Batch Normalization 引出的一系列问题
Batch Normalization,拆开来看,第一个单词意思是批,出现在梯度下降的概念里,第二个单词意思是标准化,出现在数据预处理的概念里。
我们先来看看这两个概念。
数据预处理
方法很多,后面我会在其他博客中专门讲,这里简单回忆下
归一化,x-min/max-min,
标准化,包括标准差标准化,x-mean/std,极差标准化,x-mean/(max-min),
中心化,x-mean,
白化,pac-->归一化
梯度下降
梯度下降中 mini batch sgd 是比 sgd 更好的一种方法,因为min batch是平均梯度,使得梯度更平稳,容易收敛,而且batch能够并行计算,减少运算。
我们知道,在机器学习中,梯度下降是要归一化的,因为如果不归一化,y在各个维度上的量纲不一样,使得y的图形不规则,扁平或者瘦高,这样在求梯度时经常会歪歪曲曲,一般会陷入局部最优。
图示如下
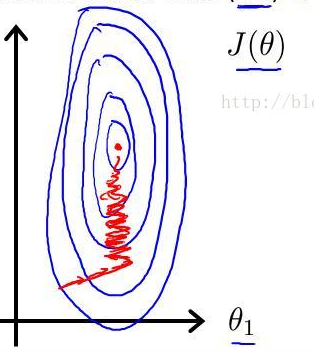
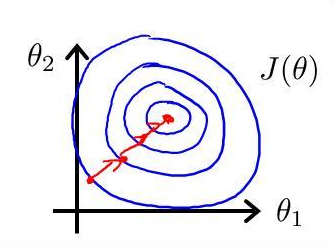
神经网络也是用的梯度下降,从这点来看,也是需要数据预处理的。
独立同分布 IID
在机器学习中有这个概念,意思是训练数据和测试数据需要服从同样的分布,这样才有意义,很好理解。
但是在深度学习中,训练和测试都是图片(cnn为例,图片为例),似乎不牵扯IID。
那这根batch normalization 有什么关系呢?
因为在神经网络中有层的概念,每一层都有输入,每一层的输入是上一层的输出,而输出是经过非线性函数的,非线性函数的取值都有特定的区间,这就和原始的输入在数据分布上存在很大不同,
此时需要用一定的方法统一数据分布。
神经网络的训练问题
神经网络层数越深,越是难以训练,收敛速度越来越慢,为什么呢?下面我以sigmoid函数为例简要说明。(后面我会专门写一篇激活函数的博客,详细阐述)
在数学建模时一般会要求样本服从正态分布,正态分布标准化后就是标准正态分布。图像如下

可以看到标准正态分布95%的概率落在 [-2, 2] 之间
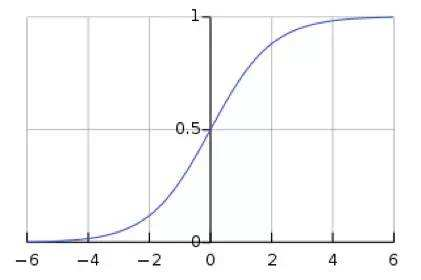
sigmoid 函数的特点是在绝大多数x上(除了-2到2的区间)取值要么无限接近于1,要么无限接近于0,而且,这种情况下其梯度无限接近于0,这就是神经网络梯度消息的本质,这也是sigmoid函数很难作为深度神经网络的激活函数的原因。
而 batch normalization 的作用是把x规范到0附近,此时其梯度很大,收敛很快。
scale and shift
batch normalization 虽然增加了梯度,但是同时我们发现,当x在0附近时,其函数非常接近于线性,这大大降低了模型的表达能力。
为了解决这个问题,作者又提出了 scale and shift,即y=scale*x+shift,这相当于是把数据从0向左或向右平移了一段并拉伸或压缩,使得y处于线性和非线性的交界处,这样既保证了较大的梯度,也保留了模型的非线性表达能力。
scale 和 shift 通过训练学习到。
到这基本就讲完 batch normalization 的原理了,下面看看具体怎么使用。
使用方法
之前讲到batch normalization使得神经网络每一层的输入变得规范,也就是说它是把 wx+b 变得规范,即用在线性变换之后,非线性变换之前。如图

总体计算方法如下

这里在标准化时分母加了个ε,是防止分母为0。
总结
batch normalization的优点
1. 提高神经网络的训练效率,避免梯度消失
2. 使得神经网络不依赖于初始值,方便调参
3. 抑制过拟合,降低dropout的使用,提高泛化能力
batch normalization的缺点
1. batch normalization 仍然有很多地方科学理论无法解释
2. batch大小对其效果影响很大,batch 很小时,其梯度不够稳定,收敛变慢,极端情况就是 sgd
参考资料:
https://www.cnblogs.com/guoyaohua/p/8724433.html
https://www.zhihu.com/question/38102762
https://blog.csdn.net/whitesilence/article/details/75667002
https://blog.csdn.net/liangjiubujiu/article/details/80977502
Batch Normalization 引出的一系列问题的更多相关文章
- 神经网络之 Batch Normalization
知乎 csdn Batch Normalization 学习笔记 原文地址:http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce ...
- 图像分类(二)GoogLenet Inception_v2:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Inception V2网络中的代表是加入了BN(Batch Normalization)层,并且使用 2个 3*3卷积替代 1个5*5卷积的改进版,如下图所示: 其特点如下: 学习VGG用2个 3* ...
- 转载-通俗理解BN(Batch Normalization)
转自:参数优化方法 1. 深度学习流程简介 1)一次性设置(One time setup) -激活函数(Activation functions) - 数据预处理(Data Prep ...
- 《RECURRENT BATCH NORMALIZATION》
原文链接 https://arxiv.org/pdf/1603.09025.pdf Covariate 协变量:在实验的设计中,协变量是一个独立变量(解释变量),不为实验者所操纵,但仍影响实验结果. ...
- 【转载】 详解BN(Batch Normalization)算法
原文地址: http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce ------------------------------- ...
- Tensorflow BatchNormalization详解:4_使用tf.nn.batch_normalization函数实现Batch Normalization操作
使用tf.nn.batch_normalization函数实现Batch Normalization操作 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 吴恩达deeplearnin ...
- Batch Normalization 详解
一.背景意义 本篇博文主要讲解2015年深度学习领域,非常值得学习的一篇文献:<Batch Normalization: Accelerating Deep Network Training b ...
- Batch Normalization详解
目录 动机 单层视角 多层视角 什么是Batch Normalization Batch Normalization的反向传播 Batch Normalization的预测阶段 Batch Norma ...
- 深度学习(二十九)Batch Normalization 学习笔记
Batch Normalization 学习笔记 原文地址:http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce 一.背景意义 ...
随机推荐
- 宿主iis部署wcf
WCF学习笔记(4)——宿主iis部署wcf 本文将部署一个wcf+silverlight简单实例,以下是详细步骤: (环境:服务端win2003,iis6.0,asp.net4.0:客户端winXP ...
- Apache Hadoop Operations at Scale
book: Hadoop Operations,A Guide for Developers and Administrators Apache Hadoop Operations at Scale ...
- 胜利大逃亡 HDU - 1253
Ignatius被魔王抓走了,有一天魔王出差去了,这可是Ignatius逃亡的好机会. 魔王住在一个城堡里,城堡是一个A*B*C的立方体,可以被表示成A个B*C的矩阵,刚开始Ignatius被关在(0 ...
- 20165309 技能学习经验与C语言
技能学习经验与C语言 技能学习经验 你有什么技能比大多人(超过90%以上)更好?针对这个技能的获取你有什么成功的经验?与老师博客中的学习经验有什么共通之处? 从小到大,或是出于兴趣.或是出于父母的要求 ...
- 『计算机视觉』Mask-RCNN_项目文档翻译
基础介绍 项目地址:Mask_RCNN 语言框架:Python 3, Keras, and TensorFlow Python 3.4, TensorFlow 1.3, Keras 2.0.8 其他依 ...
- ireport部署到Linux服务器上遇到的问题解决
ireport报表在本地Windows环境运行正常,一旦部署到Linux环境上出现了如下问题: 1.打开报表,后台直接报net.sf.jasperreports.engine.util.JRFontN ...
- oracle数据库中字符乱码
1.1 88.152 os已安装中文包,以下确认os层面中文是否可以显示 1.2 88.153 os没有安装中文包,以下确认os层面中文无法显示 1.3 ...
- 跳转到页面的某个anchor
var loc = document.location.toString().split('#')[0]; document.location = loc + '#' + anchor;
- Linux中环境变量文件
一.环境变量文件介绍 转自:http://blog.csdn.net/cscmaker/article/details/7261921 Linux中环境变量包括系统级和用户级,系统级的环境变量是每个登 ...
- java redis client jedis 测试及常用命令
package cn.byref.demo1; import java.util.HashMap;import java.util.List;import java.util.Map;import j ...