符串,想查出不包含min.js的字符串 ['xx.min.js','xx.js','x.js','x.min.js'] 方法一: 使用逻辑非判断, !/min\.js/.test(str ...
- 利用vue-meta管理头部标签
在 Vue SPA 应用中,如果想要修改HTML的头部标签,或许,你会在代码里,直接这么做 // 改下title document.title = 'what?' // 引入一段script let ...
- 【2019.12.11】SDN上机第7次作业
打开P4的目录,运行主程序 make run 此时输入命令 pingall 会显示所有的网络不通 改为下方代码 /* -*- P4_16 -*- */ #include <core.p4> ...
- kms windows激活
Microsoft KMS Activation Usage Start a Command Prompt as an Administrator. Windows slmgr.vbs -upk sl ...
- 【软工实践】Beta冲刺(1/5)
链接部分 队名:女生都队 组长博客: 博客链接 作业博客:博客链接 小组内容 恩泽(组长) 过去两天完成了哪些任务 描述 登陆注册.查看用户信息.添加用户任务.查看任务等API的完善 tomcat的学 ...
- Vintage、滚动率、迁移率的应用
python信用评分卡建模(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_ca ...
- Buffon投针问题
- Oracle系列五 多表查询
笛卡尔集笛卡尔集会在下面条件下产生: 省略连接条件 连接条件无效 所有表中的所有行互相连接 为了避免笛卡尔集, 可以在 WHERE 加入有效的连接条件. Oracle 连接 使用连接在多个表中查询数据 ...
- C++11:基于std::queue和std::mutex构建一个线程安全的队列
C++11:基于std::queue和std::mutex构建一个线程安全的队列 C++中的模板std::queue提供了一个队列容器,但这个容器并不是线程安全的,如果在多线程环境下使用队列,它是不能 ...
- PAT 甲级 1074 Reversing Linked List (25 分)(链表部分逆置,结合使用双端队列和栈,其实使用vector更简单呐)
1074 Reversing Linked List (25 分) Given a constant K and a singly linked list L, you are supposed ...