机器学习之寻找KMeans的最优K
K-Means聚类算法是最为经典的,同时也是使用最为广泛的一种基于划分的聚类算法,它属于基于距离的无监督聚类算法。KMeans算法简单实用,在机器学习算法中占有重要的地位。对于KMeans算法而言,如何确定K值,确实让人头疼的事情。
最近这几天一直忙于构建公司的推荐引擎。对用户群体的分类,要使用KMeans聚类算法,就研究了一下。
探索K的选择
对数据进行分析之前,采用一些探索性分析手段还是很有必要的。
对于高维空间,我们可以采用降维的方式,把多维向量转化为二维向量。好在,R语言包里提供了具体的实现,MDS是个比较好的方式。
多维标度分析(MDS)是一种将多维空间的研究对象简化到低维空间进行定位、分析和归类,同时又保留对象间原始关系的数据分析方法。R语言包提供了经典MDS和非度量MDS。
通过MDS对数据进行处理后,采用ggplot绘出点图,看看数据分布的情况,使得我们对要聚类的数据有个直观的认识。
SSE和Silhouette Coefficient系数
我们还可以通过SSE和Silhouette Coefficient系数的方法评估最优K。譬如对K从1到15计算不同的聚类的SSE,由于kmeans算法中的随机因数,每次结果都不一样,为了减少时间结果的偶然性,对于每个k值,都重复运行50次,求出平均的SSE,最后绘制出SSE曲线。Silhouette Coefficient也采用同样做法。
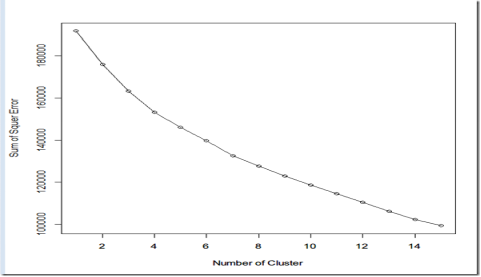
SSE结果
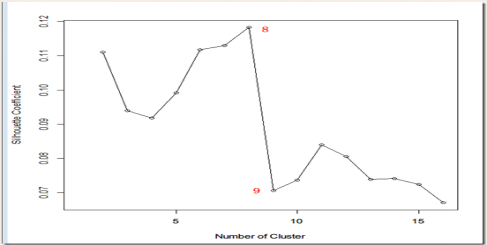
Silhouette Coefficient结果
从上图来看,8和9明显有一个尖峰。我们大体可以确定K的数目是8。值得注意在有些时候,这种方法有可能无效,但仍然不失为一个很好的方法。
DB INDEX准则
DB INdex准则全称Davies Bouldin index 。类内离散度和类间聚类常被用来判断聚类的有效性,DB INdex准则同时使用了类间聚类和类内离散度。通过计算这个指数,来确定到底哪个Cluster最合理

R语言代码如下:
data <- read.csv("a.csv", header = T,
stringsAsFactors = F)
DB_index <- function(x, cl, k) {
data <- split.data.frame(x, cl$cluster)
# 计算类内离散度
S <- NULL
for (i in 1:k) {
S[i] <- sum(rowSums((data[[i]] - cl$centers[i])^2))/nrow(data[[i]])
}
# 计算类间聚类
D <- as.matrix(dist(cl$centers))
# 计算DB index
R <- NULL
for (i in 1:k) {
R <- c(max((S[i] + S[-i])/D[-i, i]), R)
}
DB <- sum(R)/k
return(DB)
}
# 循环计算不同聚类数的DB_Index指数
DB <- NULL
for (i in 2:15) {
cl <- kmeans(data, i)
DB <- c(DB_index(data, cl, i), DB)
}
plot(2:15, DB)
lines(2:15, DB)
CANOPY算法
Canopy聚类最大的特点是不需要事先指定k值(即clustering的个数),与其他聚类算法相比,Canopy聚类虽然精度较低,但其在速度上有很大优势。
因此可以使用Canopy聚类先对数据进行“粗”聚类,得到k值后再使用K-means进行进一步“细”聚类。这个算法不多说了,mahout聚类里有具体实现。
参阅:https://en.wikipedia.org/wiki/Davies-Bouldin_index
机器学习之寻找KMeans的最优K的更多相关文章
- 机器学习中的K-means算法的python实现
<机器学习实战>kMeans算法(K均值聚类算法) 机器学习中有两类的大问题,一个是分类,一个是聚类.分类是根据一些给定的已知类别标号的样本,训练某种学习机器,使它能够对未知类别的样本进行 ...
- 机器学习实战之K-Means算法
一,引言 先说个K-means算法很高大上的用处,来开始新的算法学习.我们都知道每一届的美国总统大选,那叫一个竞争激烈.可以说,谁拿到了各个州尽可能多的选票,谁选举获胜的几率就会非常大.有人会说,这跟 ...
- 【转】机器学习实战之K-Means算法
一,引言 先说个K-means算法很高大上的用处,来开始新的算法学习.我们都知道每一届的美国总统大选,那叫一个竞争激烈.可以说,谁拿到了各个州尽可能多的选票,谁选举获胜的几率就会非常大.有人会说,这跟 ...
- 寻找数组中的第K大的元素,多种解法以及分析
遇到了一个很简单而有意思的问题,可以看出不同的算法策略对这个问题求解的优化过程.问题:寻找数组中的第K大的元素. 最简单的想法是直接进行排序,算法复杂度是O(N*logN).这么做很明显比较低效率,因 ...
- kNN处理iris数据集-使用交叉验证方法确定最优 k 值
基本流程: 1.计算测试实例到所有训练集实例的距离: 2.对所有的距离进行排序,找到k个最近的邻居: 3.对k个近邻对应的结果进行合并,再排序,返回出现次数最多的那个结果. 交叉验证: 对每一个k,使 ...
- poj2114 寻找树上存在长度为k点对,树上的分治
寻找树上存在长度为k点对,树上的分治 代码和 这个 差不多 ,改一下判断的就好 #include <iostream> #include <algorithm> #inc ...
- 【最优K叉树】hdu 5884 Sort
http://acm.hdu.edu.cn/showproblem.php?pid=5884 参考:https://www.cnblogs.com/jhz033/p/5879452.html [题意] ...
- 寻找链表的倒数第k个节点
寻找链表的倒数第k个节点 题目:已知一个带有表头结点的单链表,节点结构为(data,next),假设该链表只给出了头指针list.在不改变链表的前提下,请设计一个尽可能高效的算法,查找链表中倒数第k个 ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
随机推荐
- 1.羽翼sqlmap学习笔记之Access注入
使用sqlmap工具进行Acces注入:1.判断一个url是否存在注入点,根据返回数据判断数据库类型: .sqlmap.py -u "http://abcd****efg.asp?id=7& ...
- 在SQL Serve里停用行和页层级锁
今天我想谈下SQL Server里另一个非常有趣的话题:在SQL Server里停用行和页层级锁.在SQL Server里,每次你重建一个索引,你可以使用ALLOW_ROW_LOCKS 和ALLOW_ ...
- MS SQL Server 数据库分离-SQL语句
前言 今天在在清理数据库,是MS SQL Server,其中用到分离数据库文件.在这过程中,出现了一个小小的问题:误将数据库日志文件删除了,然后数据就打不开了,除了脱机,其他操作都报错. 数据库分离 ...
- 【Win10开发】自定义标题栏
UWP 现在已经可以自定义标题栏了,毕竟看灰色时间长了也会厌烦,开发者们还是希望能够将自己的UI做的更加漂亮,更加与众不同.那么废话不多说,我们开始吧! 首先要了解ApplicationViewTit ...
- Python获取中国证券报最新资讯
# -*- coding: utf-8 -*- import urllib from bs4 import BeautifulSoup from time import time from time ...
- 关于An association from the table refers to an unmapped class
今天配置SSH框架的时候出现这个异常,找了很久,才发现原来是是实体类映射文件中的<class name="Role" table="role">的n ...
- 关于Lind.DDD.Api客户端的使用与知识分享
回到目录 关于Lind.DDD.Api的使用与客户端的调用 作者:张占岭 花名:仓储大叔 框架:Lind.DDD,Lind.DDD.Api 目录 Api里注册全局校验特性 1 Api中设置全局的Cor ...
- GJM :SqlServer语言学习笔记
----------------------------SqlServer RDBMS 关系型数据库管理系统 Row/Record 行 Colimn/Attribute 列 Field/Cell 字段 ...
- SQL注入—我是如何一步步攻破一家互联网公司的
最近在研究Web安全相关的知识,特别是SQL注入类的相关知识.接触了一些与SQL注入相关的工具.周末在家闲着无聊,想把平时学的东东结合起来攻击一下身边某个小伙伴去的公司,看看能不能得逞.不试不知道,一 ...
- Managing database evolutions
When you use a relational database, you need a way to track and organize your database schema evolut ...